各製品の資料を入手。
詳細はこちら →



製品をチェック
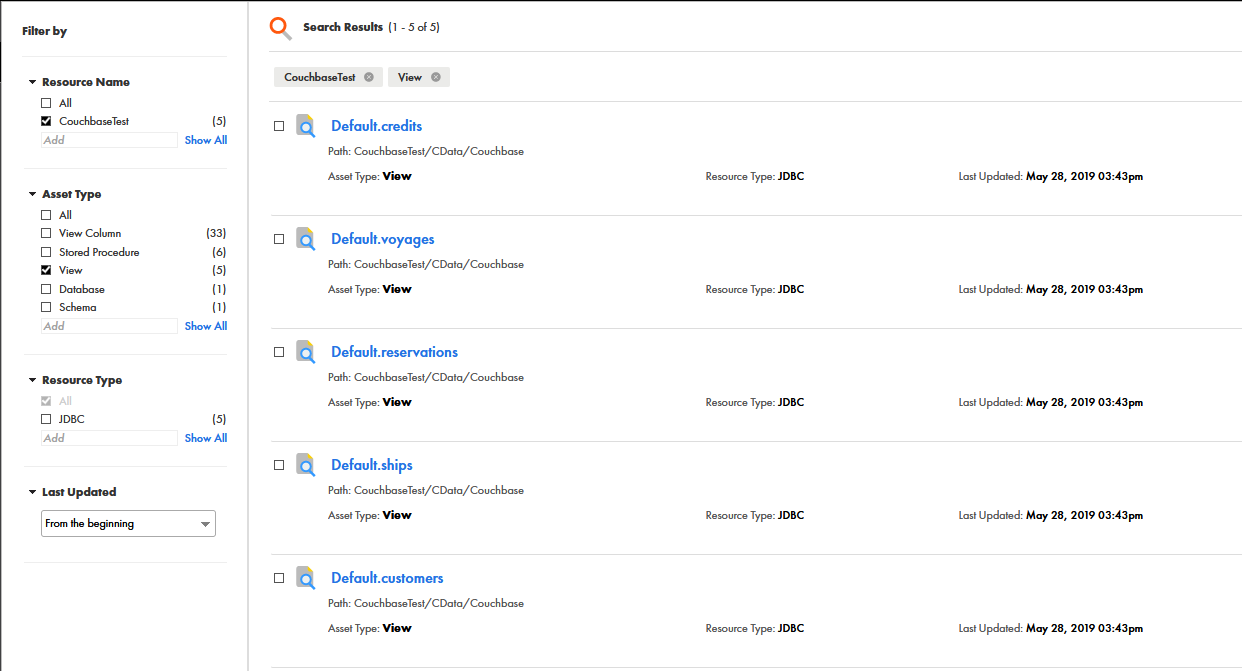
Informatica Enterprise Data Catalog にSQL Analysis Services のデータを追加
CData JDBC Driver をInformatica Enterprise Data Catalog とともに用いて、データを分類・整理します。
最終更新日:2021-11-02
この記事で実現できるSQL Analysis Services 連携のシナリオ


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Informatica は、データを転送・変換するための強力で立派な手段を提供します。CData JDBC Driver for SSAS を利用することで、Informatica のEnterprise Data Catalog とシームレスに統合される、業界で実証済みの標準に基づくドライバーにアクセスできます。このチュートリアルでは、どんな環境でもSQL Analysis Services のデータを分類・整理する方法を説明します。
JDBC ドライバーをロード
以下はJDBC ドライバーをロードする方法です。
- Informatica を実行しているホストにJDBC ドライバーをインストールします。この記事では、ドライバーがcdata.jdbc.ssas.SSAS Driver にインストールされていることを前提としています。
- JDBC インストールディレクトリに移動して、genericJDBC.zip と呼ばれ、ドライバーとそのライセンスファイルを含むzip ファイルを作成します。
- genericJDBC.zip ファイルをInformatica 内のCatalog Service ディレクトリに移動します。この記事では、ドライバーが/opt/informatica にインストールされていることを前提としています。 このフォルダでの作業には、root 権限が必要になるおそれがあるため、続行する前にroot に必ずsu または sudo を実行してください。
- カスタムデプロイメント構成を編集し、zip ファイルを解凍します。
- アドミニストレーションコンソールから、Catalog Service を更新します。
$ java -jar setup.jar
$ cd ~/cdata-jdbc-driver-for-ssas/lib
$ zip genericJDBC.zip cdata.jdbc.ssas.jar cdata.jdbc.ssas.lic
# mv genericJDBC.zip /opt/informatica/services/CatalogService/ScannerBinaries
# cd /opt/informatica/services/CatalogService/ScannerBinaries/CustomDeployer/
# nano scannerDeployer.xml
既存のExecutionContextProperty ノードを解凍したら、このコンテンツを含む新しいExecutionContextProperty ノードを追加します。
<ExecutionContextProperty
isLocationProperty="true"
dependencyToUnpack="genericJDBC.zip">
<PropertyName>JDBCScanner_DriverLocation</PropertyName>
<PropertyValue>scanner_miti/genericJDBC/Drivers</PropertyValue>
</ExecutionContextProperty>
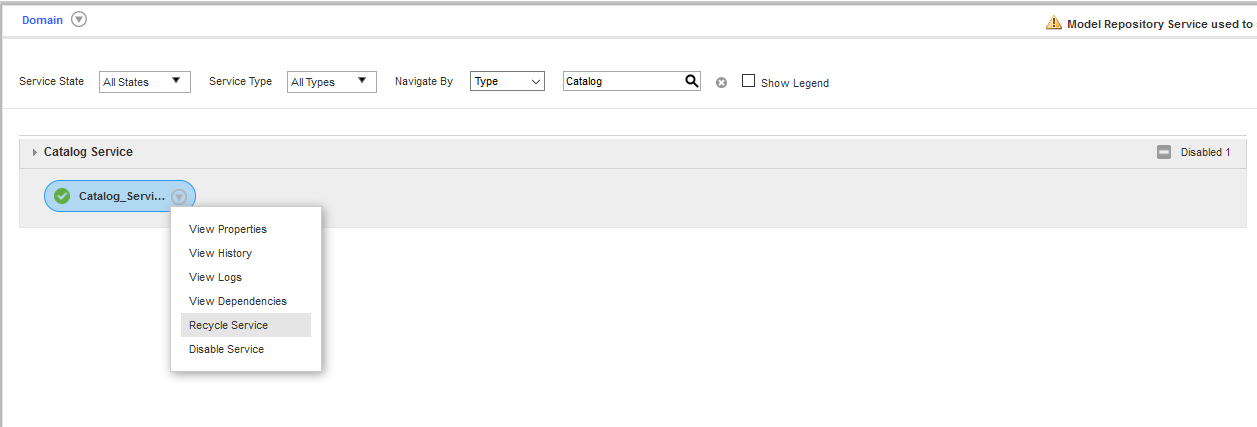
JDBC リソースの構成
以下の手順でJDBC リソースを構成します。
- Catalog のアドミニストレーターを開き、次のプロパティを持つ新しいJDBC リソースを追加します。
- Driver Class: cdata.jdbc.ssas.SSASDriver
- URL:
jdbc.ssas:User=myuseraccount;Password=mypassword;URL=http://localhost/OLAP/msmdpump.dll; -
HTTP 認証
AuthScheme を"Basic" または"Digest" に設定してUser とPassword を設定します。CustomHeaders に他の認証値を指定します。
-
Windows (NTLM)
Windows のUser とPassword を設定して、AuthScheme をNTLM に設定します。
-
Kerberos およびKerberos Delegation
Kerberos を認証するには、AuthScheme をNEGOTIATE に設定します。Kerberos 委任を使うには、AuthScheme をKERBEROSDELEGATION に設定します。必要があれば、User、Password およびKerberosSPN を設定します。デフォルトでは、CData 製品は指定されたUrl でSPN と通信しようと試みます。
-
SSL/TLS:
デフォルトでは、CData 製品はサーバーの証明書をシステムの信頼できる証明書ストアと照合してSSL/TLS のネゴシエーションを試みます。別の証明書を指定するには、利用可能なフォーマットについてヘルプドキュメントの「SSLServerCert」プロパティを参照してください。
- ユーザー名: user
- パスワード: password
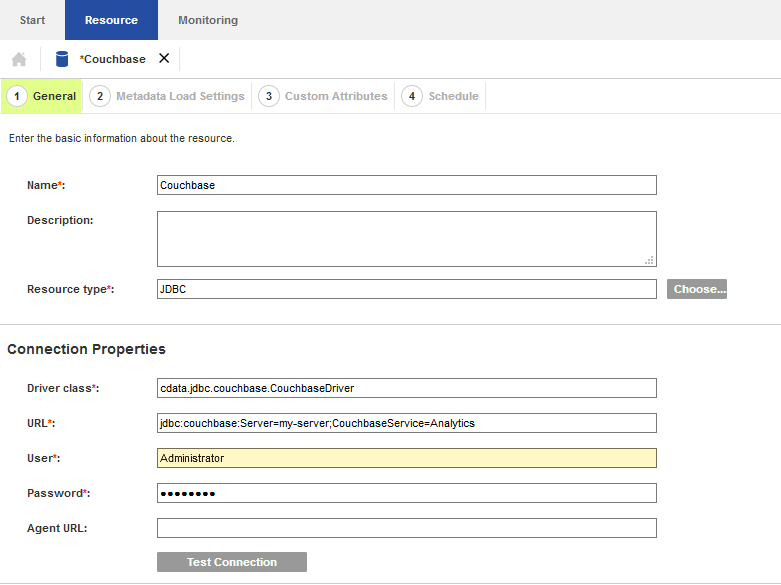
- 少なくとも一つのソースメタデータスキャンを実行するようにメタデータオプションを構成します。このスキャンではドライバーを使用し、サービスを通じて使用できるテーブル、ビュー、ストアドプロシージャを判別します。
- Source Metadata: このオプションを有効にする。
- Catalog: これをマルチカタログデータソースの適切なカタログに設定します。もしくは、CData に設定します。
- Schema: これをマルチスキーマデータソースの適切なスキーマに設定します。もしくは、これをサービスの名前に設定します。(以下ではCouchbase)
- Case-sensitivity: 通常このオプションは無効にします。大文字と小文字が区別されるデータソースに対してのみ有効にしてください。
- Import stored procedures: テーブルとビューに加え、ストアドプロシージャディフィニションをインポートする場合は、これを有効にします。
- ドライバーの構成を完了し、オプションでカスタム属性とスキャナースケジュールを構成します。
- [Monitoring]タブに移動し[Run]をクリックしてメタデータスキャンを実行します。データソースによっては、これに数分かかる場合があります。
接続するには、Url プロパティを有効なSQL Server Analysis Services エンドポイントに設定して認証を提供します。XMLA アクセスを使用して、HTTP 経由でホストされているSQL Server Analysis Services インスタンスに接続できます。 Microsoft ドキュメント configure HTTP access を参照してSQL Server Analysis Services に接続してください。
SQL をSQL Server Analysis Services に実行するには、ヘルプドキュメントの「Analysis Services データの取得」を参照してください。接続ごとにメタデータを取得する代わりに、CacheLocation を設定できます。
接続を設定したら、その後はあらゆるキューブを二次元テーブルとして扱うことができます。データに接続する際にCData 製品がSSAS のメタデータを取得して、動的にテーブルスキーマを更新します。 「CacheLocation」プロパティを設定すれば自動でファイルにキャッシュを作成するので、接続時に毎回メタデータを取得する必要もなくなります。
詳細は、ヘルプドキュメントの「Retrieving Analysis Services Data」を参照してください。
ビルトイン接続文字列デザイナ
JDBC URL の構成については、SQL Analysis Services JDBC Driver に組み込まれている接続文字列デザイナを使用してください。.jar ファイルのダブルクリック、またはコマンドラインから.jar ファイルを実行します。
java -jar cdata.jdbc.ssas.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
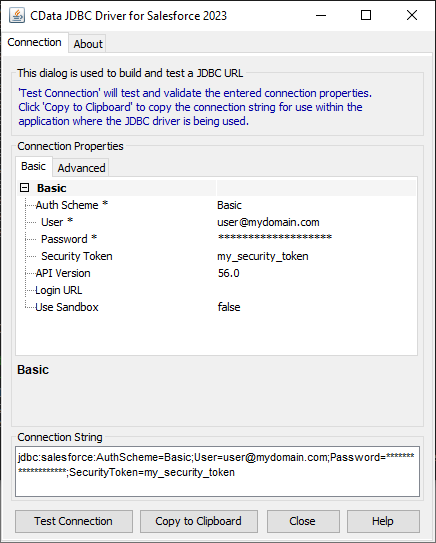
JDBC URL を構成する際に、Max Rows プロパティを定めることも可能です。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は、一般的な追加の接続文字列プロパティです。
JDBC;MSTR_JDBC_JAR_FOLDER=PATH\TO\JAR\;DRIVER=cdata.jdbc.ssas.SSASDriver;URL={jdbc:ssas:User=myuseraccount;Password=mypassword;URL=http://localhost/OLAP/msmdpump.dll;};
使用しているドライバーに要求されなくても、ユーザー名とパスワードのプロパティは必須であることに注意してください。そのようなケースでは、代わりにプレスホルダー値を入力できます。
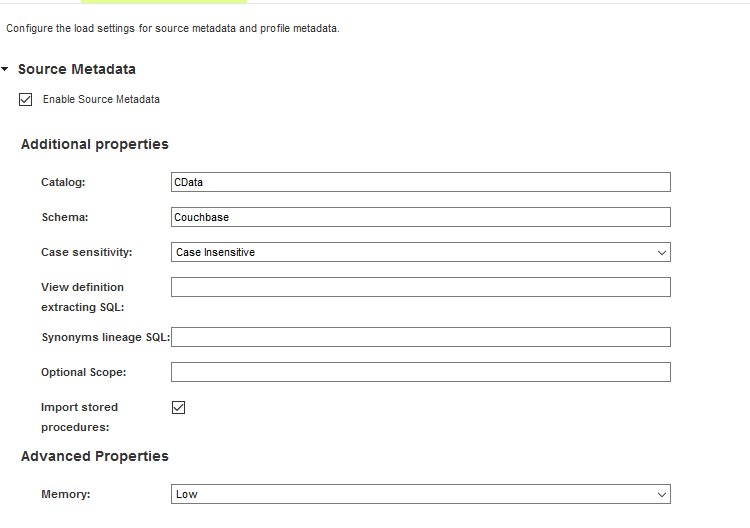
他のメタデータスキャナーは、必要に応じて有効にすることができます。
スキャンが完了すると、すべてのメタデータオブジェクトの概要が[Metadata Load job]のステータスとともに表示されます。エラーが発生した場合、[Log Location]リンクを開き、インフォマティカまたはドライバーから報告されたエラーを確認できます。
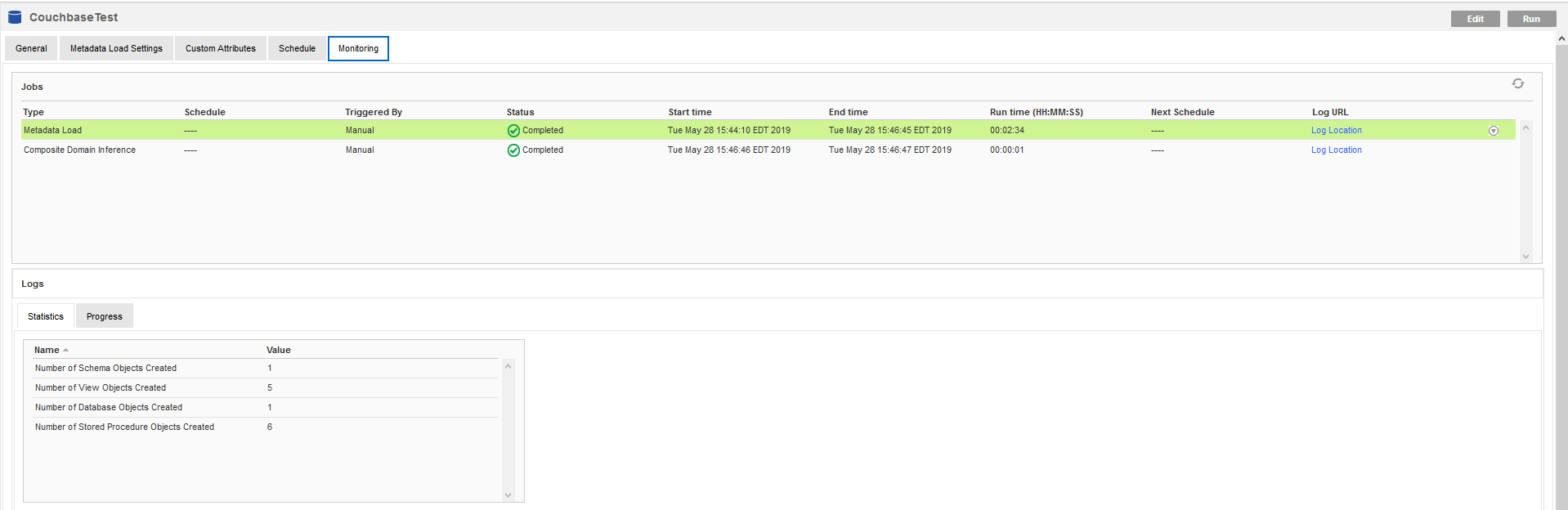
検出されたメタデータを検証
[Catalog Service]を開き、データソースから検出されたメタデータを表示します。メタデータスキャナーの構成時に選択したオプションによっては、定義したリソースのテーブル、ビュー、ストアドプロシージャの任意の組み合わせが表示される場合があります。