各製品の資料を入手。
詳細はこちら →



製品をチェック
Informatica Enterprise Data Catalog にNetSuite のデータを追加
CData JDBC Driver をInformatica Enterprise Data Catalog とともに用いて、データを分類・整理します。
最終更新日:2021-11-02
この記事で実現できるNetSuite 連携のシナリオ


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Informatica は、データを転送・変換するための強力で立派な手段を提供します。CData JDBC Driver for NetSuite を利用することで、Informatica のEnterprise Data Catalog とシームレスに統合される、業界で実証済みの標準に基づくドライバーにアクセスできます。このチュートリアルでは、どんな環境でもNetSuite のデータを分類・整理する方法を説明します。
JDBC ドライバーをロード
以下はJDBC ドライバーをロードする方法です。
- Informatica を実行しているホストにJDBC ドライバーをインストールします。この記事では、ドライバーがcdata.jdbc.netsuite.NetSuite Driver にインストールされていることを前提としています。
- JDBC インストールディレクトリに移動して、genericJDBC.zip と呼ばれ、ドライバーとそのライセンスファイルを含むzip ファイルを作成します。
- genericJDBC.zip ファイルをInformatica 内のCatalog Service ディレクトリに移動します。この記事では、ドライバーが/opt/informatica にインストールされていることを前提としています。 このフォルダでの作業には、root 権限が必要になるおそれがあるため、続行する前にroot に必ずsu または sudo を実行してください。
- カスタムデプロイメント構成を編集し、zip ファイルを解凍します。
- アドミニストレーションコンソールから、Catalog Service を更新します。
$ java -jar setup.jar
$ cd ~/cdata-jdbc-driver-for-netsuite/lib
$ zip genericJDBC.zip cdata.jdbc.netsuite.jar cdata.jdbc.netsuite.lic
# mv genericJDBC.zip /opt/informatica/services/CatalogService/ScannerBinaries
# cd /opt/informatica/services/CatalogService/ScannerBinaries/CustomDeployer/
# nano scannerDeployer.xml
既存のExecutionContextProperty ノードを解凍したら、このコンテンツを含む新しいExecutionContextProperty ノードを追加します。
<ExecutionContextProperty
isLocationProperty="true"
dependencyToUnpack="genericJDBC.zip">
<PropertyName>JDBCScanner_DriverLocation</PropertyName>
<PropertyValue>scanner_miti/genericJDBC/Drivers</PropertyValue>
</ExecutionContextProperty>
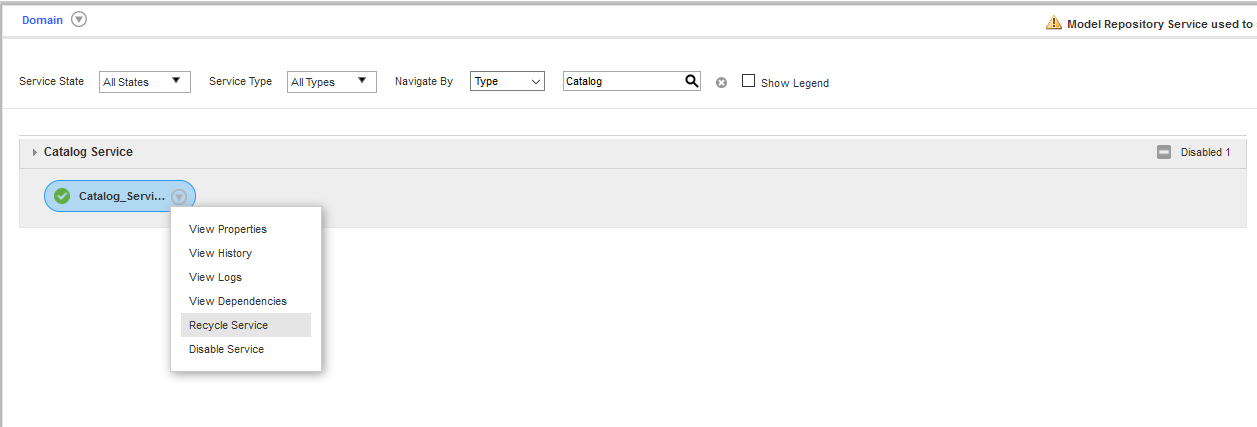
JDBC リソースの構成
以下の手順でJDBC リソースを構成します。
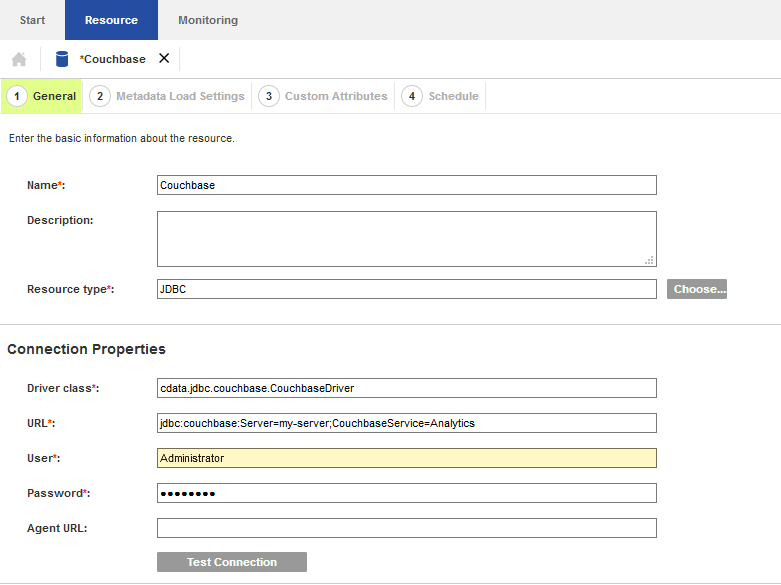
- Catalog のアドミニストレーターを開き、次のプロパティを持つ新しいJDBC リソースを追加します。
- Driver Class: cdata.jdbc.netsuite.NetSuiteDriver
- URL:
jdbc.netsuite:Account Id=XABC123456;Password=password;User=user;Role Id=3;Version=2013_1; - SuiteTalk はNetSuite との通信に使用する、SOAP ベースのより古いサービスです。多くのエンティティを幅広くサポートし、INSERT / UPDATE / DELETE を完全にサポートします。 しかしデータの抽出用ツールは低機能で、SELECT 時のパフォーマンスは極めて低いです。テーブルを結合するよい方法もありません。データのグループ化および集計はこのAPI からは利用できず、 そのためこれらの操作をサポートするには、すべてをクライアントサイドで実行しなければなりません。
- SuiteQL は新しいAPI です。サービスとのSQL ライクな通信方法を実現するため、JOIN の機能はより豊富になり、GROUP BY や集計機能もサポートします。 加えて、抽出したいカラムだけを取得する機能も完全にサポートします。そのため、データを抽出する際のパフォーマンスがSuiteTalk より大幅に向上しています。ただし、サポートされるのはデータの抽出のみです。
- Schema を設定して、接続に使用するAPI を指定。データを取得するだけの場合は、SuiteQL の使用をお勧めします。データの取得および変更が必要な場合は、SuiteTalk の使用をお勧めします。
- 使用するAPI に適した接続オプションを設定します。(それぞれのAPI で利用可能な接続オプションが異なります。ヘルプドキュメントの「許可の設定」を参照してください。)
- トークンベース認証(TBA)は、基本的にOAuth 1.0 で、OAuthAccessToken とOAuthAccessTokenSecret を実行時ではなくNetSuite UI 内で作成します。 TBA は、2020.2 以降のSuiteTalk およびSuiteQL の両方で利用可能です。
- OAuth 2.0 認証は、SuiteQL でのみ利用できます。OAuth 2.0 認証を強制するには、次のいずれかを実行します。
- OAuthVersion を使用するAPI に明示的に設定、または
- Schema をSuiteQL に設定
- OAuth JWT 認証は、OAuth 2.0 クライアント認証フローであり、クライアント認証情報を含むJWT を使用してNetSuite データへのアクセスを要求します。この認証方法は、Schema がSuiteQL に設定されている場合にのみ使用できます。
- ユーザー名: user
- パスワード: password
- 少なくとも一つのソースメタデータスキャンを実行するようにメタデータオプションを構成します。このスキャンではドライバーを使用し、サービスを通じて使用できるテーブル、ビュー、ストアドプロシージャを判別します。
- Source Metadata: このオプションを有効にする。
- Catalog: これをマルチカタログデータソースの適切なカタログに設定します。もしくは、CData に設定します。
- Schema: これをマルチスキーマデータソースの適切なスキーマに設定します。もしくは、これをサービスの名前に設定します。(以下ではCouchbase)
- Case-sensitivity: 通常このオプションは無効にします。大文字と小文字が区別されるデータソースに対してのみ有効にしてください。
- Import stored procedures: テーブルとビューに加え、ストアドプロシージャディフィニションをインポートする場合は、これを有効にします。
- ドライバーの構成を完了し、オプションでカスタム属性とスキャナースケジュールを構成します。
- [Monitoring]タブに移動し[Run]をクリックしてメタデータスキャンを実行します。データソースによっては、これに数分かかる場合があります。
Netsuite への接続
NetSuite は現在、2つの異なるAPI を提供しています。
NetSuite に接続するには、以下を行う必要があります。
Netsuite への認証
SuiteTalk またはSuiteQL
NetSuite は3つの形式のOAuth 認証を提供します。
認証方法の詳細はヘルプドキュメントの「はじめに」を参照してください。
ビルトイン接続文字列デザイナ
JDBC URL の構成については、NetSuite JDBC Driver に組み込まれている接続文字列デザイナを使用してください。.jar ファイルのダブルクリック、またはコマンドラインから.jar ファイルを実行します。
java -jar cdata.jdbc.netsuite.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
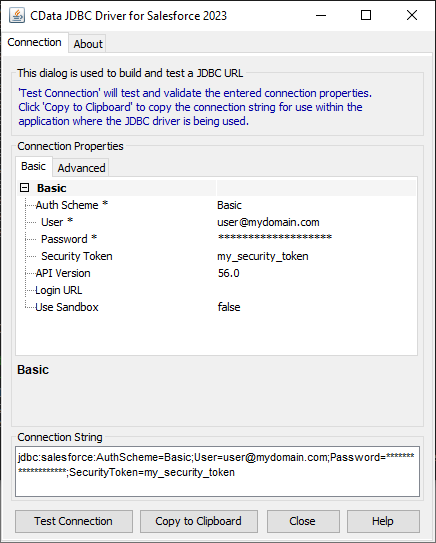
JDBC URL を構成する際に、Max Rows プロパティを定めることも可能です。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は、一般的な追加の接続文字列プロパティです。
JDBC;MSTR_JDBC_JAR_FOLDER=PATH\TO\JAR\;DRIVER=cdata.jdbc.netsuite.NetSuiteDriver;URL={jdbc:netsuite:Account Id=XABC123456;Password=password;User=user;Role Id=3;Version=2013_1;};
使用しているドライバーに要求されなくても、ユーザー名とパスワードのプロパティは必須であることに注意してください。そのようなケースでは、代わりにプレスホルダー値を入力できます。
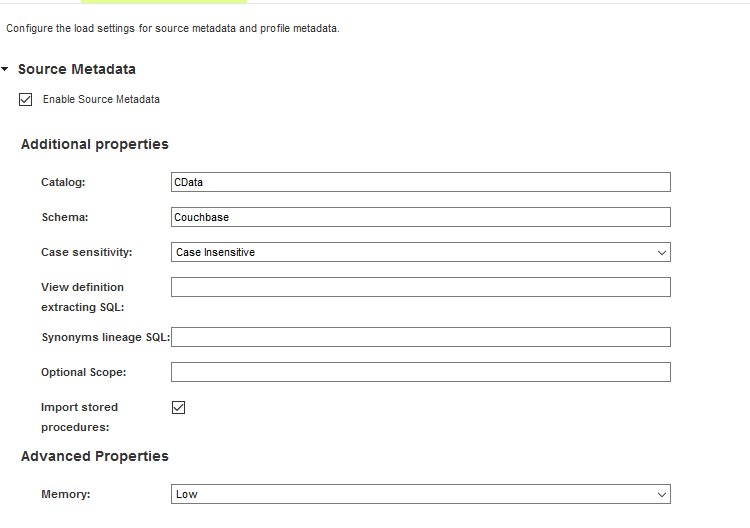
他のメタデータスキャナーは、必要に応じて有効にすることができます。
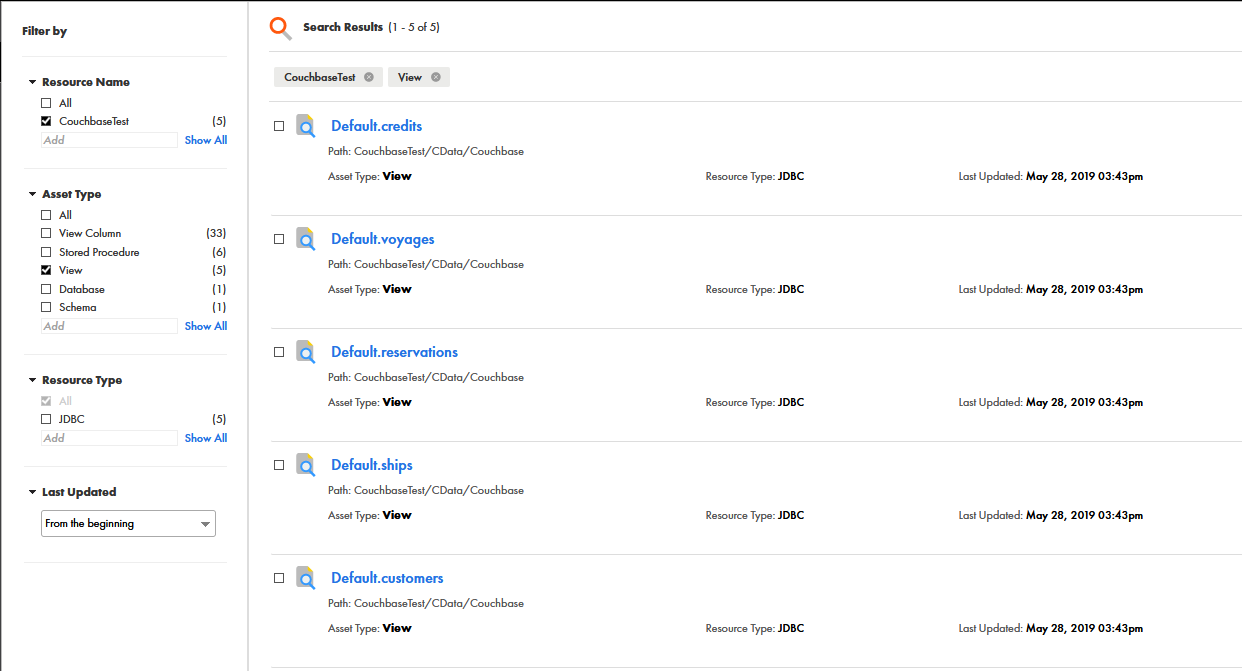
スキャンが完了すると、すべてのメタデータオブジェクトの概要が[Metadata Load job]のステータスとともに表示されます。エラーが発生した場合、[Log Location]リンクを開き、インフォマティカまたはドライバーから報告されたエラーを確認できます。
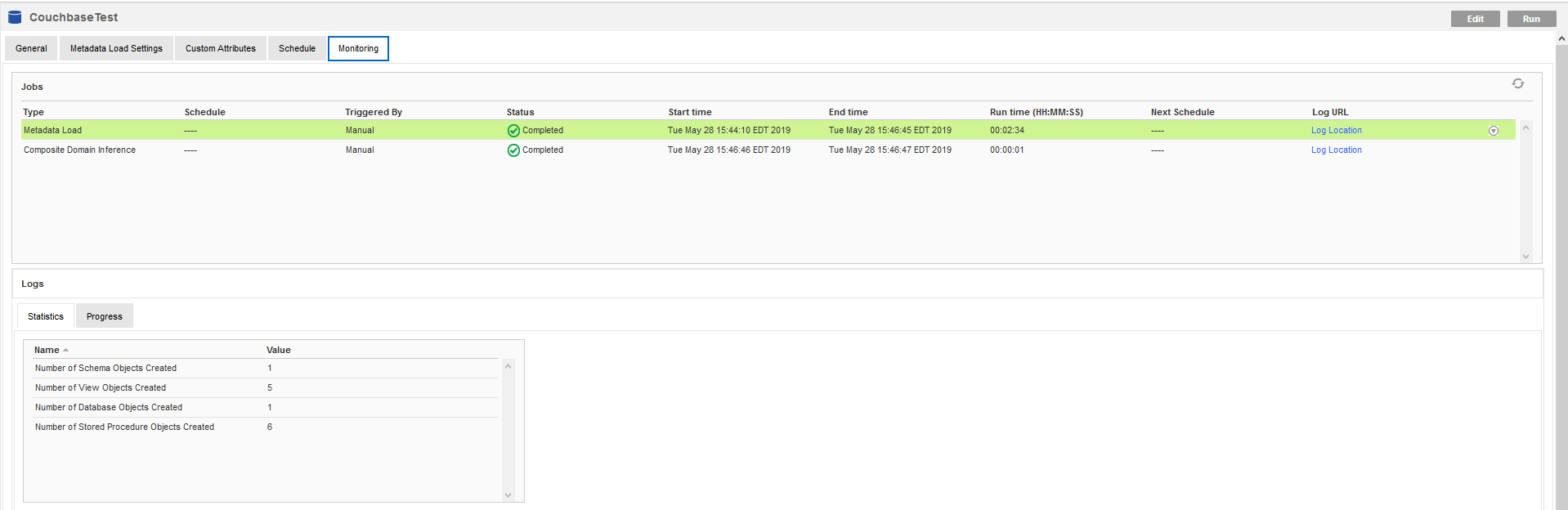
検出されたメタデータを検証
[Catalog Service]を開き、データソースから検出されたメタデータを表示します。メタデータスキャナーの構成時に選択したオプションによっては、定義したリソースのテーブル、ビュー、ストアドプロシージャの任意の組み合わせが表示される場合があります。