各製品の資料を入手。
詳細はこちら →



DB2 のデータをAI アシスタントのPEP から利用する方法
AI アシスタントPEP から DB2 のデータに連携し、チャットボットでリアルタイムDB2 のデータを使う方法
最終更新日:2022-06-24
この記事で実現できるDB2 連携のシナリオ


こんにちは!リードエンジニアの杉本です。
CData API Server と ADO.NET Provider / JDBC Driver for DB2 を使って、AI アシスタントPEP(https://pep.work/) から DB2 に接続して、チャットボットでリアルタイムDB2データを使った応答を可能にする方法を説明します。
API Server の設定
次のステップに従い、セキュアな REST API サービスを立ち上げます
デプロイ
API Server はサーバー上で稼働します。Windows 版は、製品に組み込まれているスタンドアロンのサーバーかIIS に配置して稼働させることができます。Java 版では、Java servlet コンテナにAPI Server のWAR ファイルを配置します。 デプロイの詳細は製品ヘルプを参照してください。API Server を Microsoft Azure、 Amazon EC2、Heroku にデプロイする方法はKB に記事があります。
DB2 への接続
API Server の管理コンソールで[設定]→[接続]から新しい接続を追加してDB2 を追加します。
DB2 のアイコンがデフォルトのAPI Server の接続先にない場合には、API Server がJava 版の場合はJDBC Drivers、API Server がWindows 版の場合はADO.NET Data ProvidersからDB2 ドライバーをAPI Server と同じマシンにインストールして、API Server を再起動します。

DB2 への接続に必要な認証情報を入力します。接続のテストを行い、接続を確認して、設定を保存します。
DB2 に接続するには以下のプロパティを設定します。
- Server: DB2 を実行するサーバー名。
- Port: DB2 サーバーのポート。
- Database: DB2 データベース名。
接続の準備ができたら、認証スキームを選択し、以下で説明するように適切なプロパティを設定します。
本製品 は、DB2 への認証に4つの異なるスキームをサポートします。DB2 ユーザー資格情報(デフォルト)、暗号化されたユーザー資格情報、IBM Identity and Access Management(IAM)認証、および Kerberos です。
DB2 ユーザー資格情報
ユーザー資格情報を使用して認証するには、次のプロパティを設定します。- AuthScheme:USRIDPWD。
- User:データベースへのアクセス権を持つユーザーのユーザー名。
- Password:データベースへのアクセス権を持つユーザーのパスワード。
暗号化されたユーザー資格情報
サーバーがセキュア認証に対応しており、暗号化されたユーザー資格情報を使用して認証を行いたい場合は、このプロパティを設定します。- AuthScheme:EUSRIDPWD
IAM、Kerberos で認証したい場合は、ヘルプドキュメントの「はじめに」セクションを参照してください。
パスワード方式によるSSH 接続
パスワード方式によるSSH接続時に必要なプロパティ一覧を以下に示します。
- User: DB2 のユーザ
- Password: DB2 のパスワード
- Database: DB2 の接続先データベース
- Server: DB2 のサーバー
- Port: DB2 のポート
- UserSSH: "true"
- SSHAuthMode: "Password"
- SSHPort: SSH のポート
- SSHServer: SSH サーバー
- SSHUser: SSH ユーザー
- SSHPassword: SSH パスワード
接続文字列形式では以下のようになります。
Server=10.0.1.2;Port=50000;User=admin;Password=admin;Database=testUseSSH=true;SSHAuthMode=Password;SSHPort=22;SSHServer=ssh-server;SSHUser=root;SSHPassword=sshpasswd;
公開鍵認証方式方式によるSSH 接続
公開鍵認証によるSSH接続時に必要なプロパティ一覧を以下に示します。
- User: DB2 のユーザ
- Password: DB2 のパスワード
- Database: DB2 の接続先データベース
- Server: DB2 のサーバー
- Port: DB2 のポート
- UserSSH: "true"
- SSHAuthMode: "Public_Key"
- SSHClientCertType: キーストアの種類
- SSHPort: SSH のポート
- SSHServer: SSH サーバー
- SSHUser: SSH ユーザー
- SSHClientCert: 秘密鍵ファイルのパス
接続文字列形式では以下のようになります。
Server=10.0.1.2;Port=50000;User=admin;Password=admin;Database=test;UseSSH=true;SSHAuthMode=Public_Key;SSHClientCertType=PUBLIC_KEY_FILE;SSHPort=22;SSHServer=ssh-server;SSHUser=root;SSHClientCert=C:\Keys\key.pem;
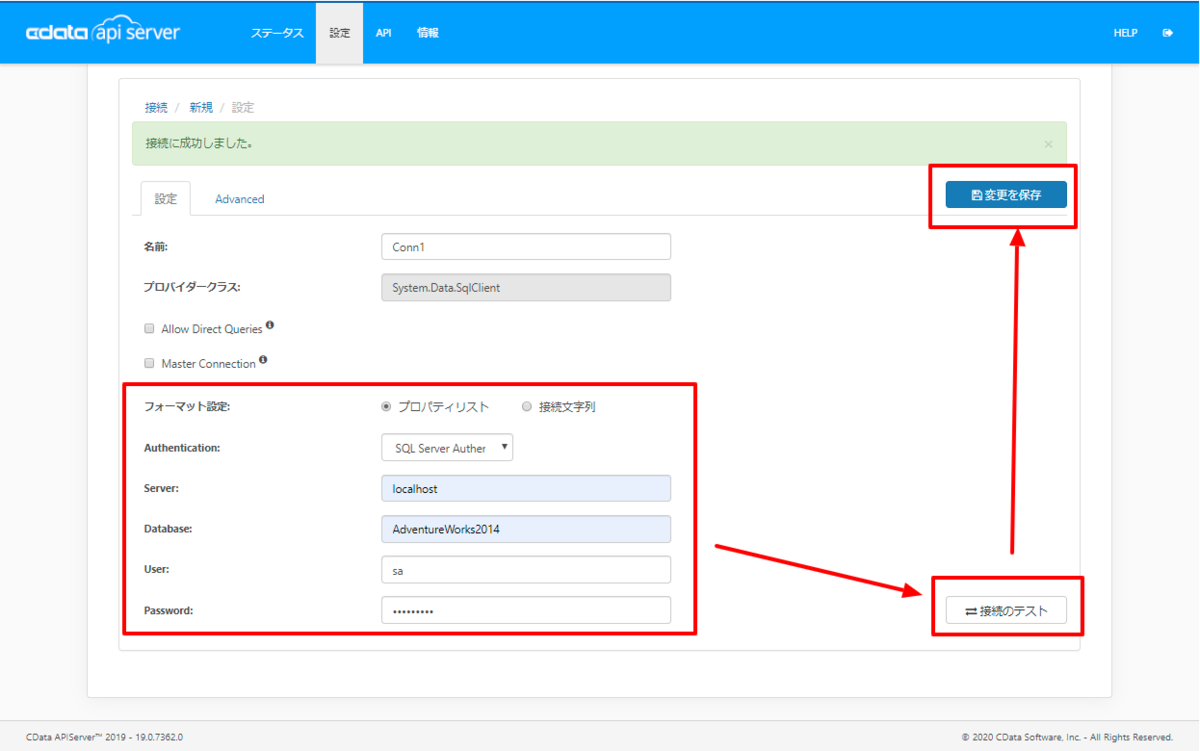
接続を確立後、[設定]→[リソース]の画面で からREST API として公開するエンティティを選択します。
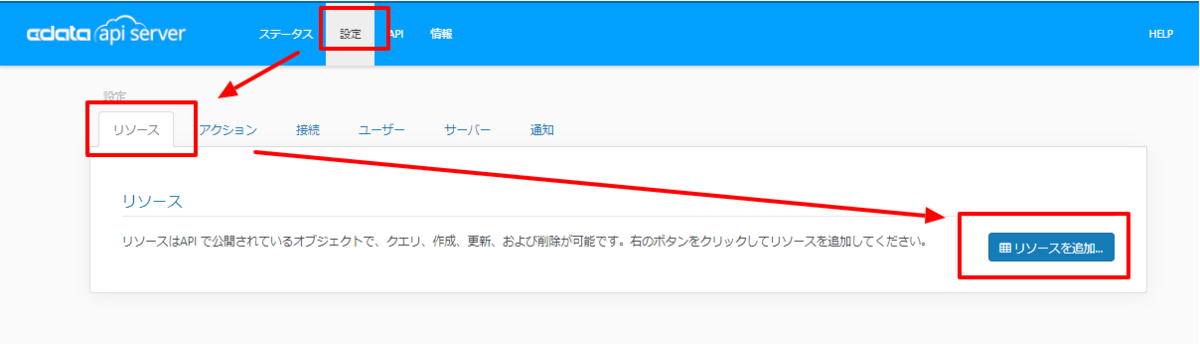
API Server のユーザー設定
[設定]→[ユーザー]からAPI にアクセスできるユーザーの認証設定を行います。API Server はトークンでの認証を行うことができます。 IP アドレスでAPI へのアクセスを制限することも可能です。デフォルトではローカルマシンからのアクセスのみが許可されています。SSL の設定も可能です。
オンプレミスDB やファイルからのAPI Server 使用(オプション)
オンプレミスRDB やExcel/CSV などのファイルのデータを使用する場合には、API Server のCloug Gateway / SSH ポートフォワーディングが便利です。是非、Cloud Gatway の設定方法 記事を参考にしてください。
PEP でDB2 のデータをチャットで使う設定
前項まででAPI ができたので、ここからはPEP 側での設定作業です。
PEP でDB2 のAPI をコールするシナリオを作成
PEP 側ではあらかじめSlack などのアプリケーションを構成しておきます。ここにAPI Server をコールするAI アシスタントのシナリオを追加していきます。
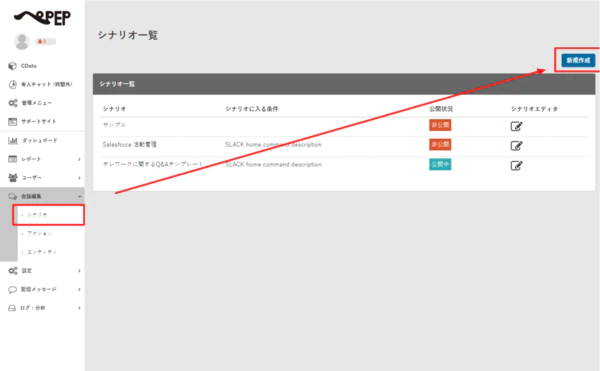
- 「会話編集」→「シナリオ」に移動し、新しいシナリオを作成します。
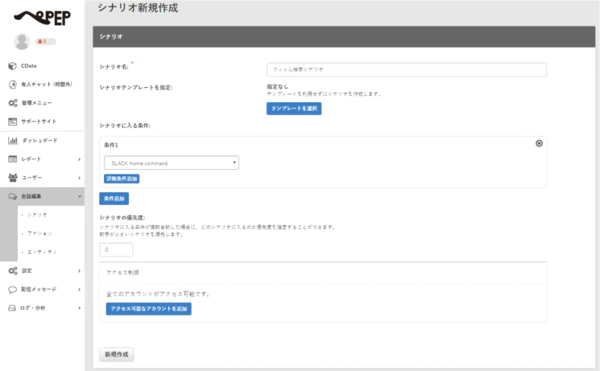
- シナリオ名を入力します。この例では、条件はSlack Homeを 選択しています。
- 「新規作成」ボタンをクリックすると、以下のようなシナリオエディタ画面に移動します。これでシナリオを作成する準備ができました。
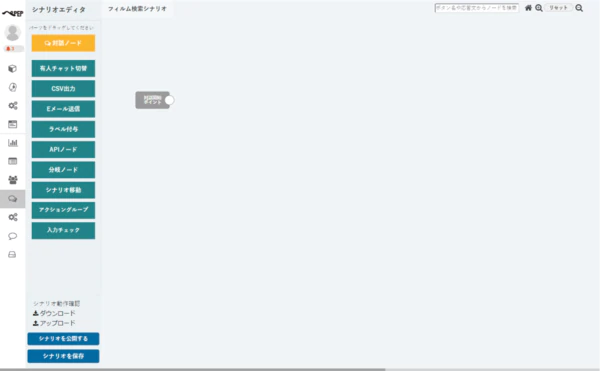
DB2 のAPI の接続箇所の設定
具体的にAPI連携を含めたシナリオを作っていきます。
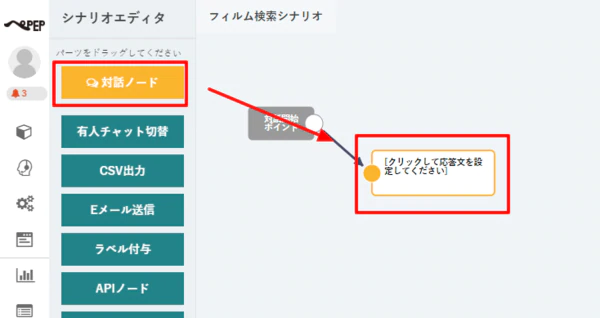
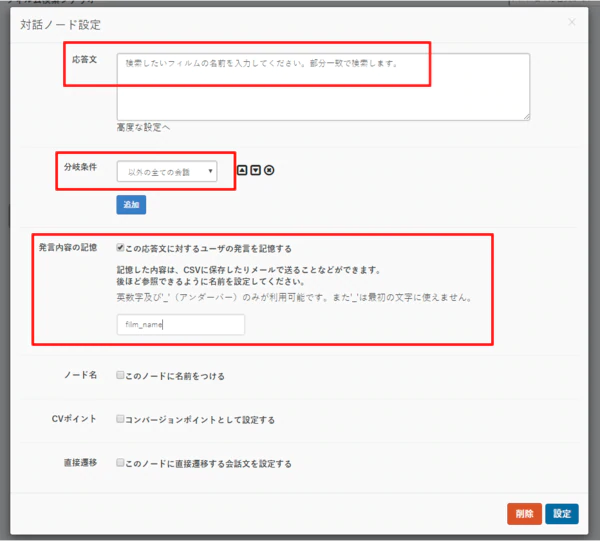
- 最初に検索したい文字列を受け取るための対話ノードを配置して、以下のように構成します。
- ポイントは分岐条件で「以下のすべての会話」、発言内容の記憶で「film_name」として、会話した内容を変数に保存することです。
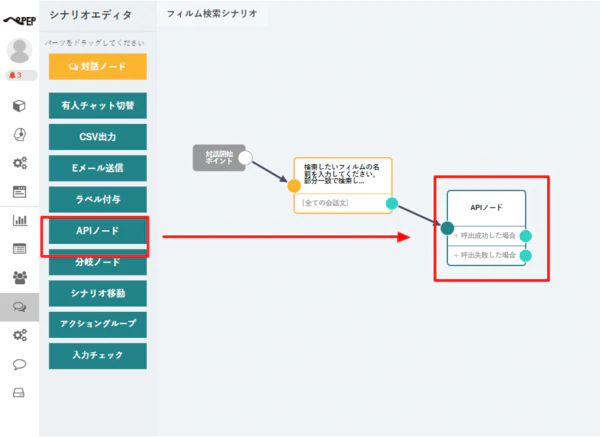
- 対話ノードを配置したら、APIノードを追加して、対話ノードから接続していきます。
- APIノードでは、以下のように CData API Server へのリクエストを構成します。
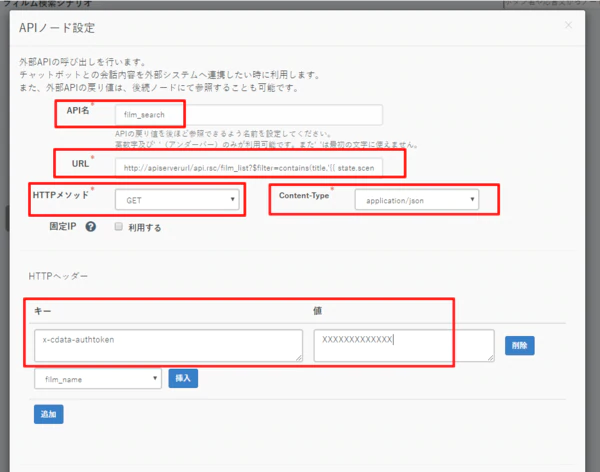
ポイントは2つです。CData API Server は Filter 機能によって、取得するデータを絞り込むことができます。その指定が「$filter=contains(title,'{{ state.scenario_4.form.film_name }}')」の部分です。 「{{ state.scenario_4.form.film_name }}」は直前の対話ノードで設定した変数をパラメータとして渡しています。「scenario_4」はPEP のシナリオIDですので、作成したシナリオに合わせて変更してください。 - HTTPヘッダーにAPI Server のユーザートークンを指定します。
- API名:任意の名前を設定
- URL:http://apiserverurl/api.rsc/film_list?$filter=contains(title,'{{ state.scenario_4.form.film_name }}')
- HTTPメソッド:GET
- Content-Type:JSON
- HTTPヘッダー:キー「x-cdata-authtoken」、値「予め取得したAPI Serverのトークン」を指定
これで保存すると、API ノードが使えるようになります。
取得したDB2 からのレスポンスの表示方法
最後に後続の対話ノードを構成し、取得した検索結果を表示します。
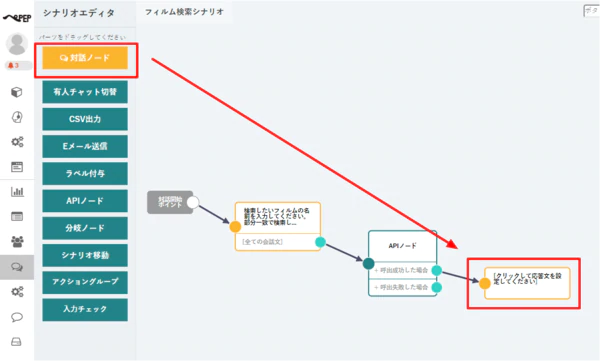
対話ノードの応答文には、以下のような文章を埋め込みます。
検索結果は以下のとおりです。
{% for item in state.scenario_4.api_response.film_search.value %}
フィルムID:{{ item.FID }}
タイトル : {{ item.title }}
値段:{{ item.price }}
カテゴリー:{{ item.category }}
俳優: -----
{% endfor %}
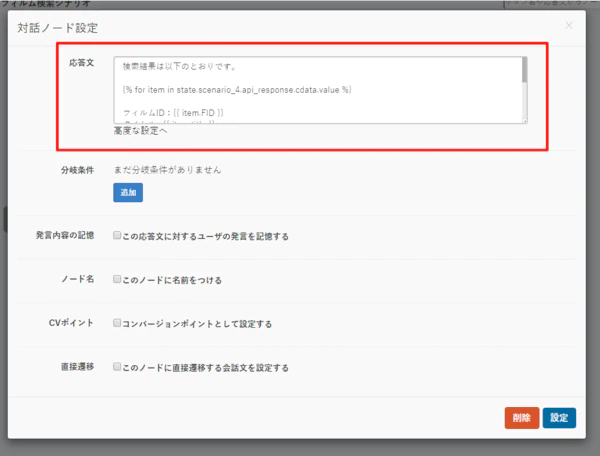
ここでポイントになるのは、API Server から受け取るJSONのレスポンスの分解方法です。
API Server のレスポンスはオブジェクト直下にvalueという配列要素があり、このレスポンスは「{{state.scenario_4.api_response.film_search.value}}」の形でアクセスできます。
設定イメージ:state.シナリオID.api_response.APIノード名.value
これを「FOR」での繰り返し処理で取得して、文章として表示する仕組みになっています。
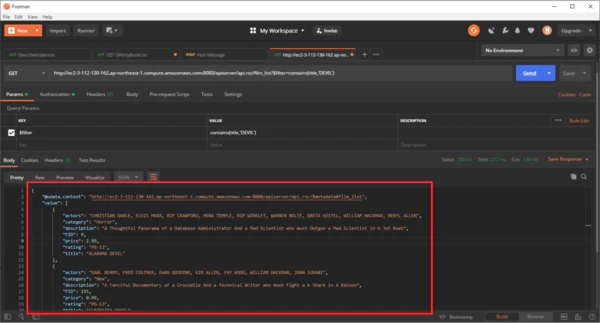
これで設定は完了です。実際に動かしてみると、DB2 →API Server → PEP 経由でデータを取得して表示していることがわかるかと思います。
CData API Server の無償版およびトライアル
CData API Server は、無償版および30日の無償トライアルがあります。是非、API Server ページ から製品をダウンロードしてお試しください。