各製品の資料を入手。
詳細はこちら →



製品をチェック
MicroStrategy Web でCData JDBC Driver を使用してRedshift に接続
CData JDBC Driver を使用してMicroStrategy Web からRedshift のデータに接続。
最終更新日:2023-10-04
こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
MicroStrategy は、データドリブンイノベーションを可能にする分析およびモバイルプラットフォームです。MicroStrategy とCData JDBC Driver for Redshift を組み合わせると、MicroStrategy からデータベースと同じようにリアルタイムRedshift のデータにアクセスできるようになり、レポート機能と分析機能が拡張されます。この記事では、MicroStrategy Web の外部データソースとしてRedshift を追加し、Redshift のデータの簡単なビジュアライゼーションを作成する方法について説明します。
CData JDBC ドライバーは、ドライバーに組み込まれている最適化されたデータ処理により、MicroStrategy でリアルタイムRedshift のデータとやり取りするための比類のないパフォーマンスを提供します。MicroStrategy からRedshift に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をRedshift に直接プッシュし、組み込まれたSQL エンジンを利用してサポートされていない操作(主にSQL 関数とJOIN 操作)をクライアント側で処理します。ビルトインの動的メタデータクエリを使用すると、ネイティブのMicroStrategy データタイプを使用してRedshift のデータをビジュアライズおよび分析できます。
MicroStrategy Web を使用してRedshift のデータに接続し、ビジュアライズする
CData JDBC Driver for Redshift を使用したデータソースを追加することにより、MicroStrategy Web のRedshift に接続できます。*始める前に、MicroStrategy Web のインスタンスが接続されているMicroStrategy Intelligence Server をホストするマシンにJDBC Driver for Redshift をインストールする必要があります。データソースを作成したら、MicroStrategy Web でRedshift のデータの動的なビジュアライゼーションを構築できます。
- MicroStrategy Web を開き、プロジェクトを選択します。
- [Add External Data]をクリックし、[Databases]を選択して[Import Option]として[Select Tables]を使用します。
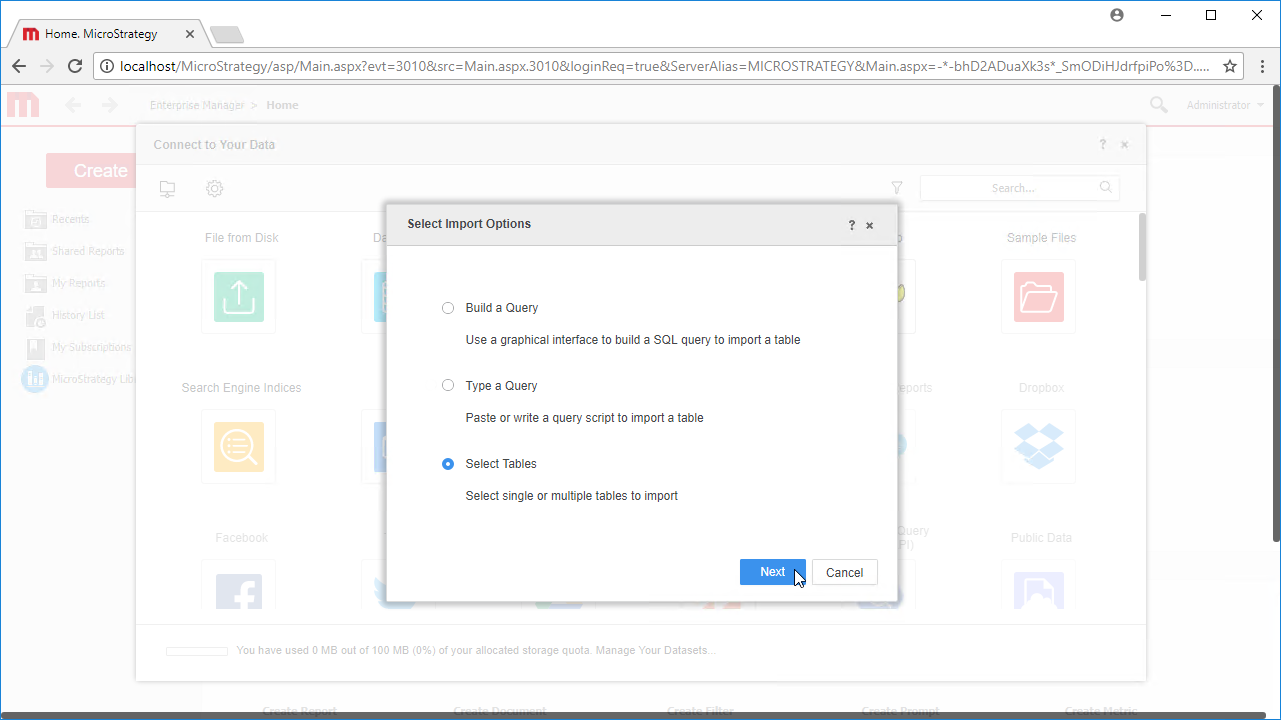
- [Import from Tables]ウィザードでクリックして新しいデータソースを追加します。
- [Database]メニューで[Generic]を選択し、[Version]メニューで[Generic DBMS]を選択します。
- リンクをクリックして接続文字列を表示し、接続文字列を編集するオプションを選択します。「Driver」メニューで、「MicroStrategy Cassandra ODBC Driver」を選択します。(MicroStrategy では、JDBC を介してインターフェースするために認定ドライバーが必要なだけで、実際のドライバーは使用されません。
- 接続文字列を次のように設定します。
JDBC;MSTR_JDBC_JAR_FOLDER=PATH\TO\JAR\;DRIVER=cdata.jdbc.redshift.RedshiftDriver;URL={jdbc:redshift:User=admin;Password=admin;Database=dev;Server=examplecluster.my.us-west-2.redshift.amazonaws.com;Port=5439;};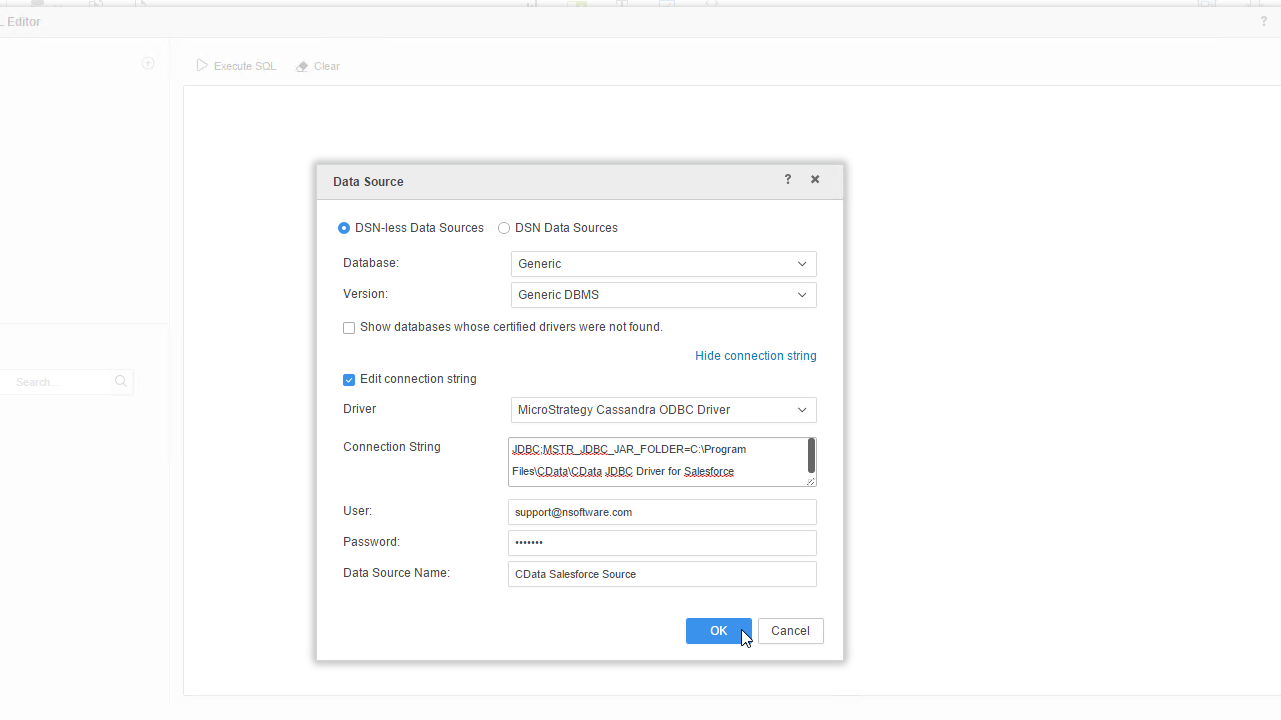
Redshift への接続には次を設定します:
- Server: 接続するデータベースをホストしているクラスタのホスト名およびIP アドレス。
- Port: クラスタのポート。
- Database: データベース名、ブランクの場合ユーザーのデフォルトデータベースになります。
- User: ユーザー名。
- Password: ユーザーのパスワード。
Server およびPort の値はAWS の管理コンソールで取得可能です:
- Amazon Redshift console (http://console.aws.amazon.com/redshift) を開く。
- Clusters ページで、クラスタ名をクリック。
- クラスタのConfiguration タブで、表示された接続文字列からクラスタのURL をコピーします。
組み込みの接続文字列デザイナー
JDBC URL の構築については、Redshift JDBC Driver に組み込まれている接続文字列デザイナーを使用してください。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.redshift.jar接続プロパティを入力し、接続文字列をクリップボードにコピーします。
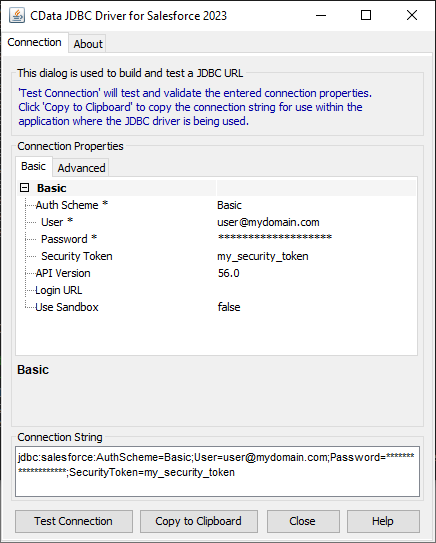
JDBC URL を構成する際に、Max Rows 接続プロパティも設定できます。これにより返される行数が制限されるため、レポートやビジュアライゼーションをデザインするときのパフォーマンスを向上させることができます。
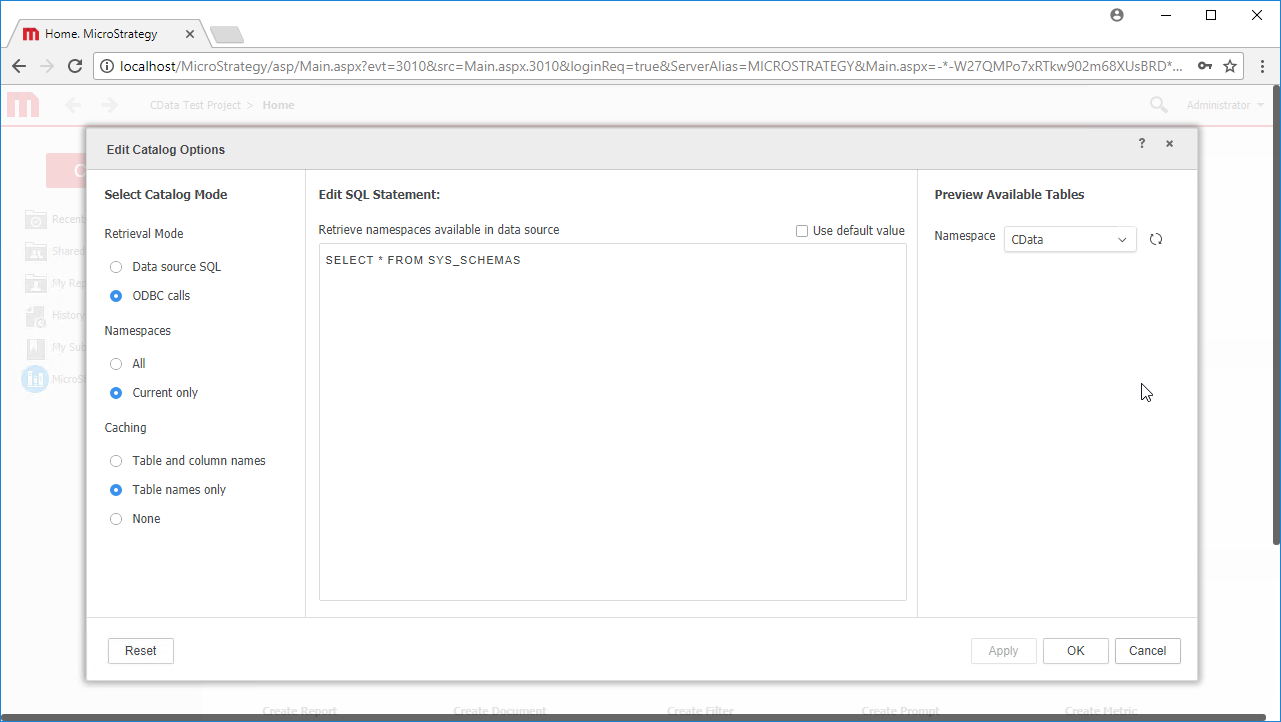
- 新しいデータソースで右クリックし、「Edit catalog options」を選択します。
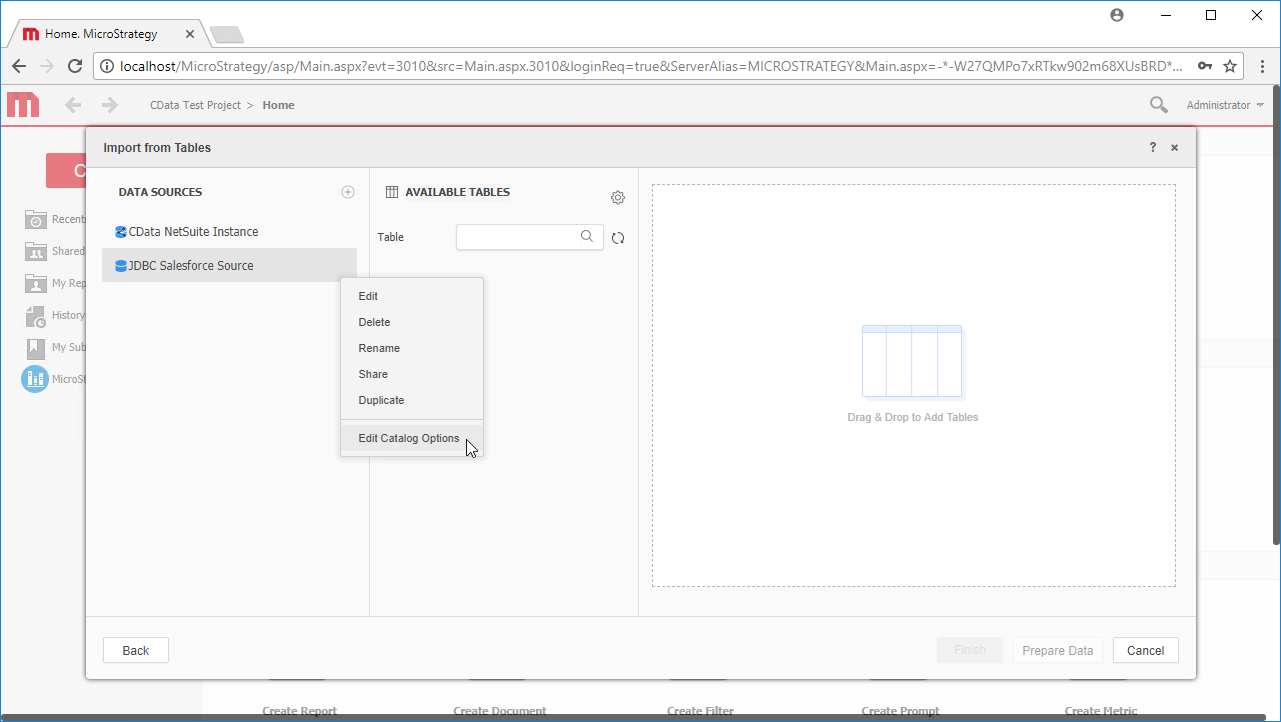
- SQL Statement をSELECT * FROM SYS_SCHEMAS に編集し、JDBC Driver からメタデータを読み取ります。
- 新しいデータソースを選択して使用可能なテーブルを表示します。テーブルを表示するには、「Available Tables」セクションの検索アイコンを手動でクリックする必要があります。
- テーブルをペインにドラッグしてインポートします。
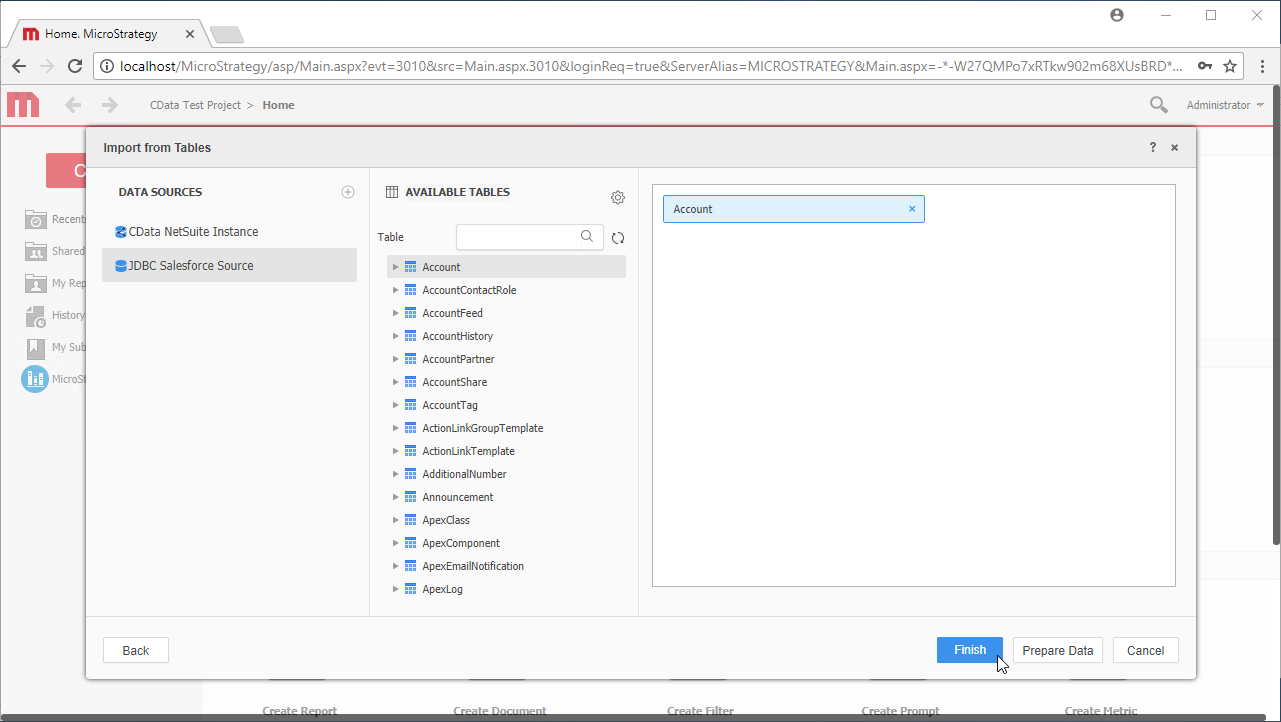 Note:ライブ接続を作成するので、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用してデータセットをカスタマイズできます。
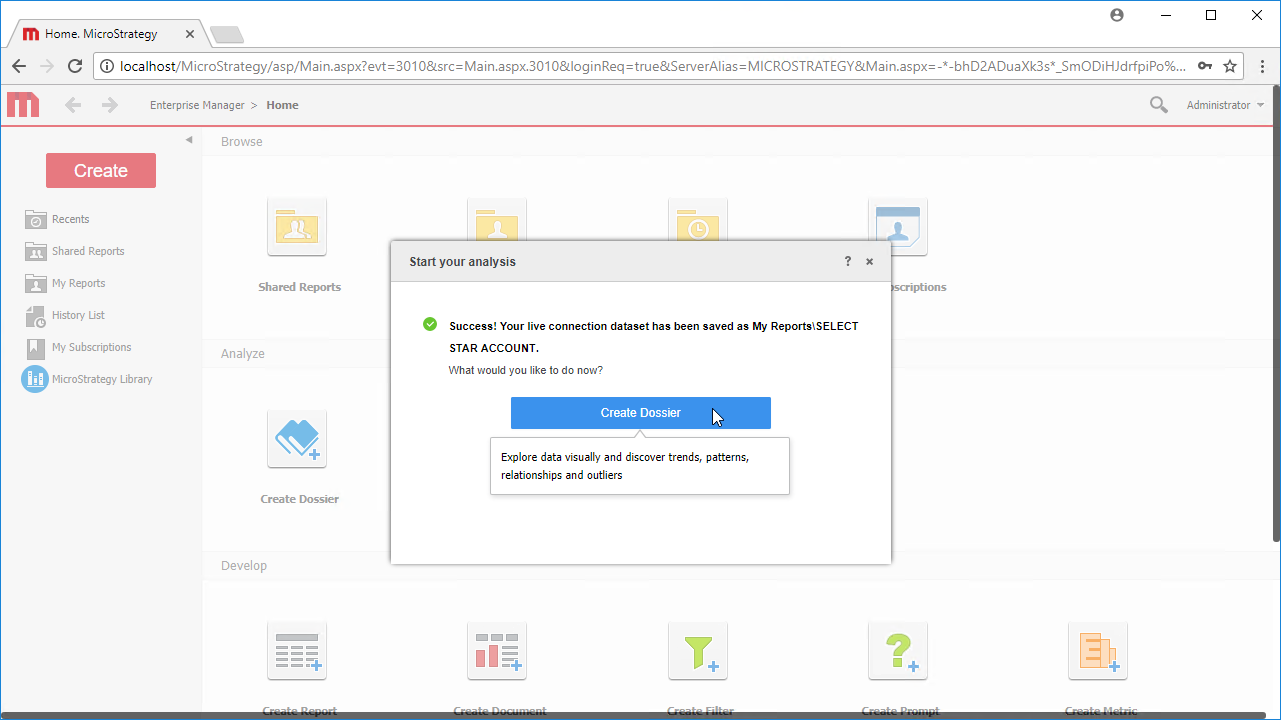
Note:ライブ接続を作成するので、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用してデータセットをカスタマイズできます。 - [Finish]をクリックして、ライブ接続するオプションを選択してクエリを保存し、新しいドシエを作成するオプションを選択します。CData JDBC ドライバーにネイティブな高性能データ処理を使用して、高性能なライブ接続が可能です。
- ビジュアライゼーションを選択して表示するフィールドを選択し、フィルタを適用してRedshift のデータの新しいビジュアライゼーションを作成します。データ型は動的なメタデータ検出によって自動的に検出されます。可能であれば、フィルタと集計によって生成された複雑なクエリはRedshift にプッシュダウンされ、サポートされていない操作(SQL 関数とJOIN 操作を含む)は、ドライバーに組み込まれたCData SQL エンジンによってクライアント側で管理されます。
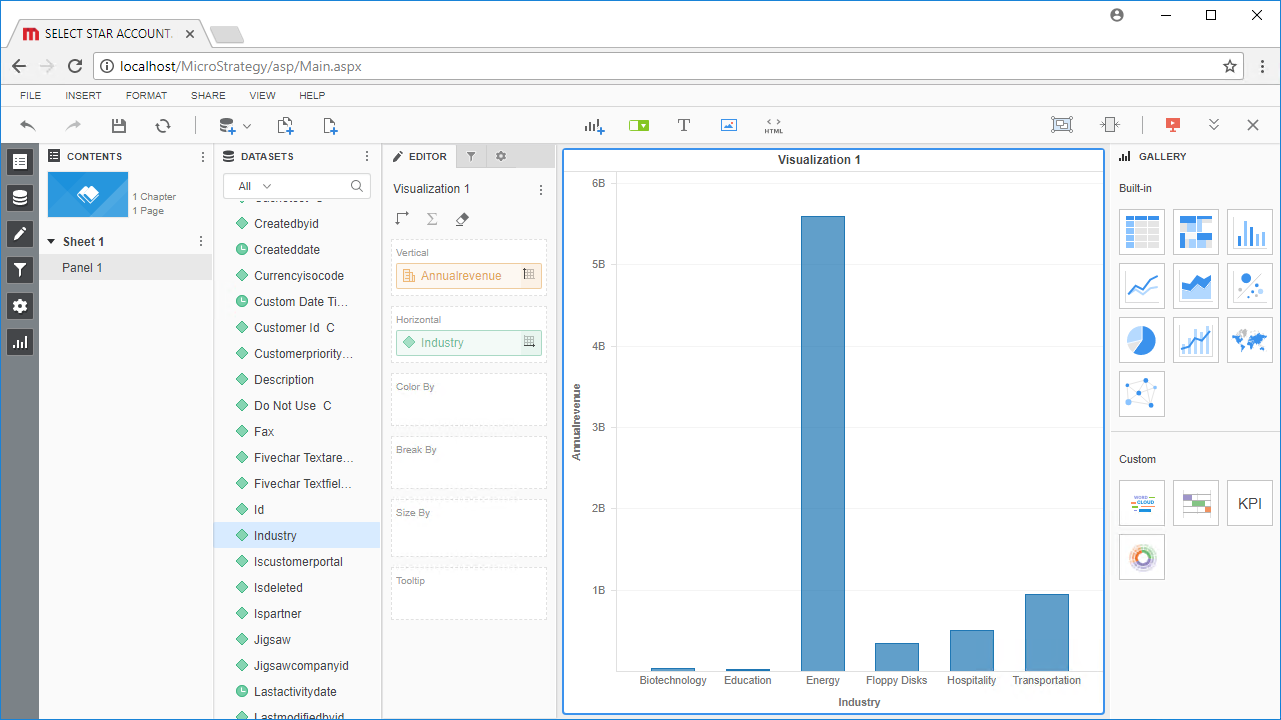
- ドシエの構成が完了したら、[File]->[Save]とクリックします。
CData JDBC Driver for Redshift をMicroStrategy Web で使用することで、Redshift のデータで強固なビジュアライゼーションとレポートを簡単に作成することができます。その他の例については、MicroStrategy でRedshift に接続やMicroStrategy Desktop でRedshift に接続をお読みください。
Note:JDBC Driver を使用して接続するには、3- または 4-Tier Architecture が必要です。