各製品の資料を入手。
詳細はこちら →



Bitbucket のデータをAUTORO(旧Robotic Crowd) で連携して利用する方法
クラウド型RPA ツールのAUTORO(旧Robotic Crowd) で Bitbucket のデータに連携利用する方法
最終更新日:2022-05-16
この記事で実現できるBitbucket 連携のシナリオ

こんにちは!リードエンジニアの杉本です。
AUTORO(旧Robotic Crowd) www.roboticcrowd.com/ はクラウド型(SaaS)のロボティック・プロセス・オートメーション(RPA)で、普段利用しているブラウザで業務フローを記録し、ワークフローを作成することができるサービスです。
RPAの機能としての使いやすさはもちろんのこと、クラウドベースの特性を生かして、各種ストレージ(Google DriveやBox等)サービスやExcel・Google Spreadsheetなどの表計算ソフトとも連携できるのが特徴です。また、HTTPリクエストのアクションを利用することで、様々なAPIとの連携も可能になっています。
この記事ではCData API Server とADO.NET Bitbucket Provider を使って、AUTORO(旧Robotic Crowd) でBitbucket のデータを操作できるようにします。
API Server の設定
次のステップに従い、セキュアな OData サービスを立ち上げます。
デプロイ
API Server はサーバー上で稼働します。Windows 版は、製品に組み込まれているスタンドアロンのサーバーかIIS に配置して稼働させることができます。Java 版では、Java servlet コンテナにAPI Server のWAR ファイルを配置します。 デプロイの詳細は製品ヘルプを参照してください。API Server を Microsoft Azure、 Amazon EC2、Heroku にデプロイする方法はKB に記事があります。
Bitbucket への接続
Bitbucket アイコンをクリックして、接続画面を開き、接続プロパティを入力します。Bitbucket のアイコンがデフォルトのAPI Server の接続先にない場合には、API Server がJava 版の場合はJDBC Drivers、API Server がWindows 版の場合はADO.NET Data ProvidersからBitbucket ドライバーをAPI Server と同じマシンにインストールして、API Server を再起動します。
ほとんどのクエリでは、ワークスペースを設定する必要があります。唯一の例外は、Workspacesテーブルです。このテーブルはこのプロパティの設定を必要とせず、クエリを実行すると、Workspaceの設定に使用できるワークスペーススラッグのリストが提供されます。このテーブルにクエリを実行するには、スキーマを'Information'に設定し、SELECT * FROM Workspacesクエリを実行する必要があります。
Schemaを'Information'に設定すると、一般的な情報が表示されます。Bitbucketに接続するには、以下のパラメータを設定してください。
- Schema: ワークスペースのユーザー、リポジトリ、プロジェクトなどの一般的な情報を表示するには、これを'Information'に設定します。それ以外の場合は、クエリを実行するリポジトリまたはプロジェクトのスキーマに設定します。利用可能なスキーマの完全なセットを取得するには、sys_schemasテーブルにクエリを実行してください。
- Workspace: Workspacesテーブルにクエリを実行する場合を除き、必須です。Workspacesテーブルへのクエリにはこのプロパティは必要ありません。そのクエリはWorkspaceの設定に使用できるワークスペーススラッグのリストのみを返すためです。
Bitbucketでの認証
BitbucketはOAuth認証のみをサポートしています。すべてのOAuthフローからこの認証を有効にするには、カスタムOAuthアプリケーションを作成し、AuthSchemeをOAuthに設定する必要があります。
特定の認証ニーズ(デスクトップアプリケーション、Webアプリケーション、ヘッドレスマシン)に必要な接続プロパティについては、ヘルプドキュメントを必ず確認してください。
カスタムOAuthアプリケーションの作成
Bitbucketアカウントから、以下のステップを実行します。
- 設定(歯車アイコン)に移動し、ワークスペース設定を選択します。
- アプリと機能セクションで、OAuthコンシューマーを選択します。
- コンシューマーを追加をクリックします。
- カスタムアプリケーションの名前と説明を入力します。
- コールバックURLを設定します。
- デスクトップアプリケーションとヘッドレスマシンの場合、http://localhost:33333または任意のポート番号を使用します。ここで設定するURIがCallbackURLプロパティになります。
- Webアプリケーションの場合、信頼できるリダイレクトURLにコールバックURLを設定します。このURLは、ユーザーがアプリケーションにアクセスが許可されたことを確認するトークンを持って戻るWebの場所です。
- クライアント認証情報を使用して認証する予定の場合、これはプライベートコンシューマーですを選択する必要があります。ドライバーでは、AuthSchemeをclientに設定する必要があります。
- OAuthアプリケーションに与える権限を選択します。これにより、読み取りおよび書き込みできるデータが決まります。
- 新しいカスタムアプリケーションを保存するには、保存をクリックします。
- アプリケーションが保存された後、それを選択して設定を表示できます。アプリケーションのKeyとSecretが表示されます。これらを将来の使用のために記録してください。Keyを使用してOAuthClientIdを設定し、Secretを使用してOAuthClientSecretを設定します。
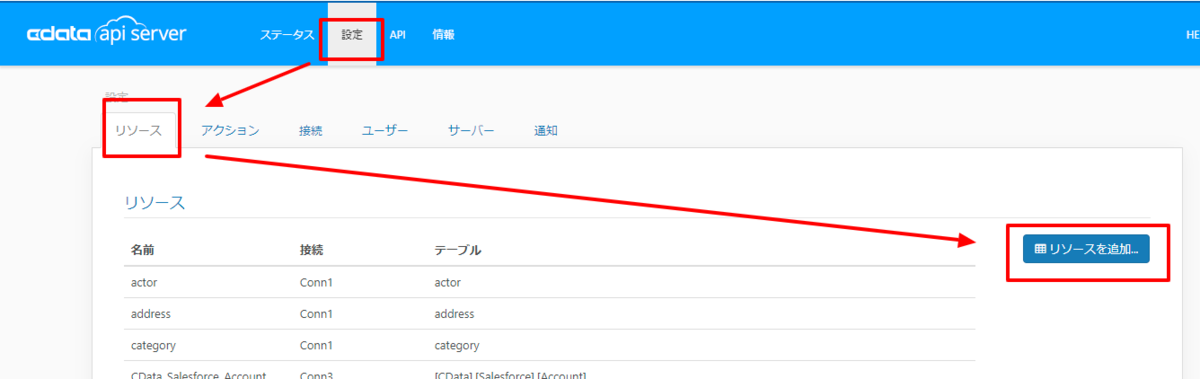
接続を確立後、[設定]→[リソース]の画面で からOData API として公開するエンティティを選択します。
API Server のユーザー設定
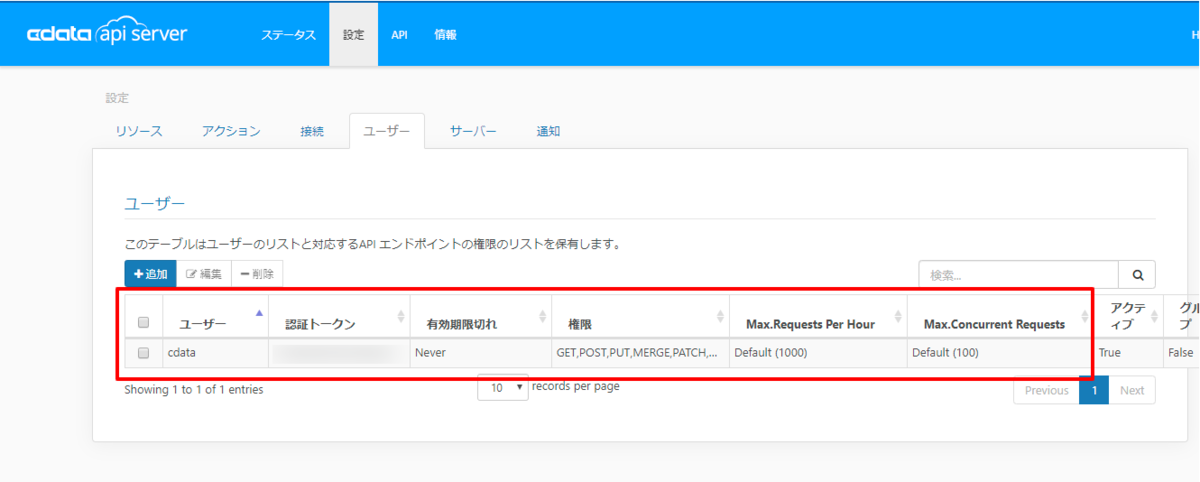
[設定]→[ユーザー]からAPI にアクセスできるユーザーの認証設定を行います。API Server はトークンでの認証を行うことができます。 IP アドレスでAPI へのアクセスを制限することも可能です。デフォルトではローカルマシンからのアクセスのみが許可されています。SSL の設定も可能です。
追加設定
AUTORO(旧Robotic Crowd) がクラウドサービスのため、API ServerはクラウドホスティングもしくはオンプレミスのDMZなどに配置して、AUTORO(旧Robotic Crowd) がアクセスできるように構成する必要があります。
API Server にはデフォルトでCloud Gatewayの機能も提供されているので、もしオンプレミスに配置する場合はこちらを使ってみてください。
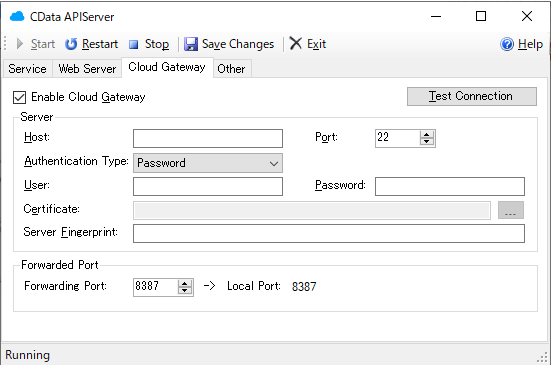
今回 AUTORO(旧Robotic Crowd) では「URL上のファイルを取得」というアクションでAPI Serverからデータを取得します。その際に、API Serverの認証はクエリパラメータによる認証方法を利用するので、「クエリ文字列パラメータとして認証トークンを使用する」の設定を有効化しておきます。なお、「HTTPリクエスト」のアクションを利用する場合は、この設定は不要です。CData API Server : Authentication
API エンドポイントができたので、確認します。「API」タブに移動すると、追加したリソースが表示されています。ここでリクエスト方法などを確認できます。
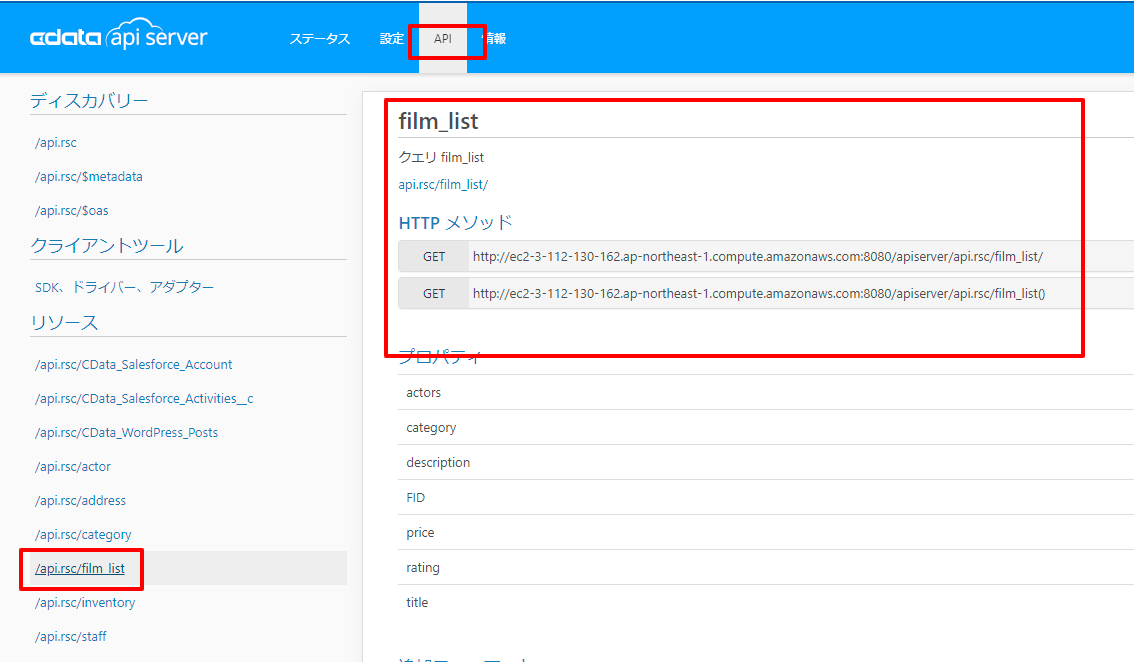
また、API Server はJSON以外にも様々なフォーマットでデータを取得できます。今回は最終的にCSVファイルをGoogle Driveにアップロードするため末尾に「?@format=csv」というパラメータを記載します。これによりCSV形式のファイルを取得できます。
オンプレミスDB やファイルからのAPI Server 使用(オプション)
オンプレミスRDB やExcel/CSV などのファイルのデータを使用する場合には、API Server のCloug Gateway / SSH ポートフォワーディングが便利です。是非、Cloud Gatway の設定方法 記事を参考にしてください。
AUTORO(旧Robotic Crowd) でBitbucket のデータをCSV として扱う方法
AUTORO(旧Robotic Crowd) ワークフローの作成
- それではワークフローを作成していきましょう。「ワークフロー」から「+ワークフローを作成」をクリックして、作業を開始します。
- 任意のワークフロー名と割当ロボットを選択し「作成」をクリックします。なお、今回は実行結果がわかりやすいように「デバッグ実行モード」をONにしています。
- まず、API Server経由でデータを取得するフローを構成します。 前述の通り、APIアクセス方法のアクション2種類あります。一つは「HTTPRequest」でJSONを取得したり、APIにデータを渡したりすることが可能です。 もう一つは「URL上のファイルを取得」でこれでURL先のファイルをダウンロードしてきて、処理することができます。
- CData API Serverは両方のアクションで利用が可能ですが、今回はCSVファイルを Google Driveにアップロードしたいので、「URL上のファイルを取得」を使用します。JSONなどを利用したい場合は「HTTPRequest」を利用してください。
「URL上のファイルを取得」を配置し、接続先となるURLを入力します。対象のAPI ServerのURLにパラメータとして「@authoken」と「@format」をそれぞれ指定します。リソースはFilm_listとしました。
例:http://{API_SERVER_URL}/apiserver/api.rsc/film_list?@authtoken={USER_TOKEN}&@format=csv
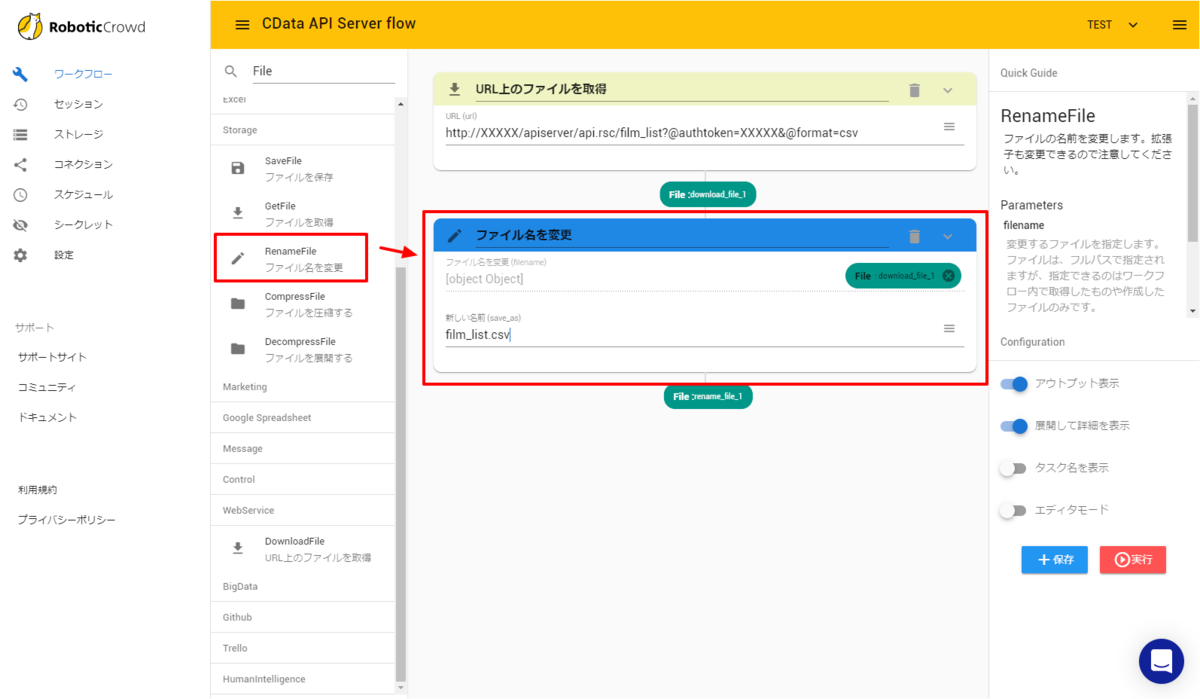
これによりCSVフォーマットでAUTORO(旧Robotic Crowd)にファイルをダウンロードできるようになります。 - ダウンロードしてきたCSVにファイル名を指定します。「RenameFile」のアクションを配置し、以下のように「film_list.csv」と入力しました。
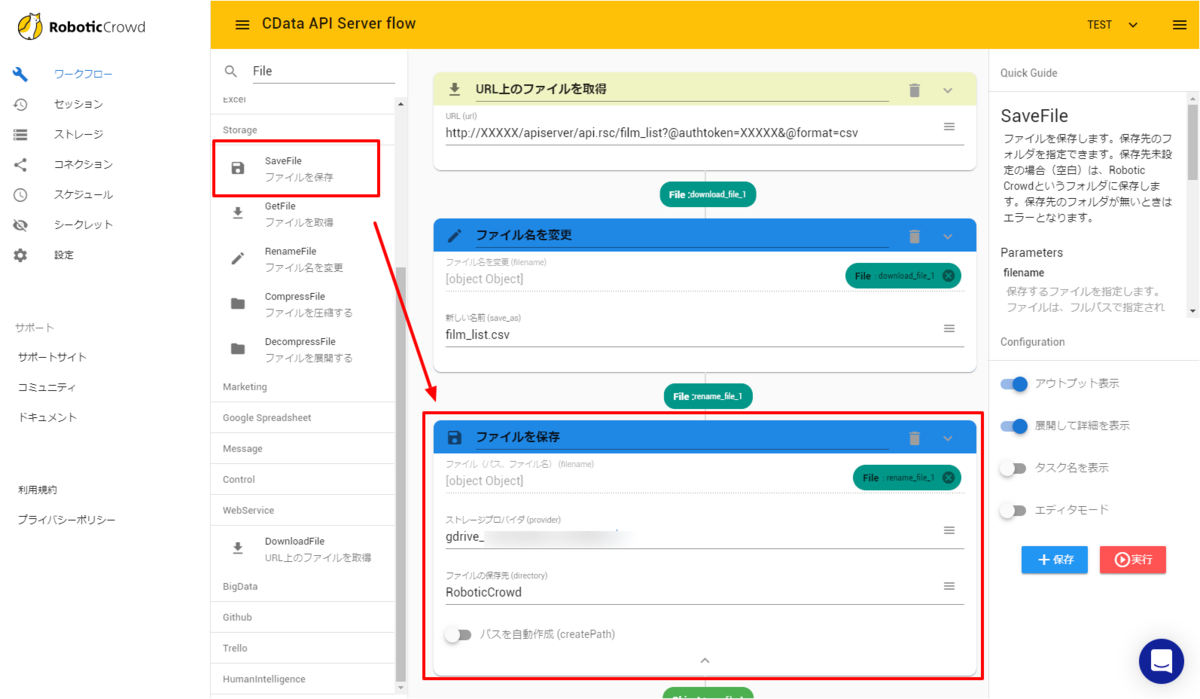
- 最後に今回はGoogle Driveへファイルをアップロードします。「SavaFile」のアクションを配置し「ストレージプロバイダ」に別途接続したGoogle Driveの設定を入力し、アップロード先のフォルダを指定します。


以上でワークフローの構成は完了です。あとは「保存」ボタンをクリックして「実行」してみましょう。
CData API Server の無償版およびトライアル
CData API Server は、無償版および30日の無償トライアルがあります。是非、API Server ページ から製品をダウンロードしてお試しください。