各製品の資料を入手。
詳細はこちら →



製品をチェック
Apache Airflow でDB2 のデータに連携したワークフローを作る
CData JDBC Driver を使ってApache Airflow からDB2 のデータにアクセスして操作します。
最終更新日:2022-09-07
この記事で実現できるDB2 連携のシナリオ


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
Apache Airflow を使うと、データエンジニアリングワークフローの作成、スケジューリング、および監視を行うことができます。CData JDBC Driver for DB2 と組み合わせることで、Airflow からリアルタイムDB2 のデータに連携できます。 この記事では、Apache Airflow インスタンスからDB2 のデータに接続してクエリを実行し、結果をCSV ファイルに保存する方法を紹介します。
最適化されたデータ処理が組み込まれたCData JDBC Driver は、リアルタイムDB2 のデータを扱う上で高いパフォーマンスを提供します。 DB2 にSQL クエリを発行すると、CData ドライバーはフィルタや集計などのDB2 側でサポートしているSQL 操作をDB2 に直接渡し、サポートされていない操作(主にSQL 関数とJOIN 操作)は組み込みSQL エンジンを利用してクライアント側で処理します。 組み込みの動的メタデータクエリを使用すると、ネイティブのデータ型を使ってDB2 のデータを操作および分析できます。
DB2 への接続を構成する
組み込みの接続文字列デザイナー
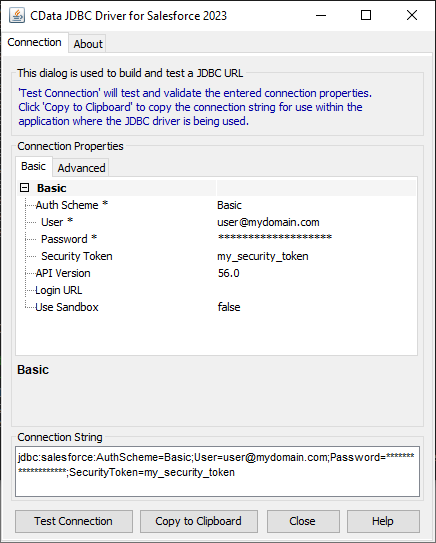
JDBC URL の作成の補助として、DB2 JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.db2.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
DB2 に接続するには以下のプロパティを設定します。
- Server: DB2 を実行するサーバー名。
- Port: DB2 サーバーのポート。
- Database: DB2 データベース名。
接続の準備ができたら、認証スキームを選択し、以下で説明するように適切なプロパティを設定します。
本製品 は、DB2 への認証に4つの異なるスキームをサポートします。DB2 ユーザー資格情報(デフォルト)、暗号化されたユーザー資格情報、IBM Identity and Access Management(IAM)認証、および Kerberos です。
DB2 ユーザー資格情報
ユーザー資格情報を使用して認証するには、次のプロパティを設定します。- AuthScheme:USRIDPWD。
- User:データベースへのアクセス権を持つユーザーのユーザー名。
- Password:データベースへのアクセス権を持つユーザーのパスワード。
暗号化されたユーザー資格情報
サーバーがセキュア認証に対応しており、暗号化されたユーザー資格情報を使用して認証を行いたい場合は、このプロパティを設定します。- AuthScheme:EUSRIDPWD
IAM、Kerberos で認証したい場合は、ヘルプドキュメントの「はじめに」セクションを参照してください。
パスワード方式によるSSH 接続
パスワード方式によるSSH接続時に必要なプロパティ一覧を以下に示します。
- User: DB2 のユーザ
- Password: DB2 のパスワード
- Database: DB2 の接続先データベース
- Server: DB2 のサーバー
- Port: DB2 のポート
- UserSSH: "true"
- SSHAuthMode: "Password"
- SSHPort: SSH のポート
- SSHServer: SSH サーバー
- SSHUser: SSH ユーザー
- SSHPassword: SSH パスワード
接続文字列形式では以下のようになります。
Server=10.0.1.2;Port=50000;User=admin;Password=admin;Database=testUseSSH=true;SSHAuthMode=Password;SSHPort=22;SSHServer=ssh-server;SSHUser=root;SSHPassword=sshpasswd;
公開鍵認証方式方式によるSSH 接続
公開鍵認証によるSSH接続時に必要なプロパティ一覧を以下に示します。
- User: DB2 のユーザ
- Password: DB2 のパスワード
- Database: DB2 の接続先データベース
- Server: DB2 のサーバー
- Port: DB2 のポート
- UserSSH: "true"
- SSHAuthMode: "Public_Key"
- SSHClientCertType: キーストアの種類
- SSHPort: SSH のポート
- SSHServer: SSH サーバー
- SSHUser: SSH ユーザー
- SSHClientCert: 秘密鍵ファイルのパス
接続文字列形式では以下のようになります。
Server=10.0.1.2;Port=50000;User=admin;Password=admin;Database=test;UseSSH=true;SSHAuthMode=Public_Key;SSHClientCertType=PUBLIC_KEY_FILE;SSHPort=22;SSHServer=ssh-server;SSHUser=root;SSHClientCert=C:\Keys\key.pem;
クラスタ環境またはクラウドでJDBC ドライバーをホストするには、ライセンス(フルまたはトライアル)およびランタイムキー(RTK)が必要です。本ライセンス(またはトライアル)の取得については、こちらからお問い合わせください。
以下は、JDBC 接続で要求される必須プロパティです。
| プロパティ | 値 |
|---|---|
| Database Connection URL |
jdbc:db2:RTK=5246...;Server=10.0.1.2;Port=50000;User=admin;Password=admin;Database=test;
|
| Database Driver Class Name | cdata.jdbc.db2.DB2Driver |
Airflow でJDBC 接続を確立する
- Apache Airflow インスタンスにログインします。
- Airflow インスタンスのナビゲーションバーで、「Admin」にカーソルを合わせ、「Connections」をクリックします。
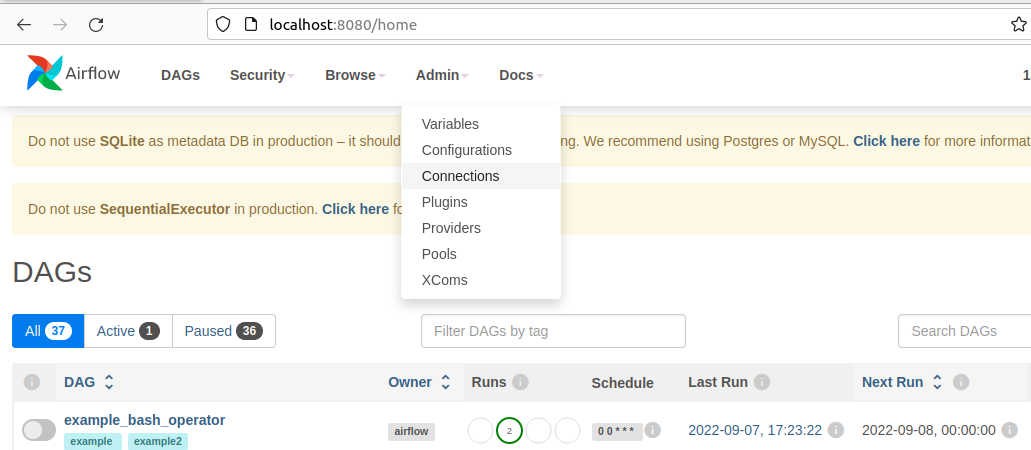
- 次の画面で「+」マークをクリックして新しい接続を作成します。
- Add Connection フォームで、必要な接続プロパティを入力します。
- Connection Id:接続の名前:db2_jdbc
- Connection Type:JDBC Connection
- Connection URL:上記のJDBC 接続URL:
jdbc:db2:RTK=5246...;Server=10.0.1.2;Port=50000;User=admin;Password=admin;Database=test; - Driver Class:cdata.jdbc.db2.DB2Driver
- Driver Path:PATH/TO/cdata.jdbc.db2.jar

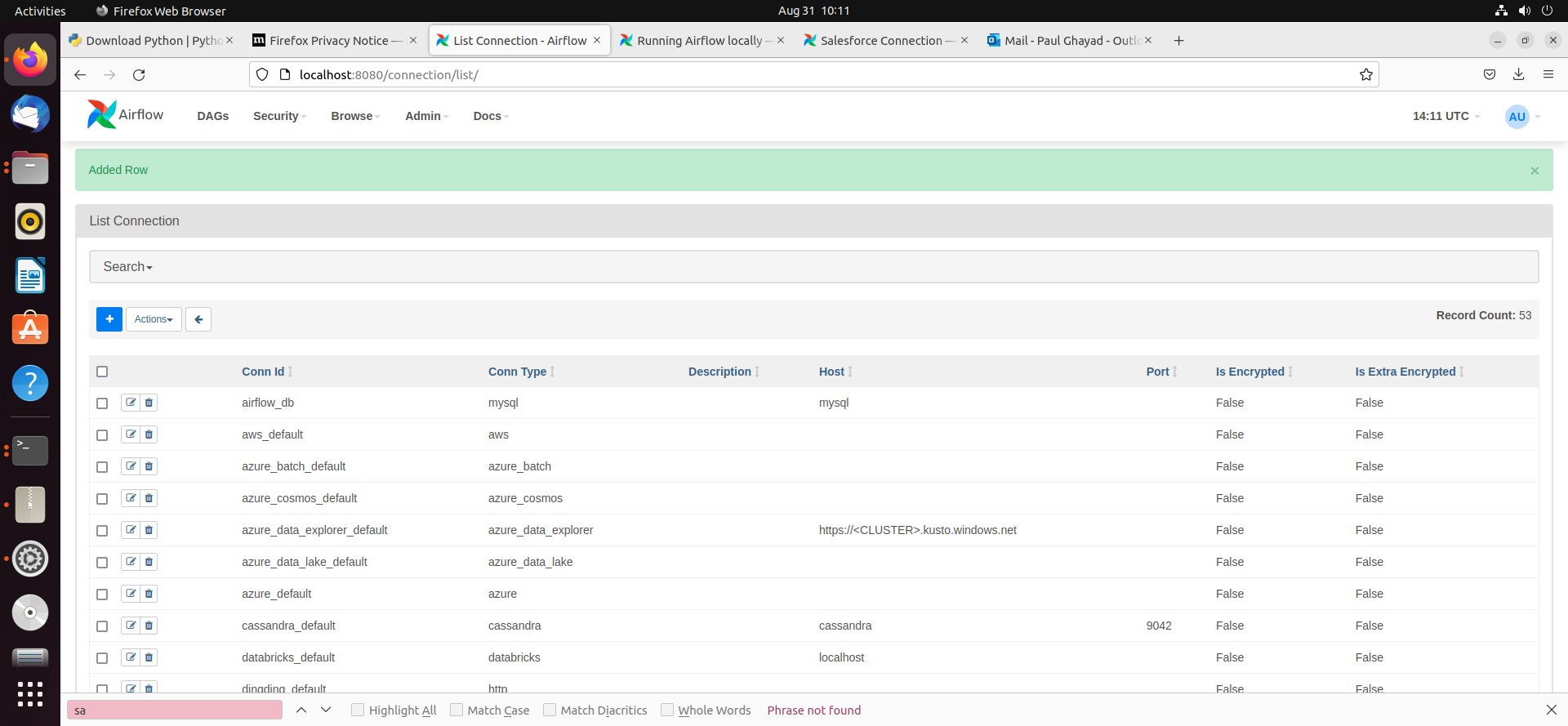
- フォームの下にある「Test」ボタンをクリックし、新規の接続をテストします。
- 新規接続を保存すると、新しく表示される画面に、接続リストに新しい行が追加されたことを示す緑のバナーが表示されます。
DAG を作成する
Airflow におけるDAG は、ワークフローのプロセスを格納するエンティティであり、DAG にトリガーを設定することでワークフローを実行することができます。 今回のワークフローでは、シンプルにDB2 のデータに対してSQL クエリを実行し、結果をCSV ファイルに格納します。
- はじめに、Home ディレクトリにある「airflow」フォルダに移動します。その中に新しいディレクトリを作成し、タイトルを「dags」とします。 ここに、UI に表示されるAirflow のDAG を構築するPython ファイルを格納します。
- 次に新しいPython ファイルを作成し、タイトルをdb2_hook.py にします。この新規ファイル内に、次のコードを挿入します。
import time from datetime import datetime from airflow.decorators import dag, task from airflow.providers.jdbc.hooks.jdbc import JdbcHook import pandas as pd # Dag の宣言 @dag(dag_id="db2_hook", schedule_interval="0 10 * * *", start_date=datetime(2022,2,15), catchup=False, tags=['load_csv']) # Dag となる関数を定義(取得するテーブルは必要に応じて変更してください) def extract_and_load(): # Define tasks @task() def jdbc_extract(): try: hook = JdbcHook(jdbc_conn_id="jdbc") sql = """ select * from Account """ df = hook.get_pandas_df(sql) df.to_csv("/{some_file_path}/{name_of_csv}.csv",header=False, index=False, quoting=1) # print(df.head()) print(df) tbl_dict = df.to_dict('dict') return tbl_dict except Exception as e: print("Data extract error: " + str(e)) jdbc_extract() sf_extract_and_load = extract_and_load() - このファイルを保存し、Airflow インスタンスをリフレッシュします。DAG リストの中に、「db2_hook」というタイトルの新しいDAG が表示されるはずです。

- このDAG をクリックし、新しく表示される画面で一時停止解除スイッチをクリックして青色にし、トリガー(=play)ボタンをクリックしてDAG を実行します。この操作で、db2_hook.py ファイルのSQL クエリを実行し、結果をCSV としてコード内で指定したファイルパスにエクスポートします。

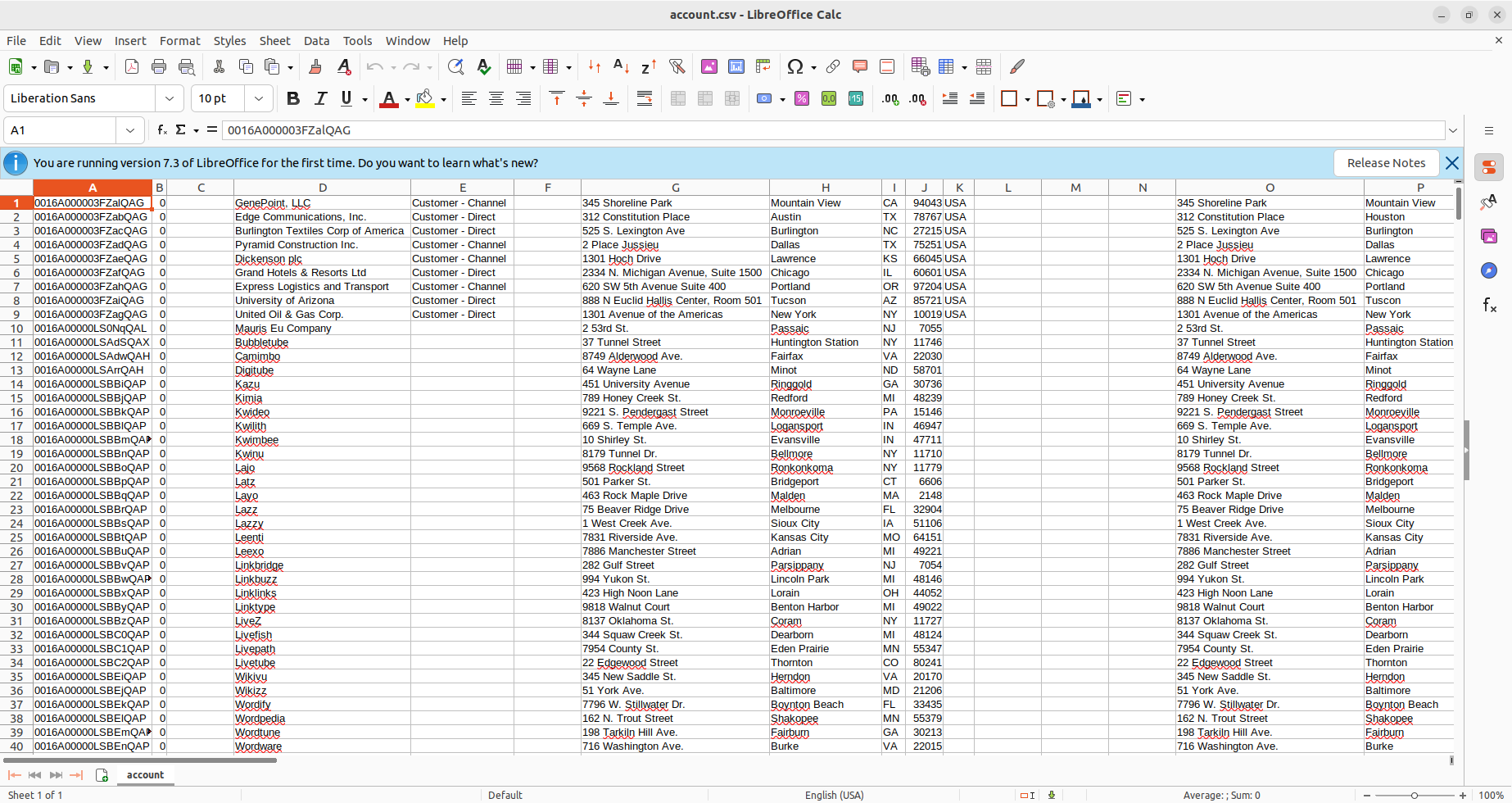
- 新規のDAG を実行後、Downloads フォルダ(またはPython スクリプト内で選択したフォルダ)を確認し、CSV ファイルが作成されていることを確認します(本ワークフローの場合はaccount.csv です)。
- CSV ファイルを開くと、Apache Airflow によってDB2 のデータがCSV 形式で利用できるようになったことが確認できます。