各製品の資料を入手。
詳細はこちら →



製品をチェック
IntelliJ からSpark のデータに連携
IntelliJ のウィザードを使用してSpark への接続を統合します。
最終更新日:2022-04-25
この記事で実現できるSpark 連携のシナリオ


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL を使用することで、JDBC データソースとしてSpark にアクセスでき、IDE の迅速な開発ツールとの統合が可能になります。この記事では、データソース構成ウィザードを使用してIntelliJ のSpark に接続する方法を示します。
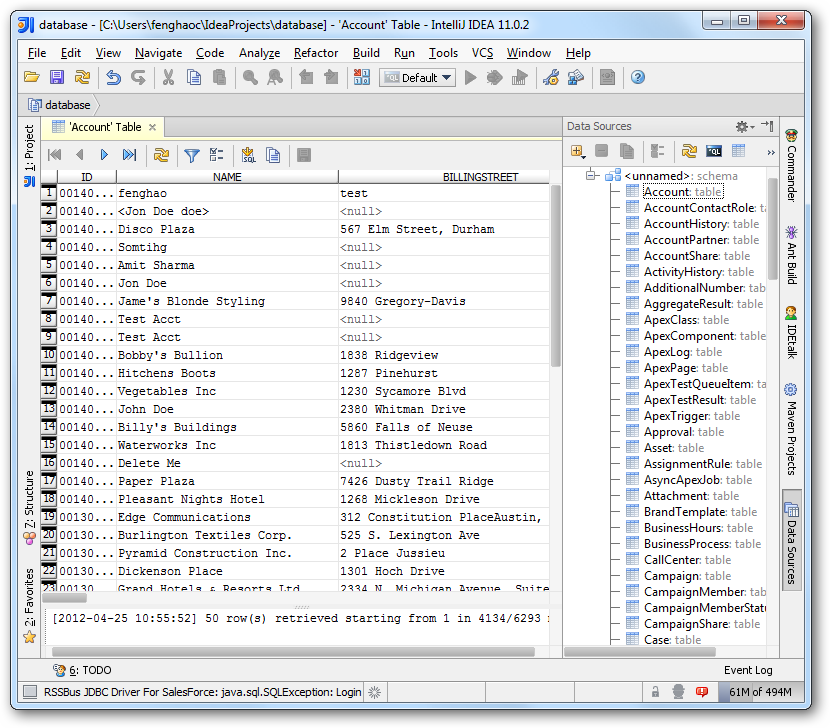
JBDC Data Source for SparkSQL の作成
以下のステップに従ってドライバーJAR を追加し、Spark への接続に必要な接続プロパティを定義します。
- [Data Sources]ウィンドウで右クリックし、[Add Data Source]->[DB Data Source]と進みます。
表示される[Data Source Properties]ダイアログでは、次のプロパティが必要です。
- JDBC Driver Files:このメニューの隣にあるボタンをクリックし、インストールディレクトリのJDBC ドライバーファイル(cdata.jdbc.sparksql.jar)を追加します。
- JDBC Driver Class:このメニューで、リストからcdata.jdbc.sparksql.SparkSQL ドライバーを選択します。
Database URL:JDBC URL プロパティで接続URL を入力します。URL は、jdbc:sparksql: で始まり、セミコロンで区切られた接続プロパティが含まれています。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
ビルトイン接続文字列デザイナ
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar接続プロパティを入力し、接続文字列をクリップボードにコピーします。
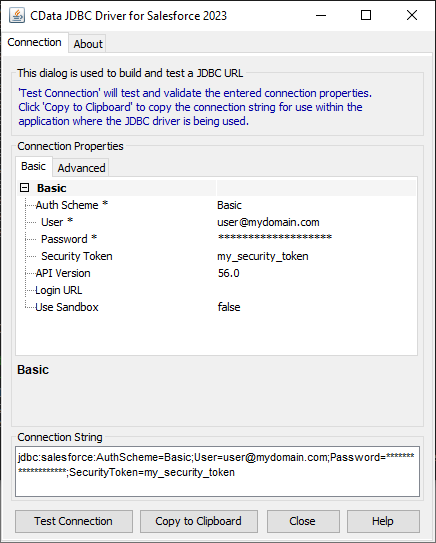
以下は一般的なJDBC URL です。
jdbc:sparksql:Server=127.0.0.1;
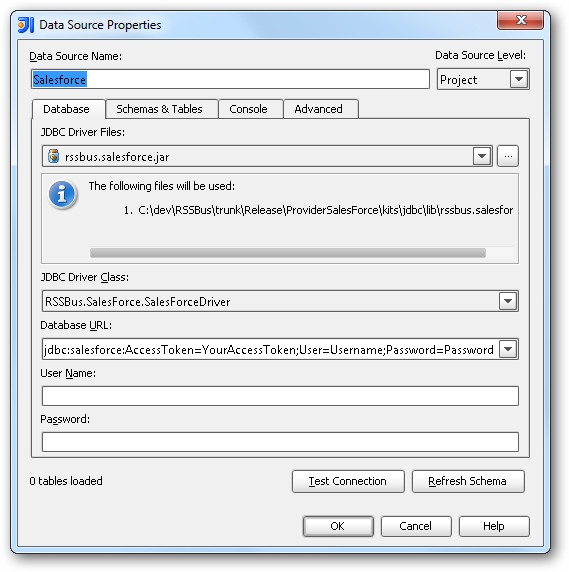
Spark のデータの編集・保存
スキーマ情報を見つけるには、作成したデータソースを右クリックし、[Refresh Tables]をクリックします。 テーブルを右クリックし、[Open Tables Editor]をクリックして、テーブルをクエリします。 また、[Table Editor]でレコードを編集することもできます。