各製品の資料を入手。
詳細はこちら →



製品をチェック
Squirrel SQL Client からSpark のデータに連携
Spark に接続し、Squirrel SQL Client でクエリを実行します。
最終更新日:2022-10-03
この記事で実現できるSpark 連携のシナリオ


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData JDBC Driver for SparkSQL を使用して、Squirrel SQL Client などのツールでSpark へのクエリを実行できます。この記事では、JDBC data source for SparkSQL を作成し、クエリを実行します。
JDBC Driver for SparkSQL を追加する
以下のステップに従ってドライバーJAR を追加します。
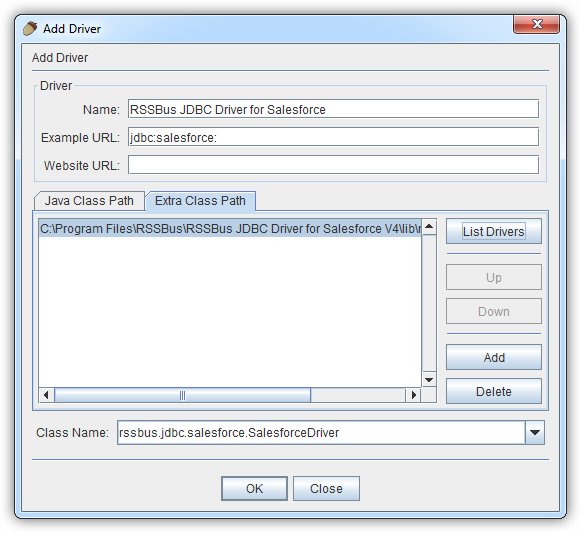
- Squirrel SQL で[Windows]->[View Drivers]と進みます。
- プラスアイコンをクリックし、[Add Driver]ウィザードを開きます。
- [Name]ボックスで、CData JDBC Driver for SparkSQL のようなドライバーのわかりやすい名前を入力します。
- [Example URL]ボックスで、jdbc:sparksql: と入力します。
- [Extra Class Path]タブで[Add]をクリックします。
- 表示される[file explorer]ダイアログで、インストールディレクトリのlib サブフォルダにあるドライバーのJAR ファイルを選択します。
- [List Drivers]をクリックして[Class Name]メニューにドライバーのクラス名(cdata.jdbc.sparksql.SparkSQLDriver) を入力します。
接続プロパティを定義する
以下のステップに従って、接続プロパティをドライバーエイリアスに保存します。
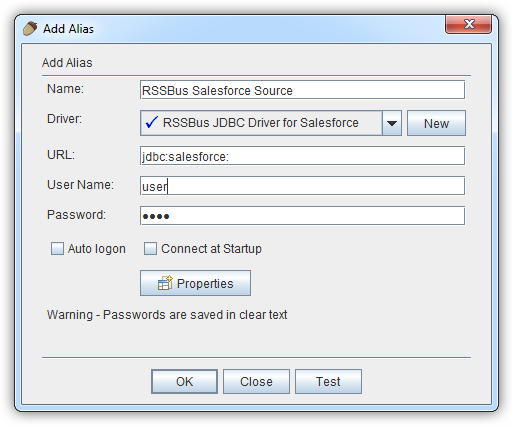
- [Windows]->[View Aliases]と進みます。
- エイリアスが一覧表示されているペインで、プラスアイコンをクリックします。
表示される[Add Alias]ウィザードで、JDBC ドライバーには以下のフィールドが要求されます。
- Name:CData Spark Source のようなエイリアスの名前を入力します。
- Driver:CData JDBC Driver for SparkSQL を選択します。
- URL:jdbc:sparksql: と入力します。
- 追加のプロパティを定義する場合は、[Properties]をクリックします。
- 表示されるダイアログの[Driver properties]タブで、[Use driver properties]のチェックボックスを選択します。
- [Specify]カラムで必要な接続プロパティのチェックボックスを選択します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
以下は一般的な接続文字列です。
jdbc:sparksql:Server=127.0.0.1;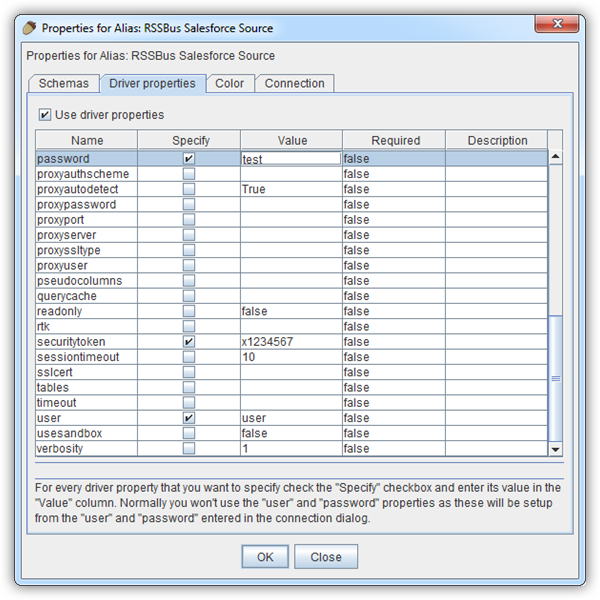
- [OK]をクリックし、表示されるダイアログで[connect]をクリックして接続を確認します。
スキーマを検出しSpark のデータをクエリする
メタデータが読み込まれると、Spark のデータソースの新しいタブが表示されます。[Objects]サブタブでは、使用可能なテーブルやビューなどのスキーマ情報を見つけることができます。
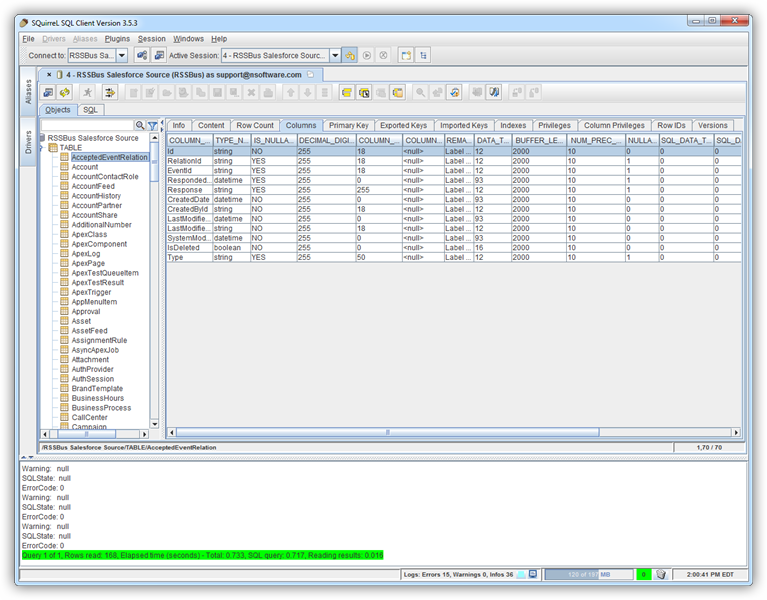
テーブルデータを表示するには[Objects]タブでテーブルを選択します。その後、テーブルデータが[Content]タブのグリッドに読み込まれます。
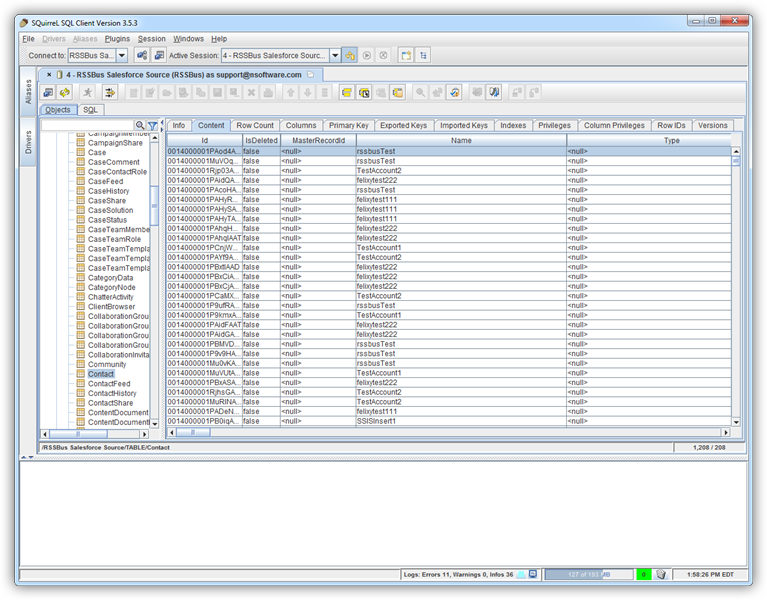
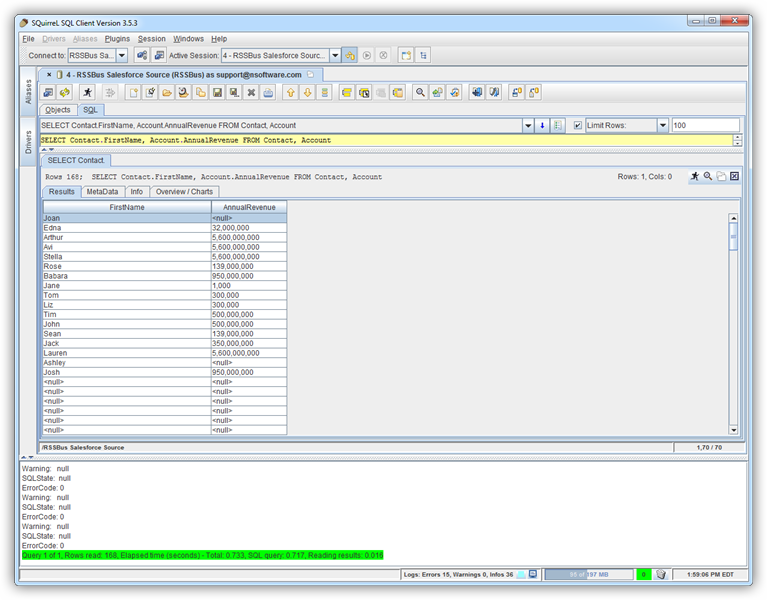
SQL クエリを実行するには、[SQL]タブにクエリを入力し、[Run SQL](ランナーアイコン)をクリックします。例:
SELECT City, Balance FROM Customers