各製品の資料を入手。
詳細はこちら →



AppSheet でSpark のデータと連携するアプリを作成する方法
CData Connect Cloud を使ってAppSheet からSpark に接続、Spark のリアルタイムデータを使ってカスタムビジネスアプリを作成します。
最終更新日:2023-09-01
この記事で実現できるSpark 連携のシナリオ


こんにちは!プロダクトスペシャリストの宮本です。
AppSheet はアプリケーション作成用のローコード / ノーコード開発プラットフォームで、ユーザーはモバイル、タブレット、Web アプリケーションを自在に作成できます。 さらにCData Connect Cloud と連携することで、ビジネスアプリケーションにSpark のデータへのクラウドベースのアクセスを即座に追加できます。今回はConnect Cloud からSpark に接続して、AppSheet でSpark のデータを使った可視化を作成してみたので、その方法を説明します!
CData Connect Cloud とは?
CData Connect Cloud は、以下のような特徴を持ったクラウド型のリアルタイムデータ連携製品です。
- SaaS やクラウドデータベースを中心とする150種類以上のデータソース
- BI、アナリティクス、ETL、ローコードツールなど30種類以上のツールやアプリケーションから利用可能
- リアルタイムのデータ接続に対応。データの複製を作る必要はありません
- ノーコードでシンプルな設定
詳しくは、こちらの製品資料をご確認ください。
Connect Cloud アカウントの取得
以下のステップを実行するには、CData Connect Cloud のアカウントが必要になります。こちらから製品の詳しい情報とアカウント作成、30日間無償トライアルのご利用を開始できますので、ぜひご利用ください。
Connect Cloud からSpark への接続
CData Connect Cloud では、直感的なクリック操作ベースのインターフェースを使ってデータソースに接続できます。
- Connect Cloud にログインし、 「Add Connection」をクリックします。
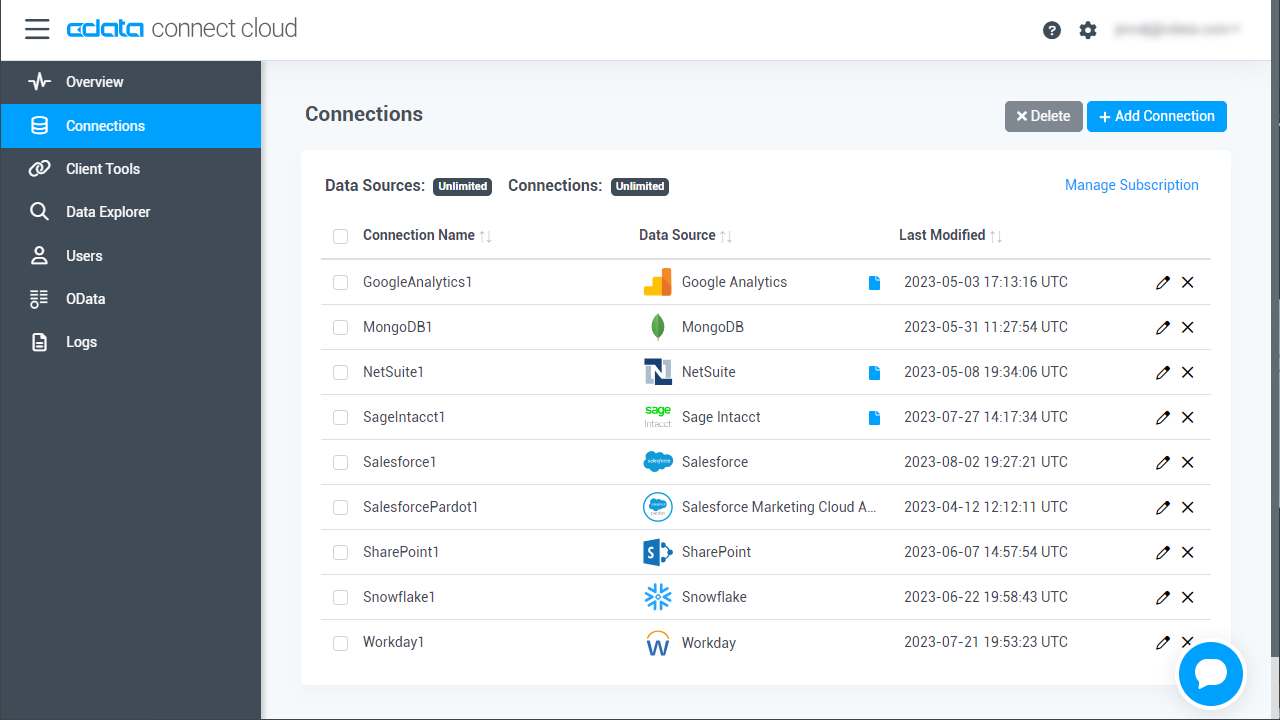
- Add Connection パネルから「Spark」を選択します。
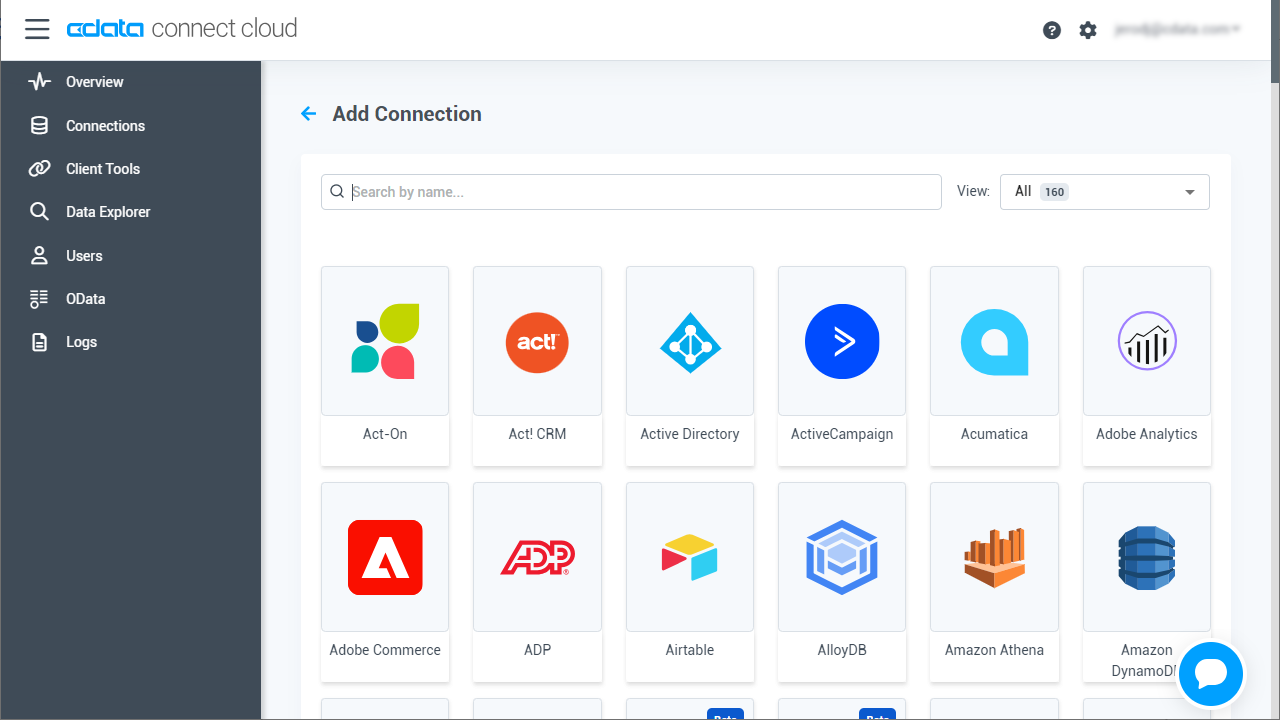
-
必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
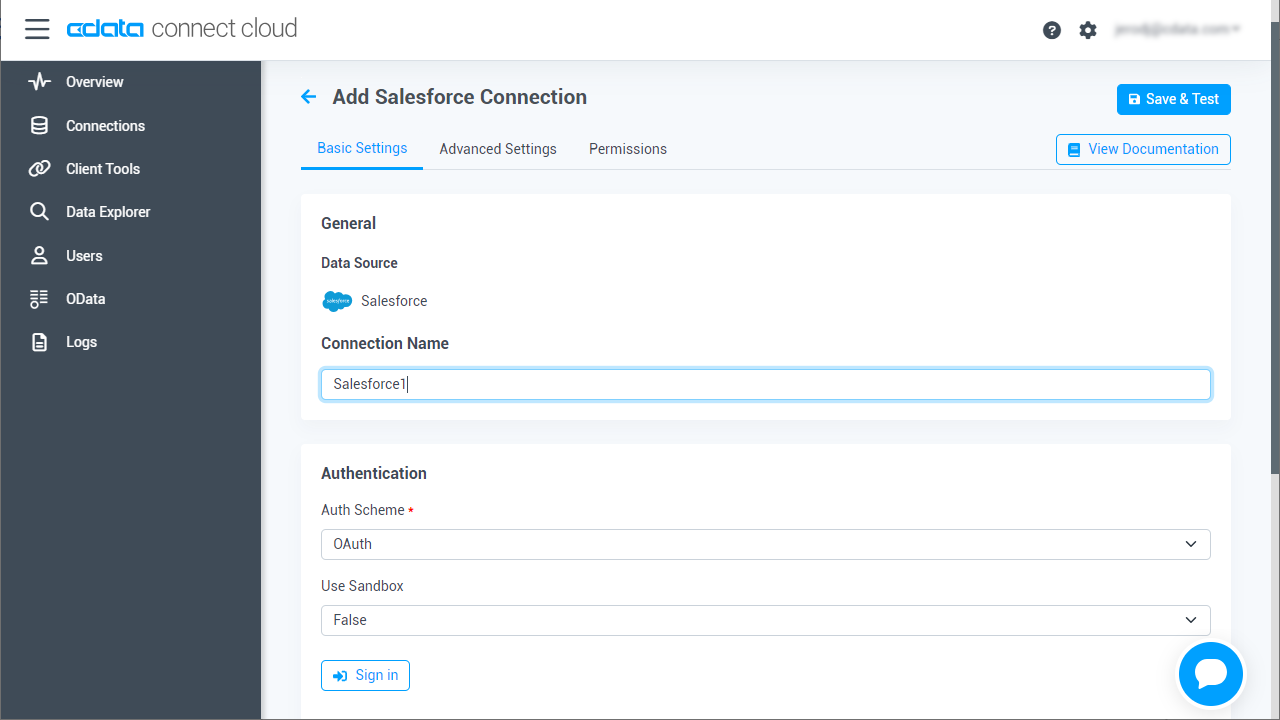
- Create & Test をクリックします。
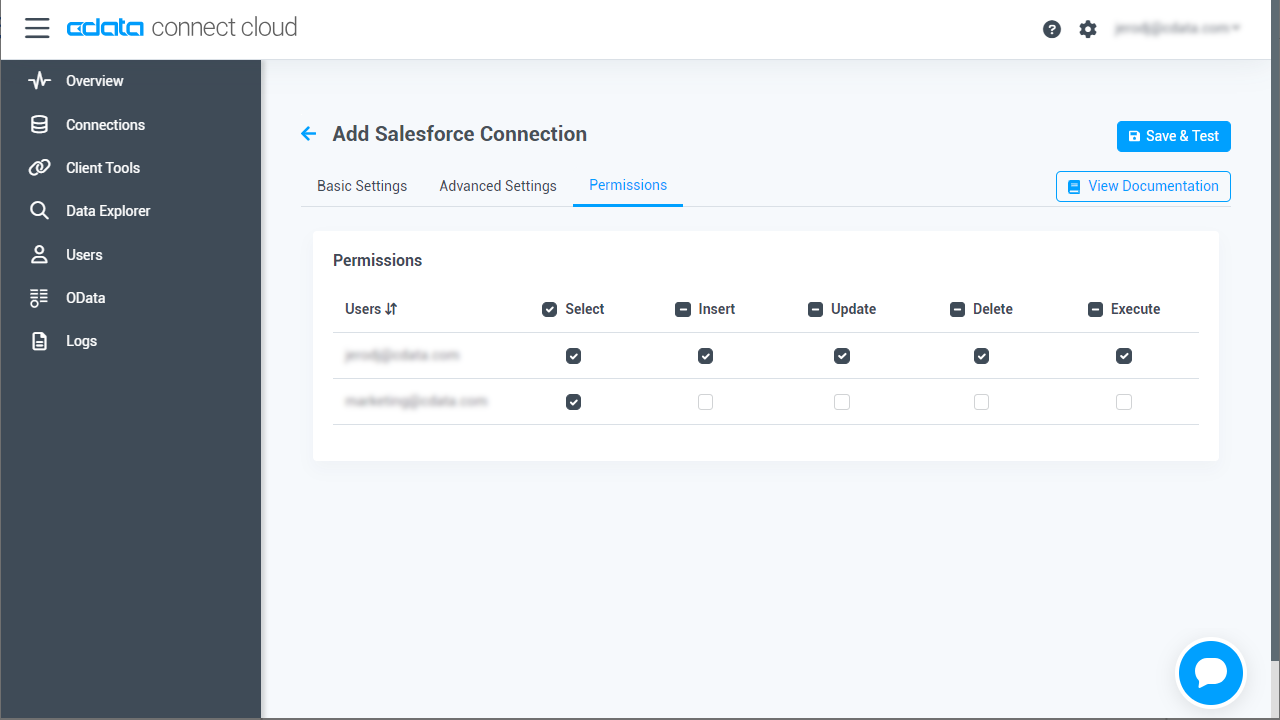
- (オプション)「Add Spark Connection」ページの「Permissions」タブに移動し、ユーザーベースのアクセス許可を更新します。
(オプション)パーソナルアクセストークンの追加
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
- Connect Cloud アプリの右上にあるユーザー名をクリックし、「Settings」をクリックします。
- 「Settings」ページで「Access Token」セクションにスクロールし、 Create PAT をクリックします。
- PAT の名前を入力して Create をクリックします。
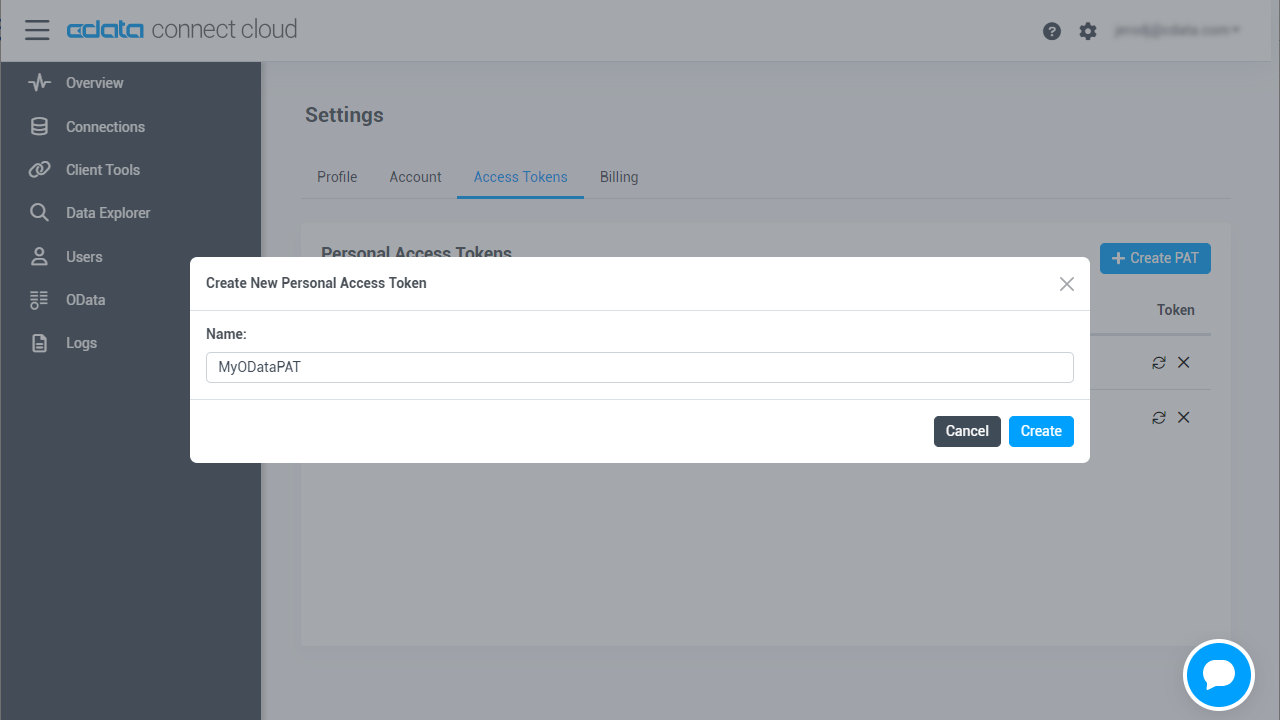
- パーソナルアクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
コネクションの設定が完了したら、AppSheet からSpark のデータへの接続準備は完了です。ノーコードで簡単にSpark に接続できますね!もし設定でご不明点などあれば、こちらのフォームよりお気軽にお問い合わせください。
AppSheet からSpark への接続
それでは、以下のステップではAppSheet からCData Connect Cloud に接続して新しいSpark のデータソースを作成する方法を説明します。
- AppSheet にログインします。
- メニューの「Account settings」をクリックします。
- 「Sources」タブをクリックして、「+New Data Source」ボタンから新しいデータソースを追加します。
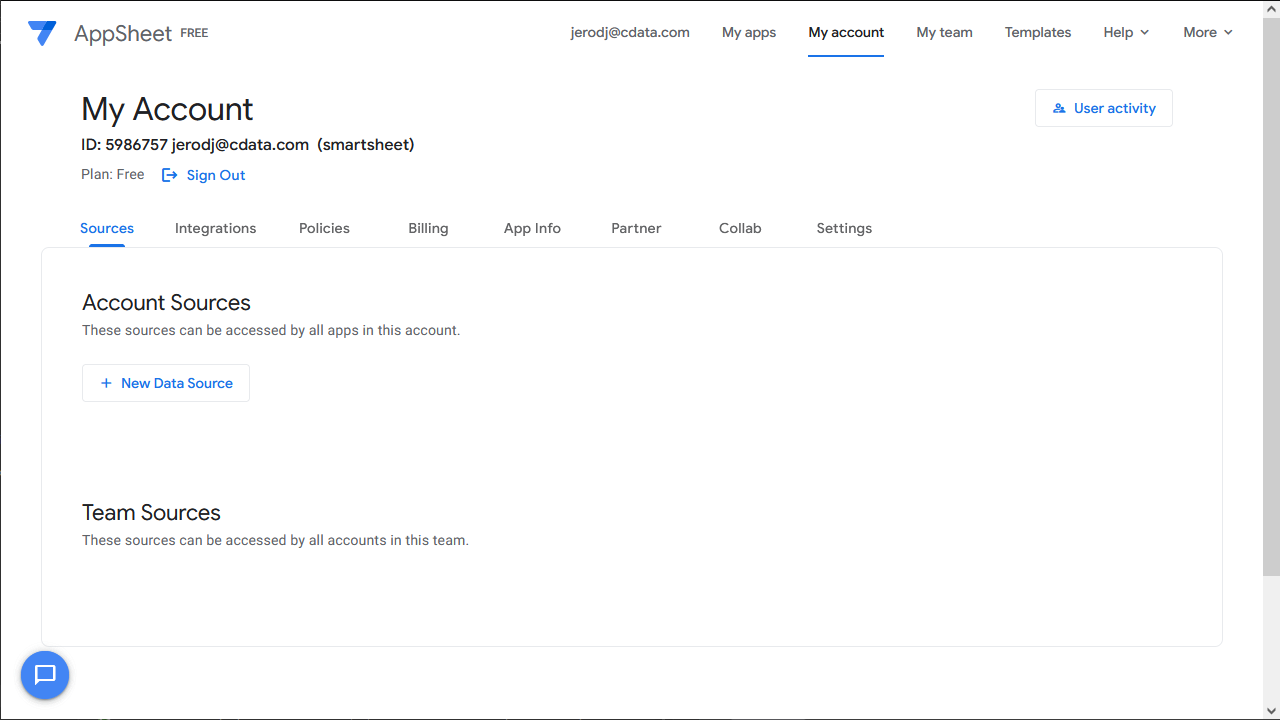
- 「Cloud Database」をクリックして接続先情報を入力します。
- Type:SQL Server
- Server:tds.cdata.com,14333
- Database:Spark のコネクション名(例:SparkSQL1)。
- Username:Connect Cloud のユーザー名(例:user@mydomain.com)。
- Password:入力したConnect Cloud ユーザーのPAT を指定。
- SSL:Require SSL
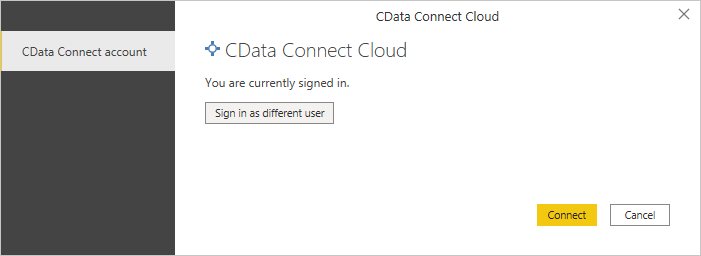
- 「Test」をクリックします。
- 「Authorize Access」をクリックします。
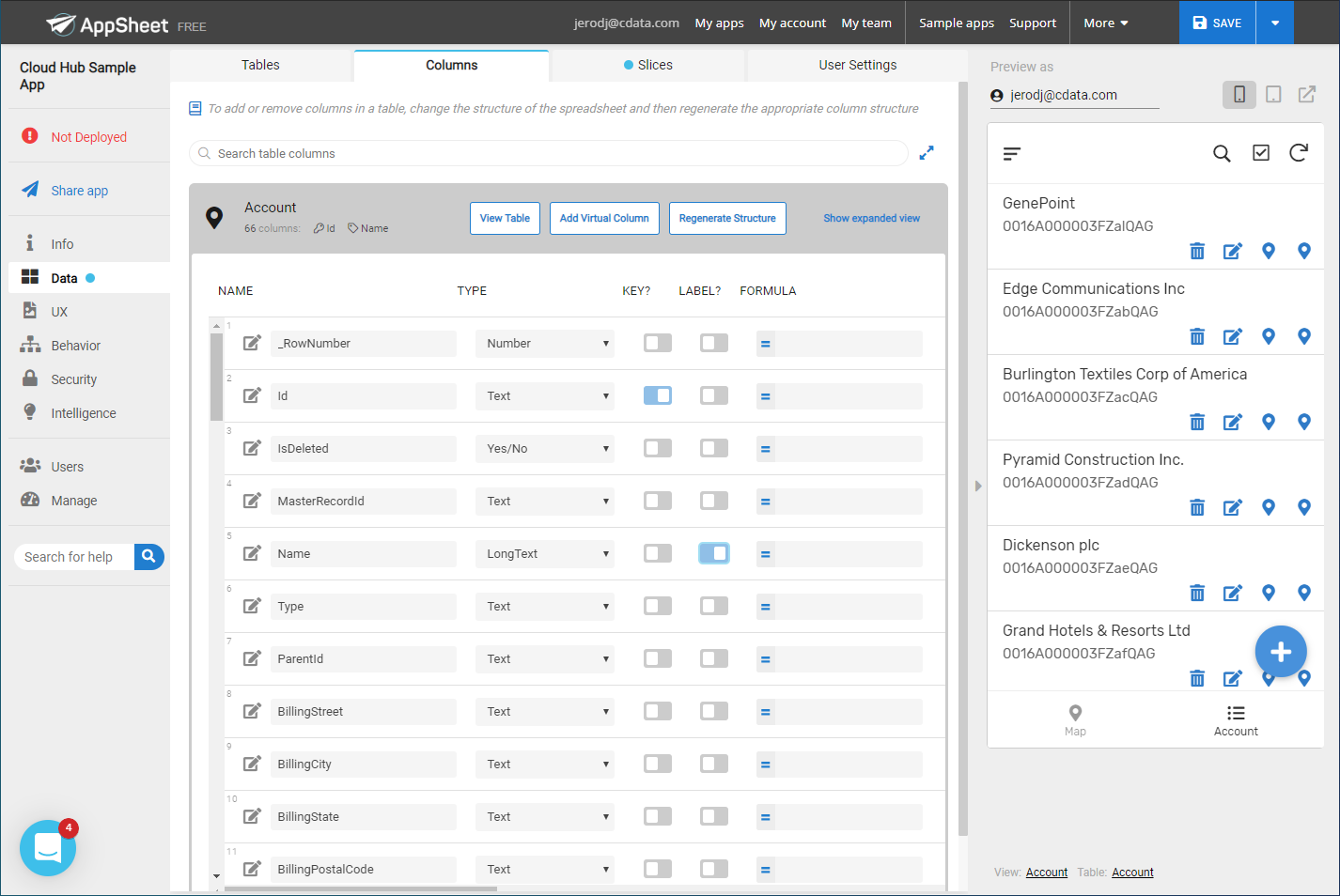
AppSheet でアプリを作る
Spark のデータソースを作成したら、Spark のデータを使ったアプリを構築できます。まずはメニューの「My apps」をクリックしましょう。
- 「Create」->「App」->「Start with existing data」の順にクリックして、新しいアプリの作成を始めます。
- 任意のアプリ名を入力して、使用するデータに基づく適切なカテゴリを設定します。
- 先ほど作成したデータソースを選択します。
- 次の画面で、データソースのテーブルとビューの一覧を確認できます。アプリ作成で使用したいデータを選択してください。
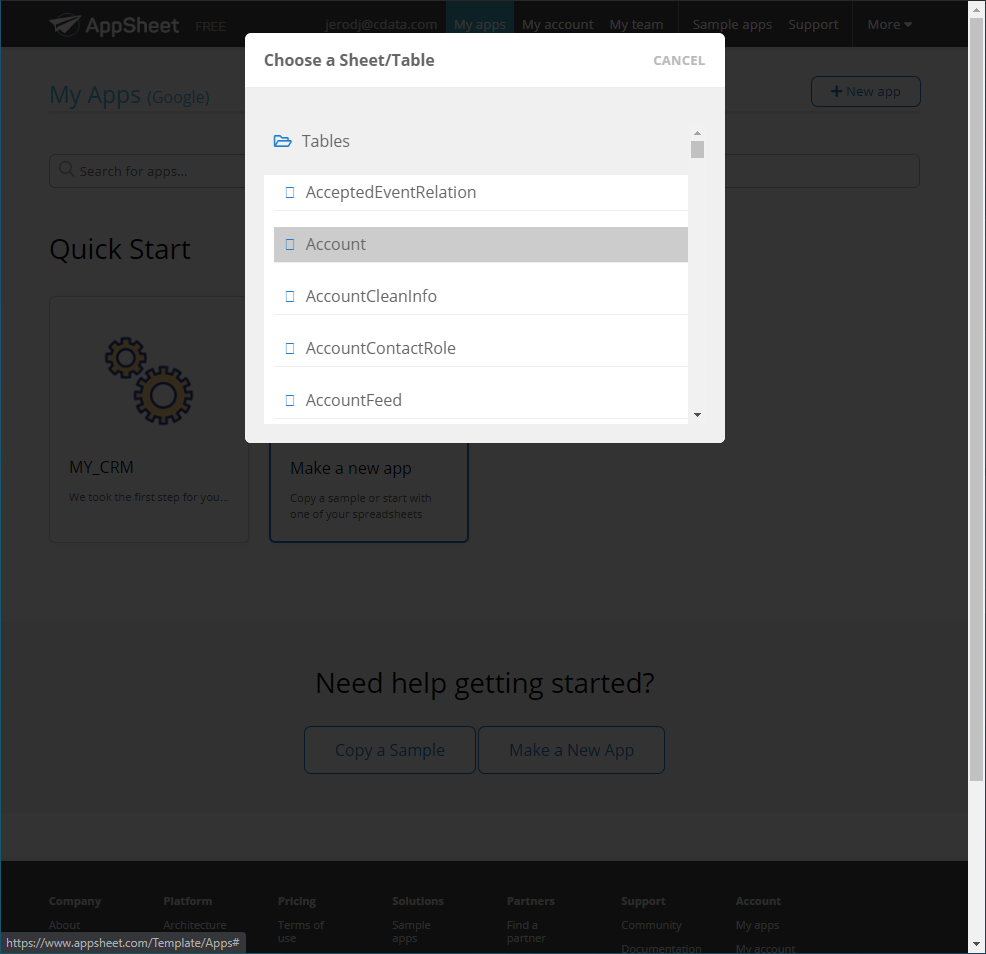
この段階で、アプリのデザインを変更したり、選択したテーブルのどのカラムを表示、またはテーブルとして使用するか、といったことを設定できます。右側のプレビューパネルでアプリをプレビューして、良さそうであればパブリッシュします。
CData Connect Cloud の30日間無償トライアルを利用して、クラウドアプリケーションから直接100を超えるSaaS 、ビッグデータ、NoSQL データソースへのSQL アクセスをお試しください!