各製品の資料を入手。
詳細はこちら →



クラウドRPA Coopel でSpark のデータを利用したシナリオを作成
CData Connect Cloud を使ってCoopel でSpark のデータを使ったシナリオを作成します。
最終更新日:2022-11-17
この記事で実現できるSpark 連携のシナリオ


こんにちは!リードエンジニアの杉本です。
Coopel は DeNA 社が提供するクラウドベースのRPA サービスです。WebブラウザやExcel、SaaS などのクラウドサービスの操作の自動化が実現できます。この記事では、CData Connect Cloud を経由して Coopel からSpark のデータを取得し活用する方法を説明します。
CData Connect Cloud はSpark のデータへのクラウドベースのOData インターフェースを提供し、Coopel からSpark のデータへのリアルタイム連携を実現します。
Connect Cloud アカウントの取得
以下のステップを実行するには、CData Connect Cloud のアカウントが必要になります。こちらから製品の詳しい情報とアカウント作成、30日間無償トライアルのご利用を開始できますので、ぜひご利用ください。
Connect Cloud を構成
Coopel でSpark のデータを操作するには、Connect Cloud からSpark に接続し、コネクションにユーザーアクセスを提供してSpark のデータのOData エンドポイントを作成する必要があります。
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
(オプション)新しいConnect Cloud ユーザーの追加
必要であれば、Connect Cloud 経由でSpark に接続するユーザーを作成します。
- 「Users」ページに移動し、 Invite Users をクリックします。
- 新しいユーザーのE メールアドレスを入力して、 Send をクリックしてユーザーを招待します。
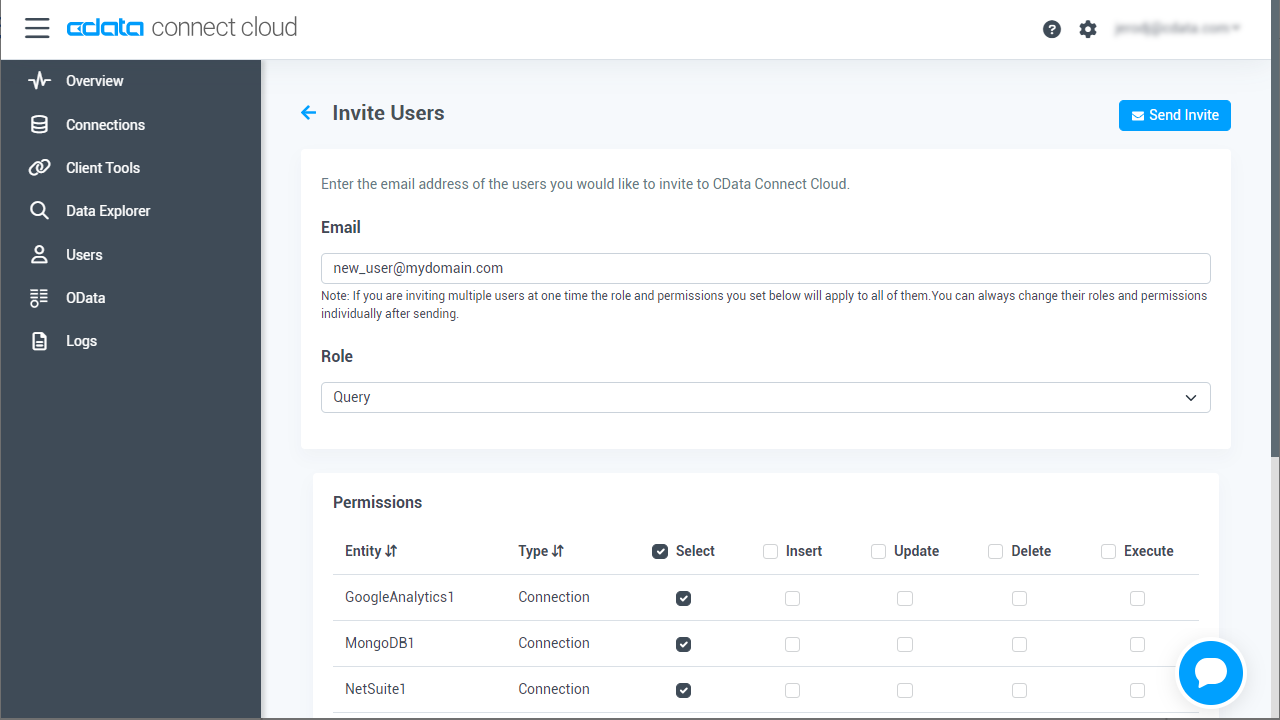
- 「Users」ページからユーザーを確認および編集できます。
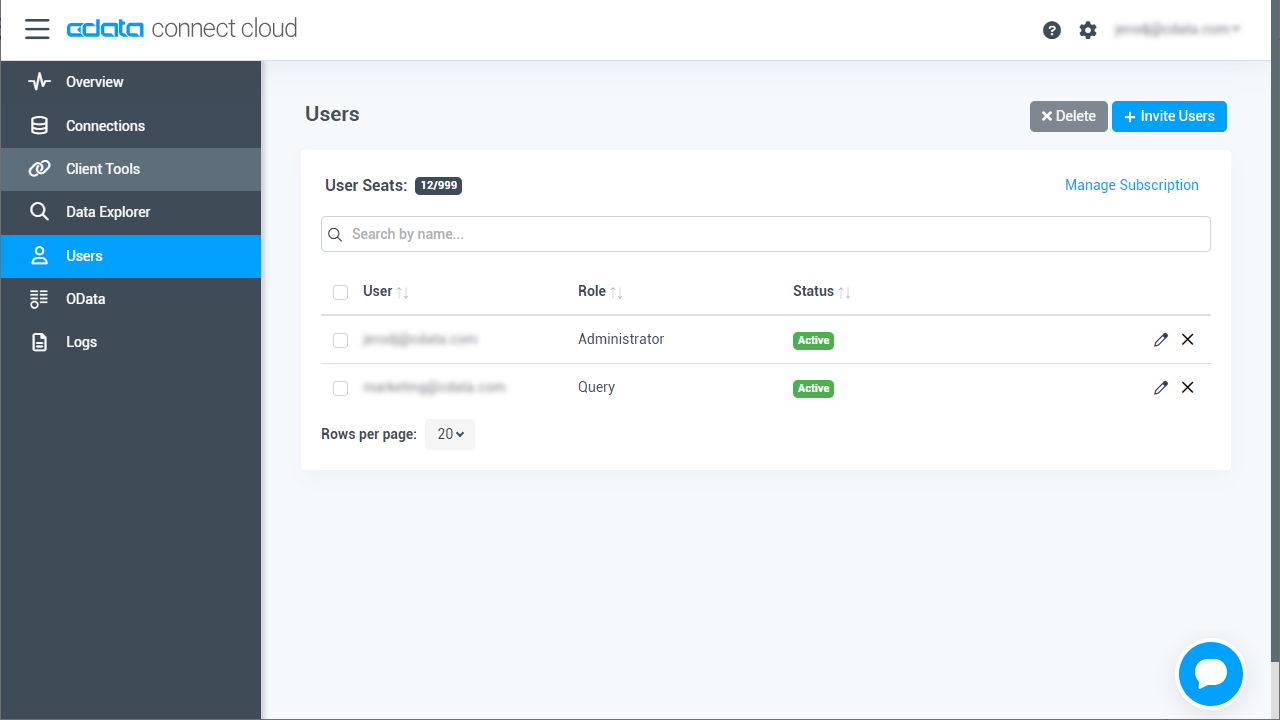
パーソナルアクセストークン(PAT)の追加
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
- Connect Cloud アプリの右上にあるユーザー名をクリックし、「User Profile」をクリックします。
- 「User Profile」ページで「Access Token」セクションにスクロールし、 Create PAT をクリックします。
- PAT の名前を入力して Create をクリックします。
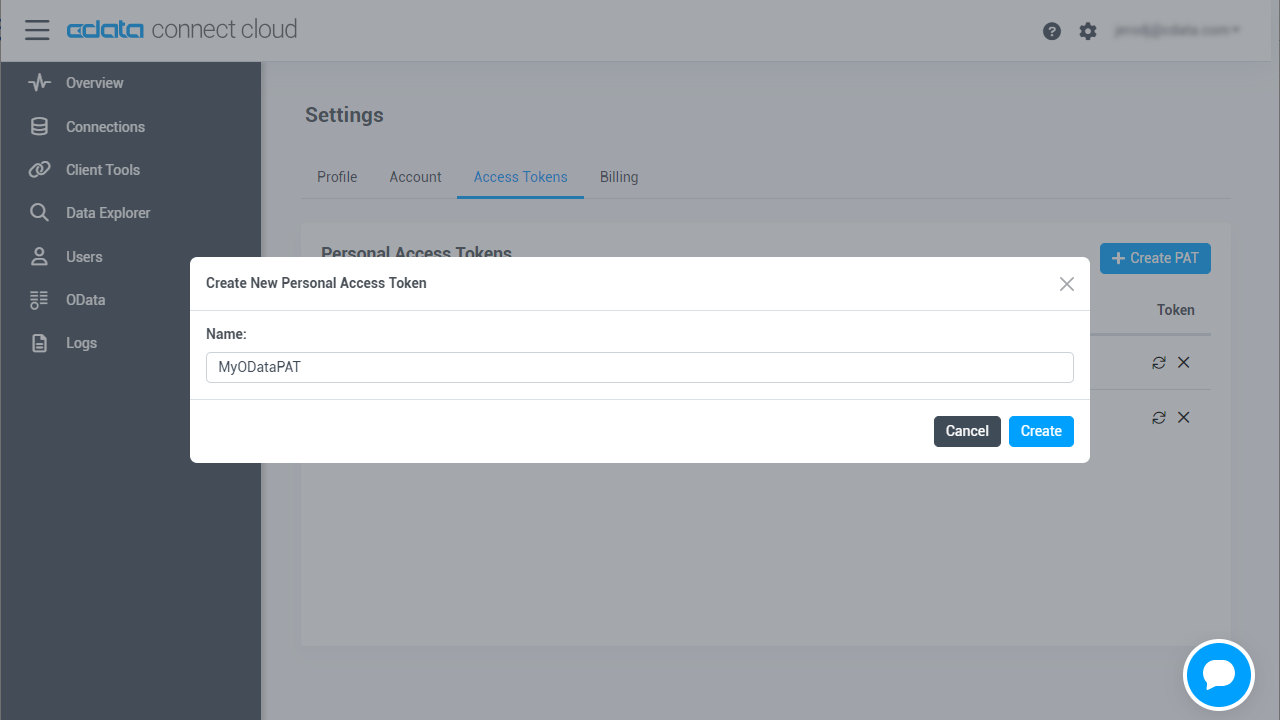
- パーソナルアクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
Connect Cloud からSpark に接続
CData Connect Cloud では、簡単なクリック操作ベースのインターフェースでデータソースに接続できます。
- Connect Cloud にログインし、 Add Connection をクリックします。
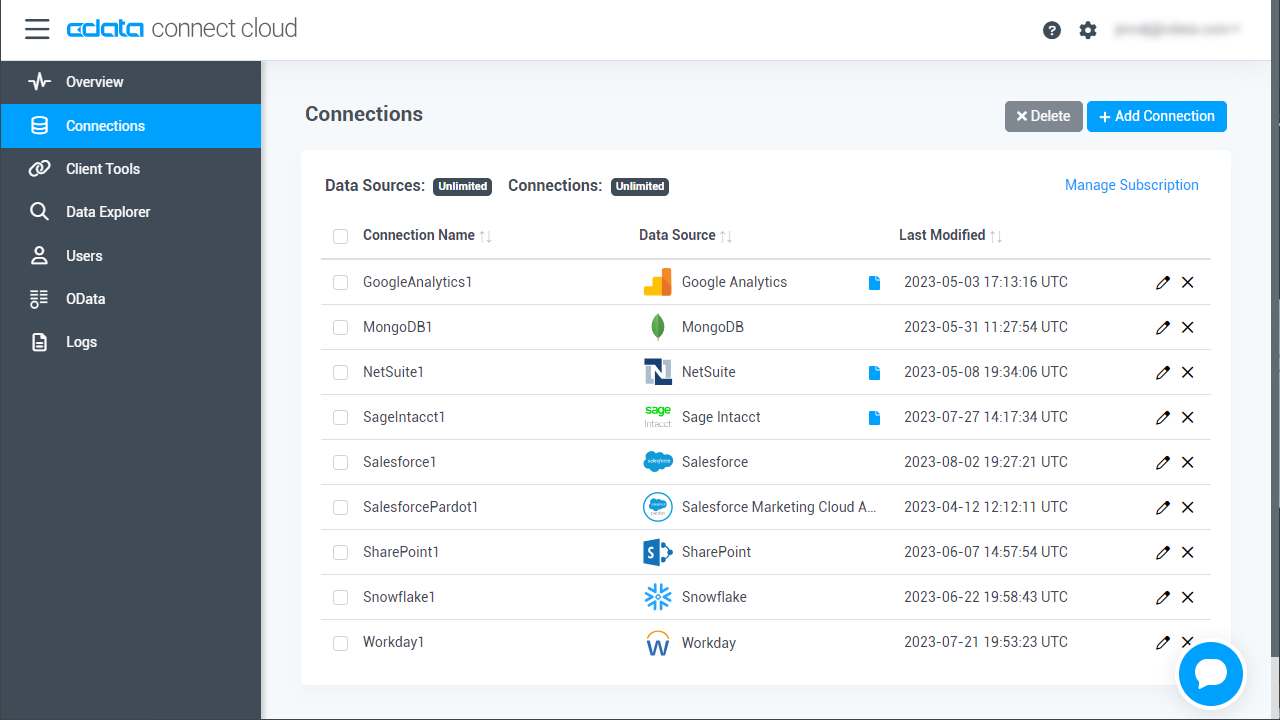
- 「Add Connection」パネルから「Spark」を選択します。
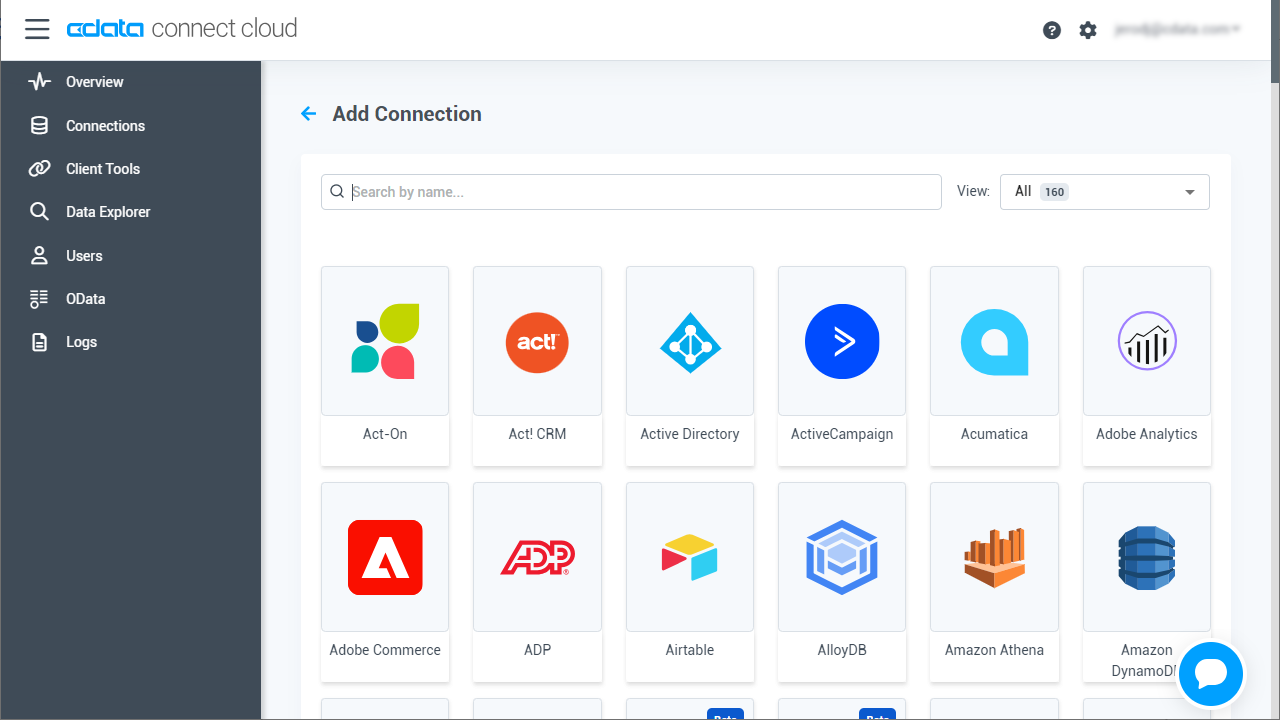
-
必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
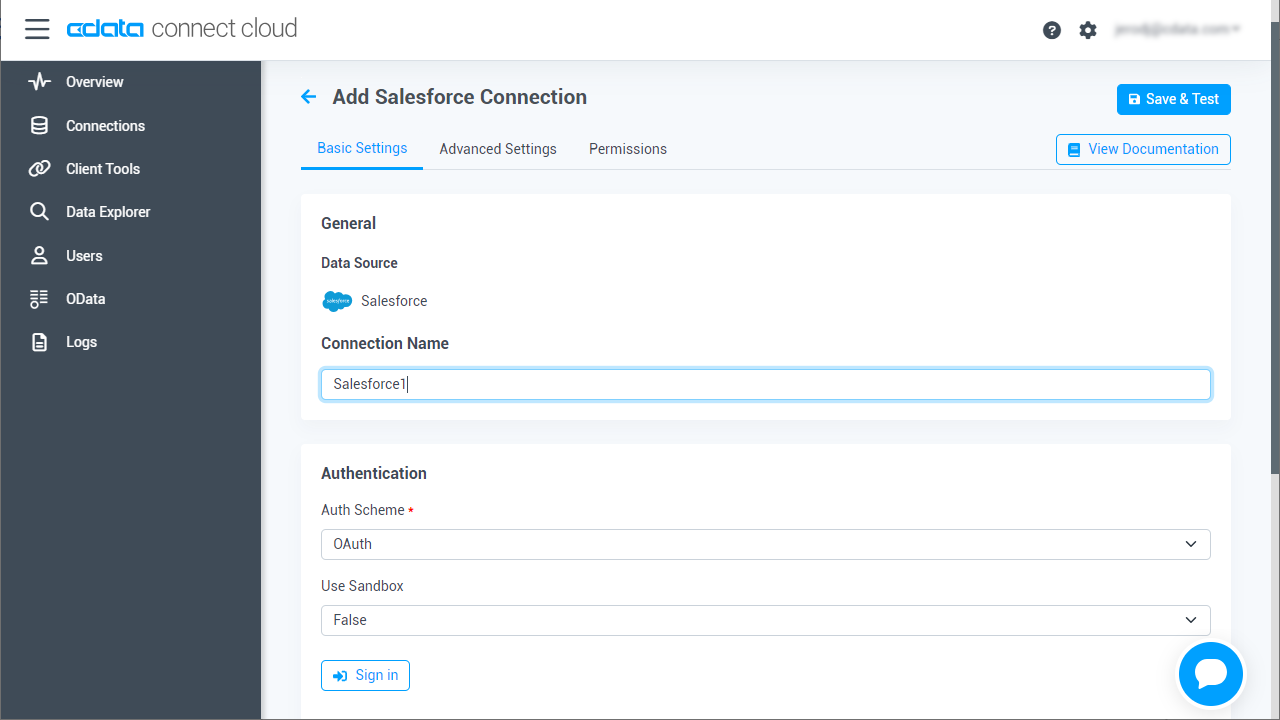
- Create & Test をクリックします。
- 「Add Spark Connection」ページの「Permissions」タブに移動し、ユーザーベースのアクセス許可を更新します。
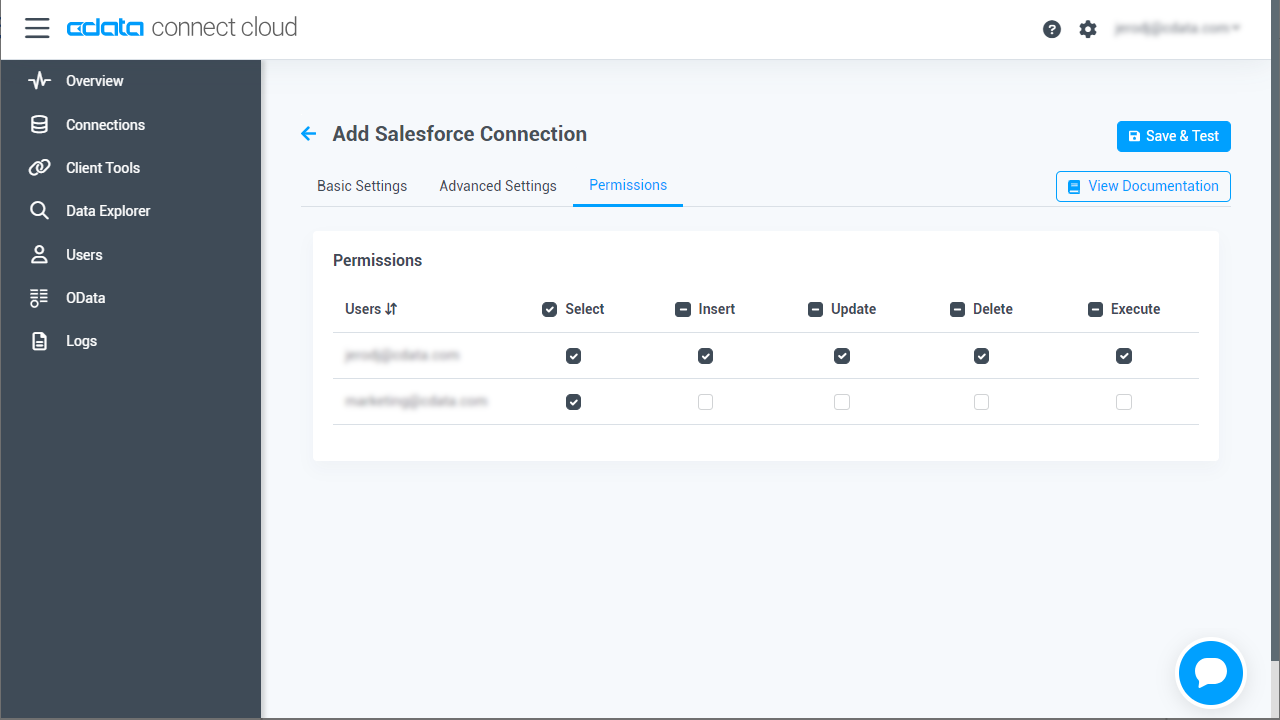
Connect Cloud にSpark OData エンドポイントを追加する
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
- OData ページに移動し、 Add をクリックして新しいOData エンドポイントを作成します。
- Spark 接続(例:SparkSQL1)を選択し、Next をクリックします。
- 使用するテーブルを選択し、「Confirm」をクリックします。
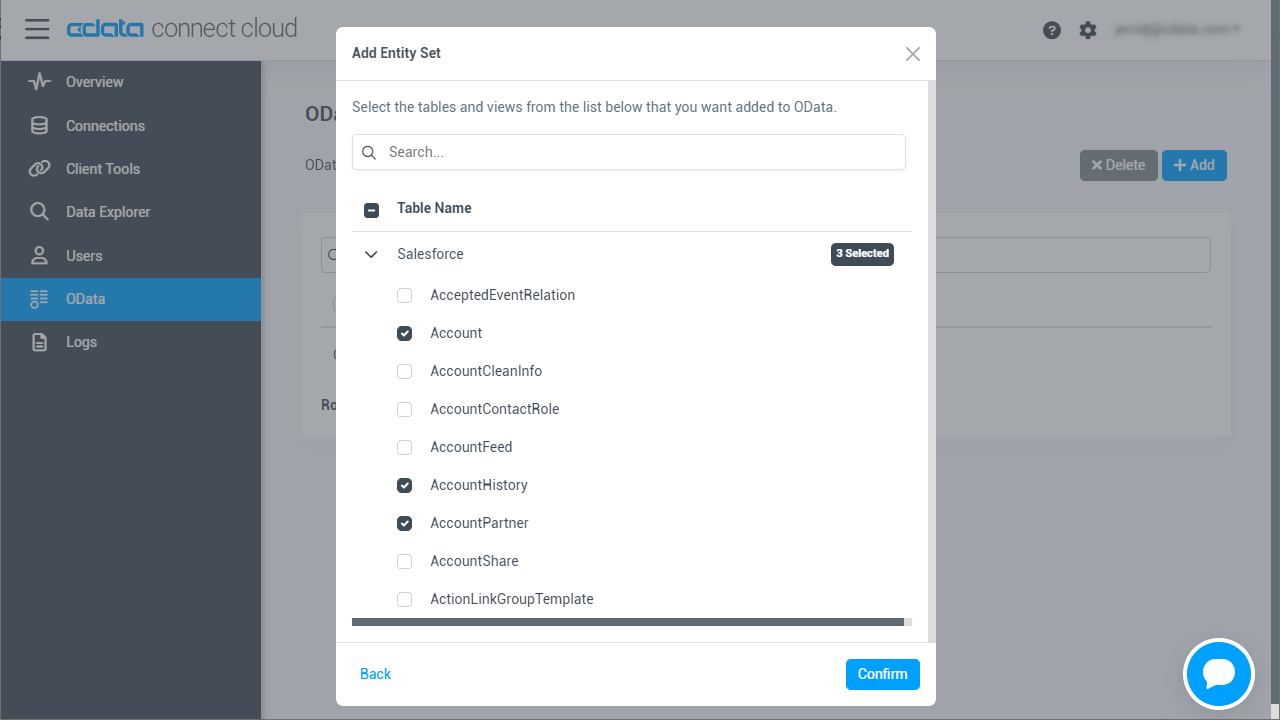
コネクションとOData エンドポイントを設定したら、Coopel からSpark のデータに接続できます。
Coopel でシナリオを作成する
CData Connect cloud 側の準備が完了したら、早速Coopel 側でシナリオの作成を開始します。
- まず、Coopel にログインし、必要に応じて新しいワークスペースを作成します。
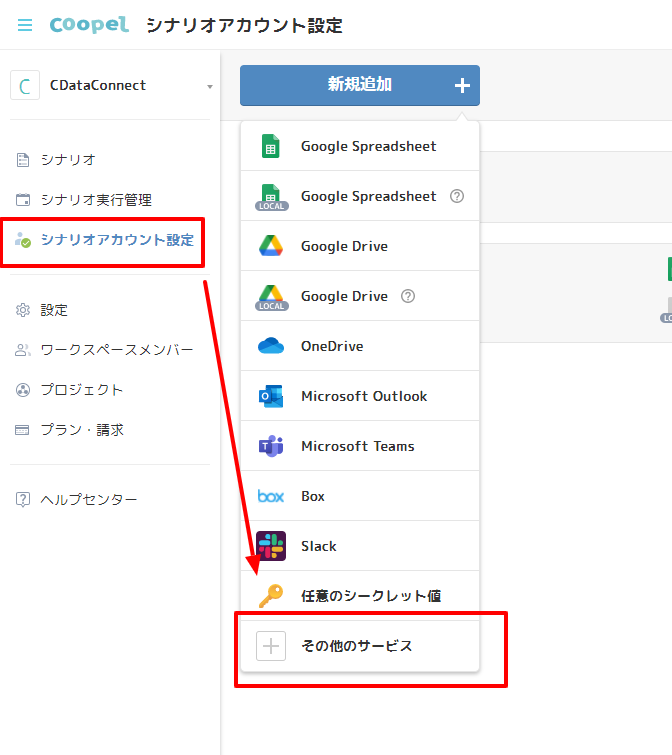
- ワークスペースを作成後、CData Connect Cloud にアクセスするための認証情報をCoopel 上に保存しましょう。「シナリオアカウント設定」→「新規追加」→「その他のサービス」を選択します。
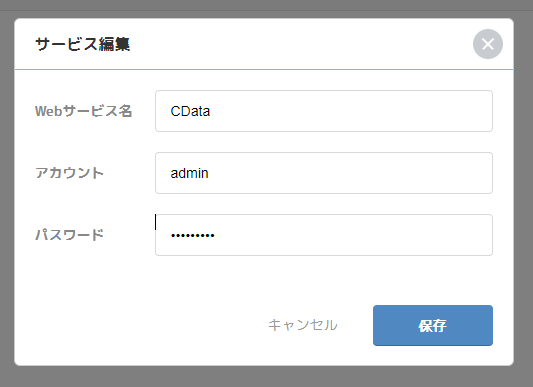
- ここで、CData Connect Cloud にアクセスするためのUserID とPassword を入力し、保存じます。Web サービス名には任意の名称を入力してください。
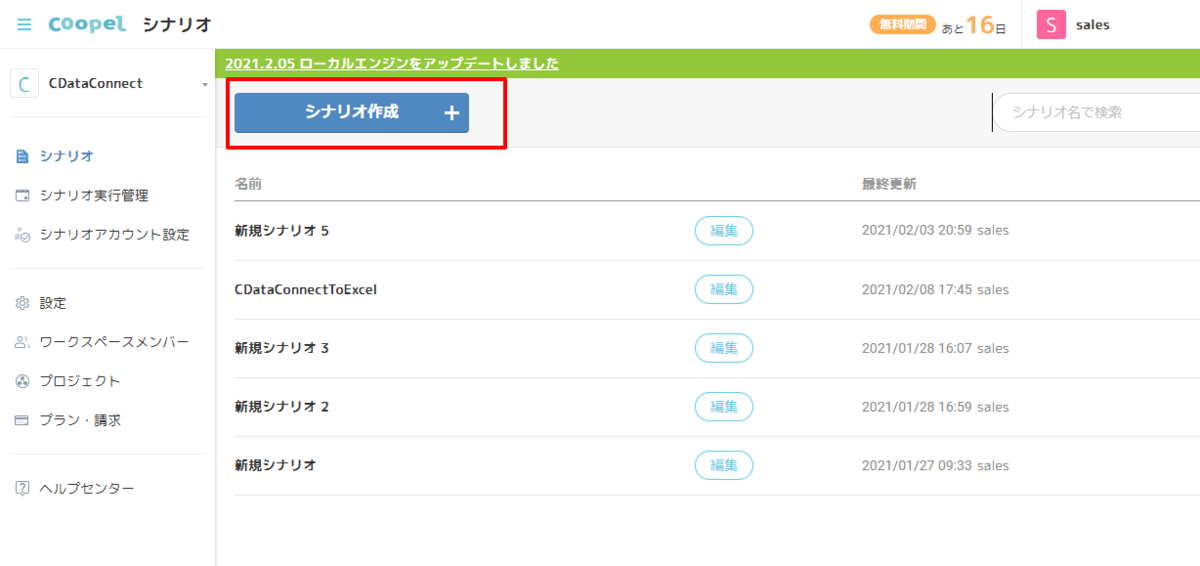
- 次にメインとなるシナリオを作成します。「シナリオ作成」をクリックし
- 任意の名称を入力します。
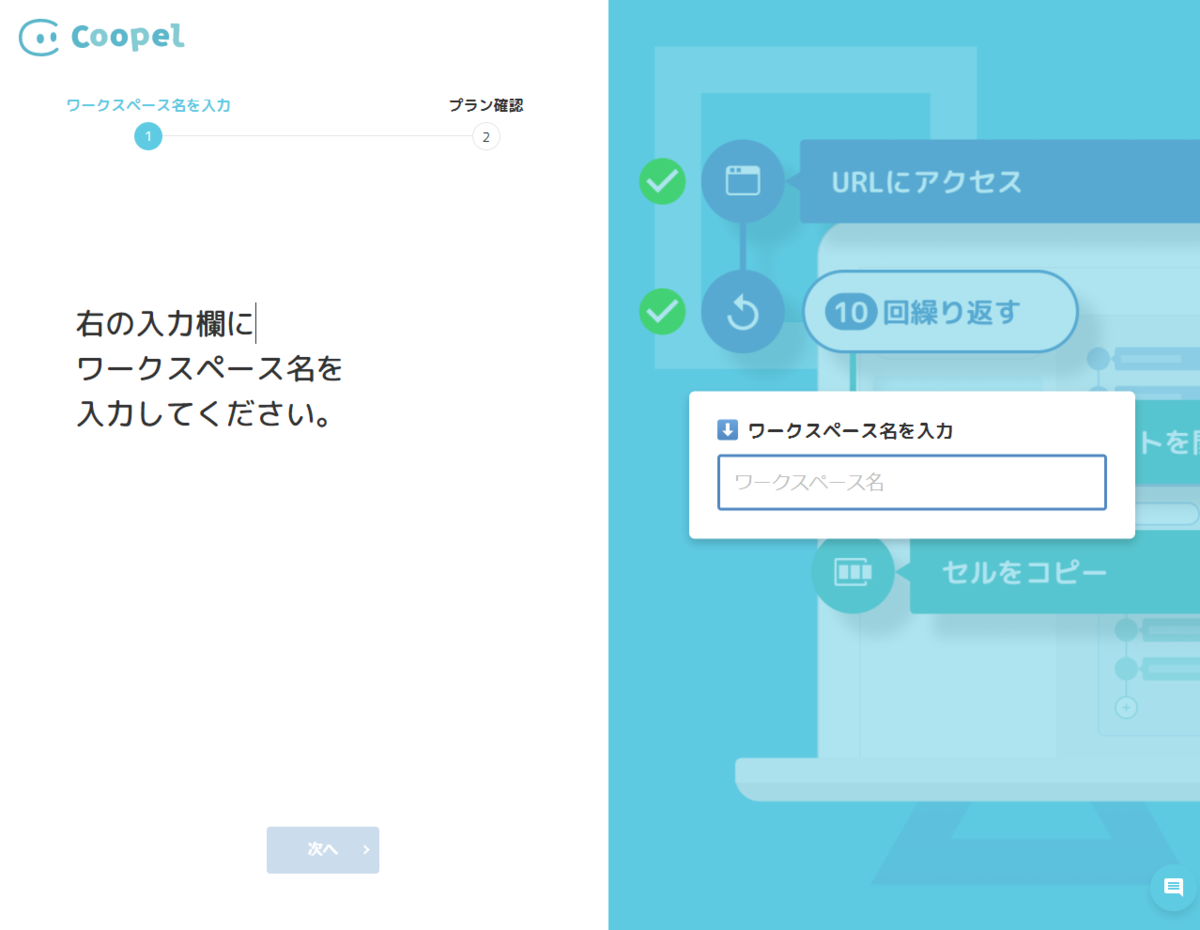
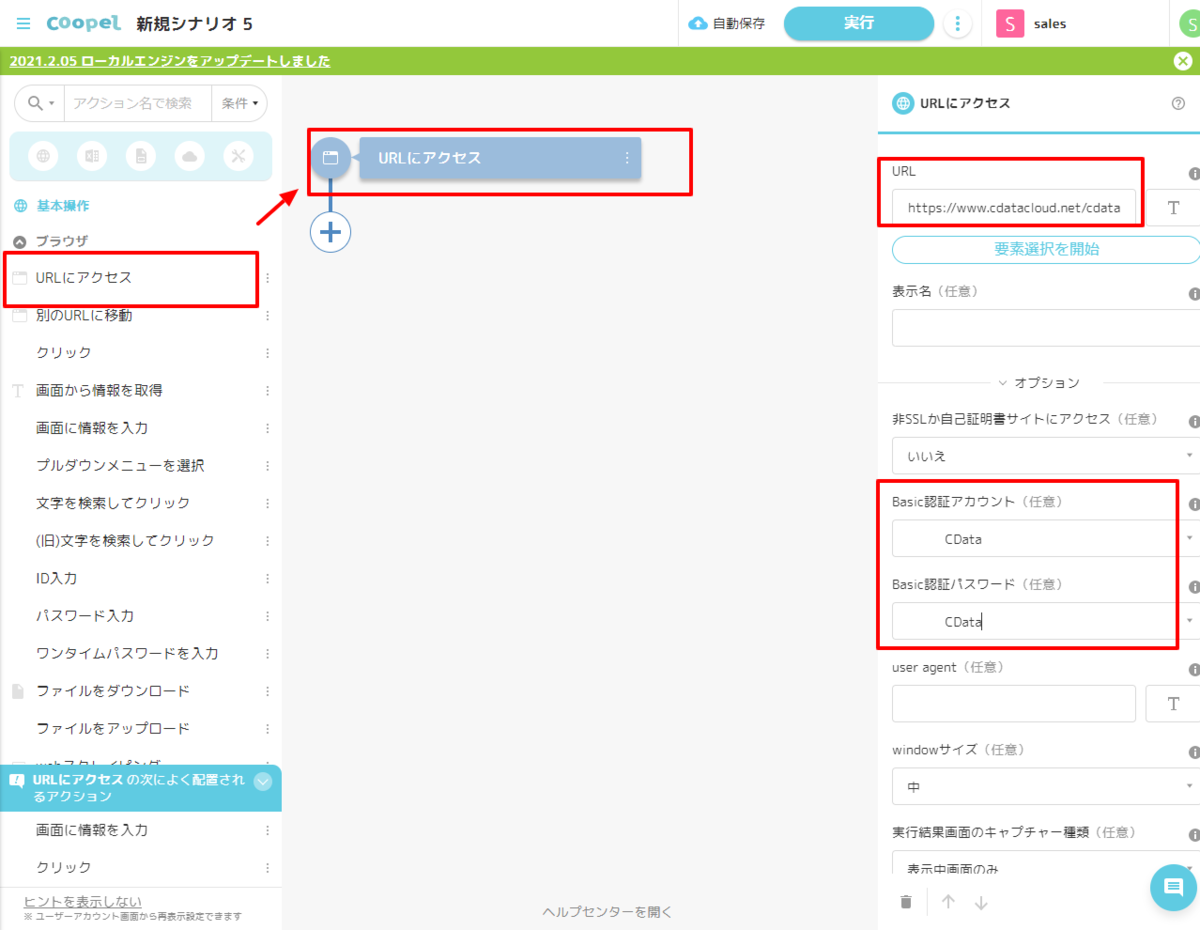
Spark のデータを取得する処理を作成
シナリオを作成したらSpark のデータを取得する処理の作成を進めましょう。
- Coopel からSpark のデータを取得するためには、CData Connect Cloud を経由します。Coopel では、ブラウザアクセスと同じような方法でCData Connect Cloud にアクセスするので、「URLにアクセス」のアクションを使って、データ取得を行います。Coopelのアクション一覧から「URLにアクセス」を配置し、先程検証した以下の「URL」および、「Basic認証アカウント」に指定します。
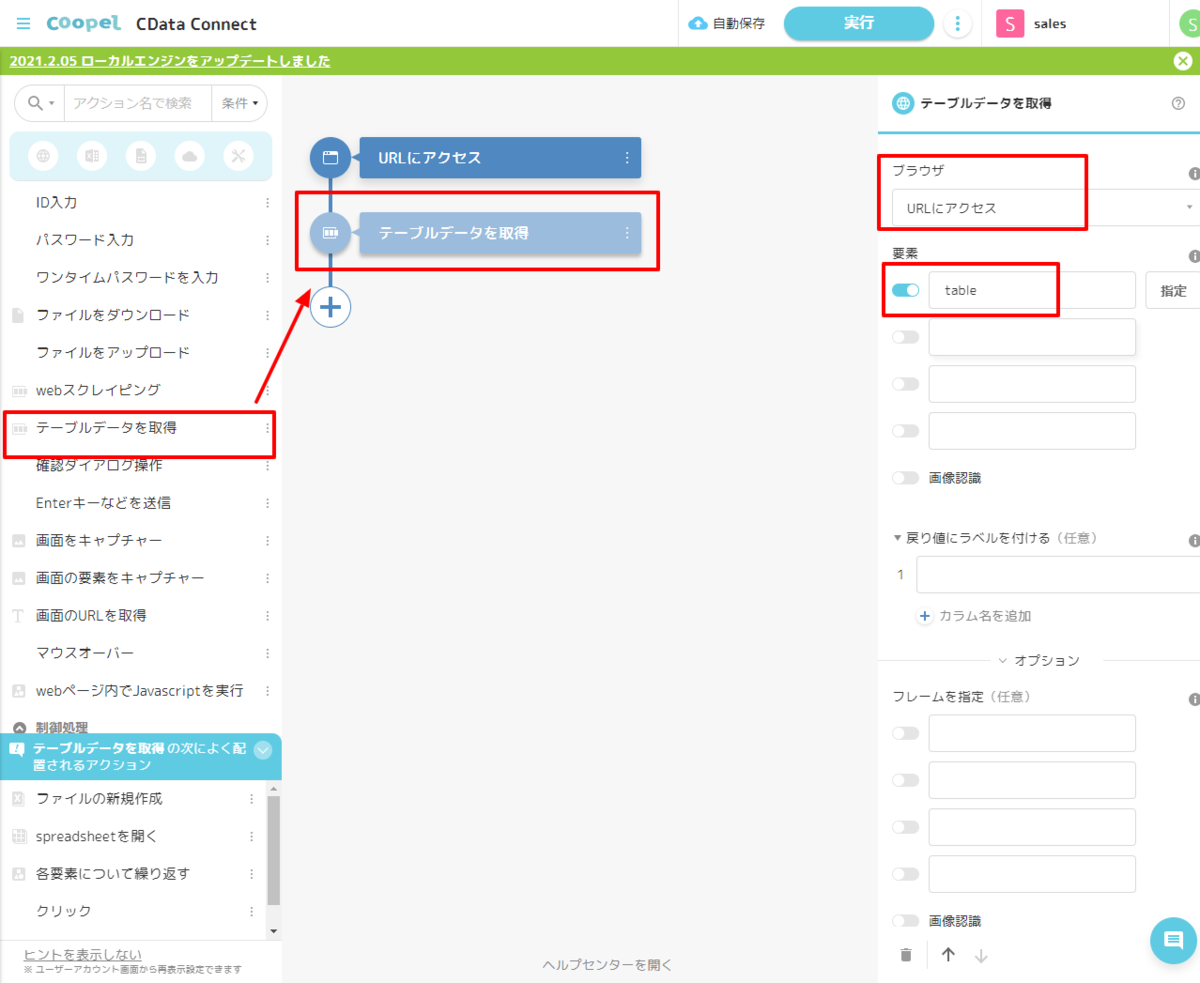
- 続いて、表示されたデータをCoopel 上で扱いやすい形にするためにテーブルデータとして取得を行います。Coopel アクションの一覧から「テーブルデータを取得」を配置し、先程作成した「URL にアクセス」をブラウザへ指定。テーブルの要素として「table」を指定します。
- これで、Coopel上でCData Connect Cloud 経由で取得したデータを操作する準備が整いました。あとはCoopel のさまざまなアクションを駆使して、フローを作成していきます。
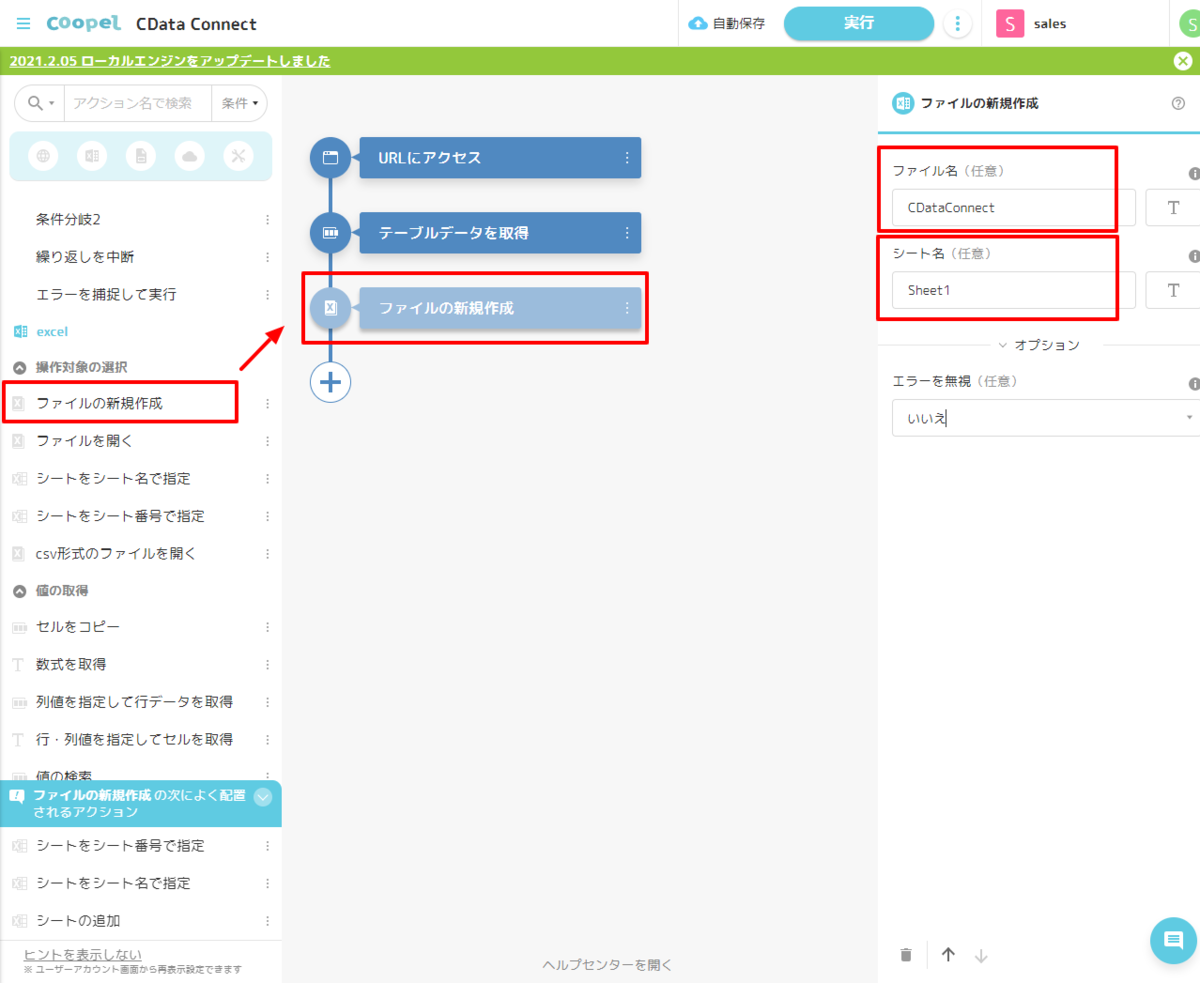
ファイル出力処理を作成
データを取得する処理が作成できたら、そのデータをExcel ファイルに出力してみましょう。
- 最初に「ファイルの新規作成」アクションを使って、Excel ファイルを作成します。任意の名称でファイル名とシート名を指定してください。
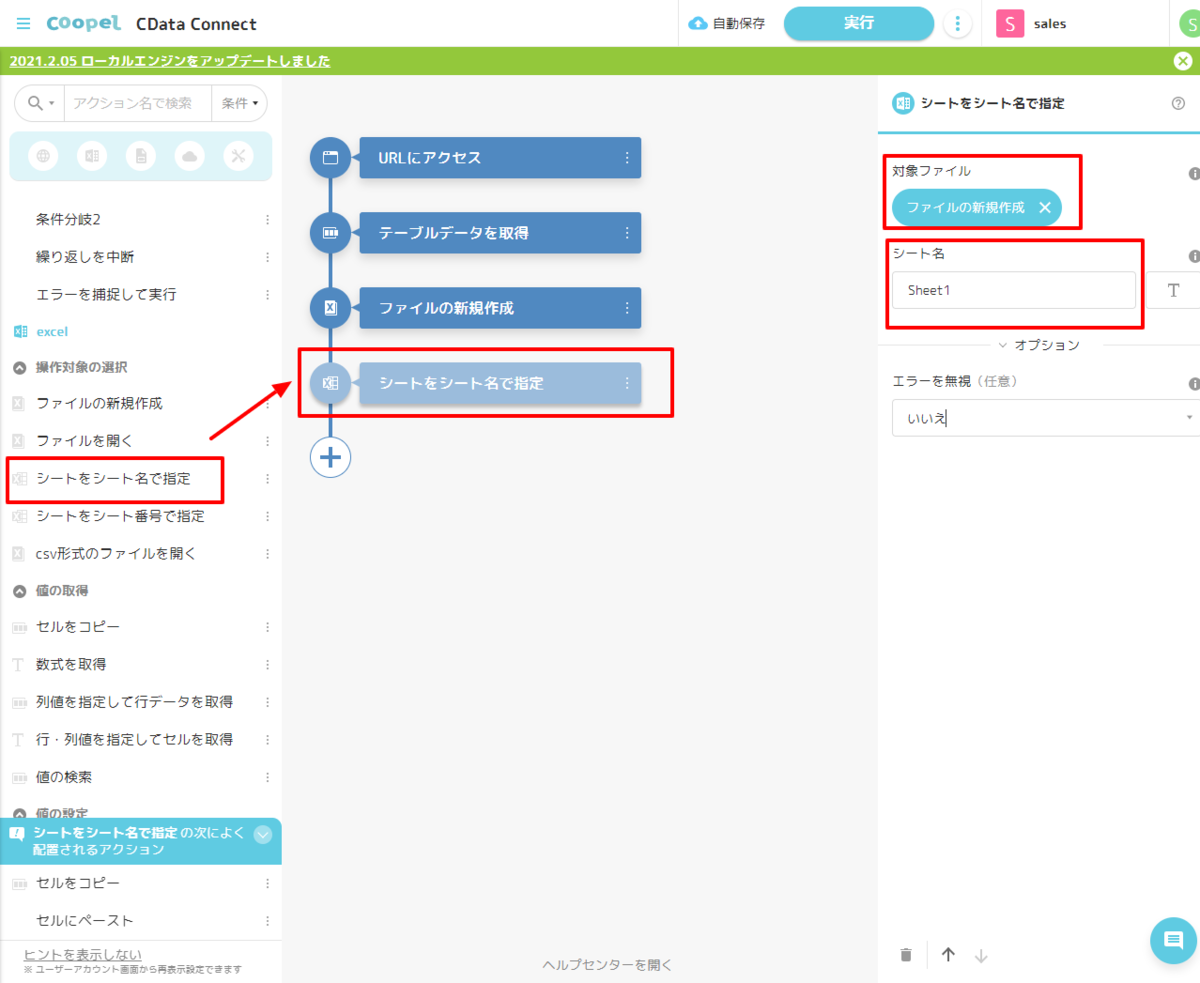
- 次に「シートをシート名で指定」のアクションを配置して、先程作成したExcel ファイルのシートを参照します。
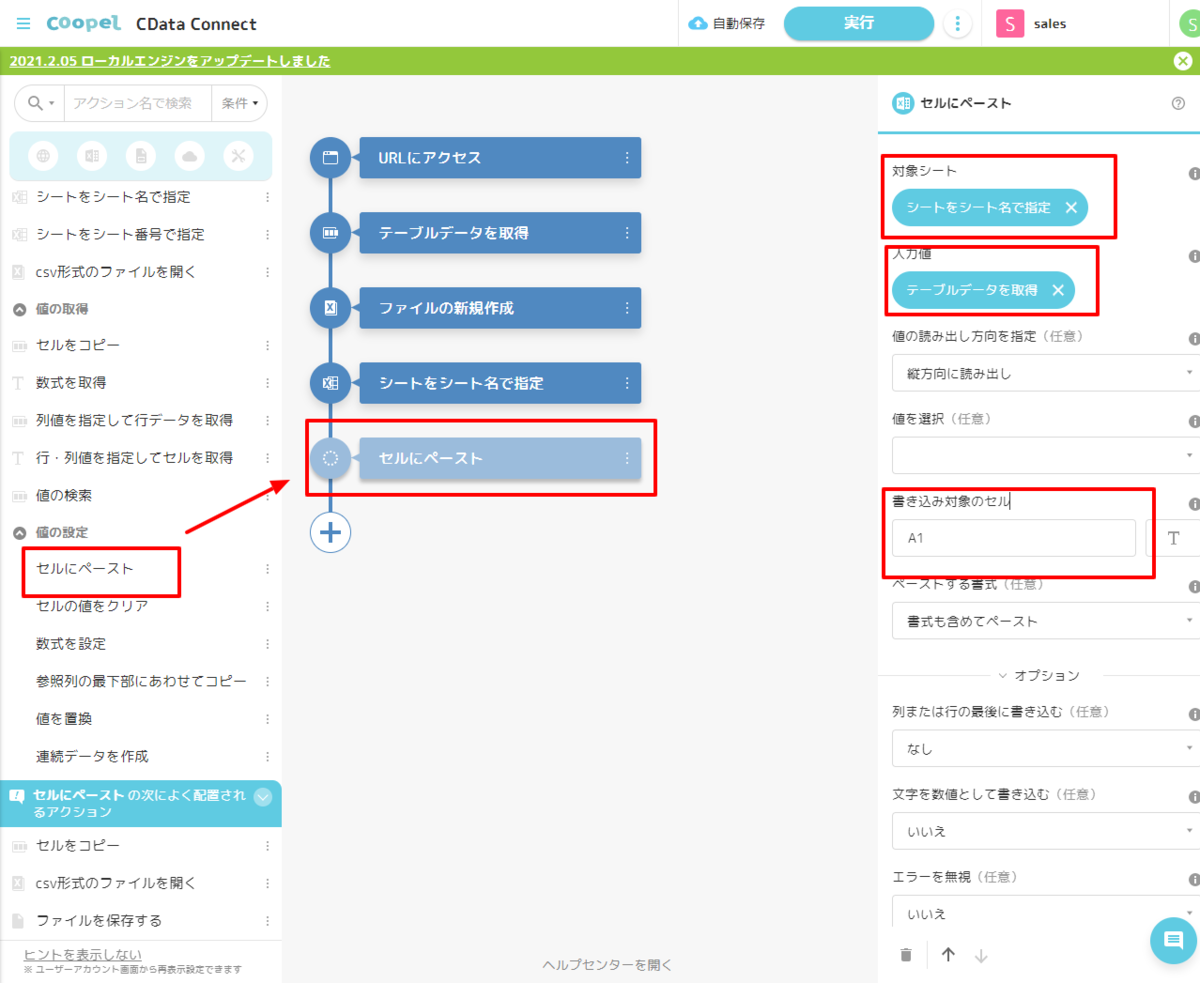
- シートを開いたら、取得したデータを「セルにペースト」アクションで貼り付けます。事前に作成した「対象シート」と、CData Connect Cloud から取得した「テーブルデータ」を指定します。書き込み対象セルは一番左上のセルから入力するので「A1」を指定しました。
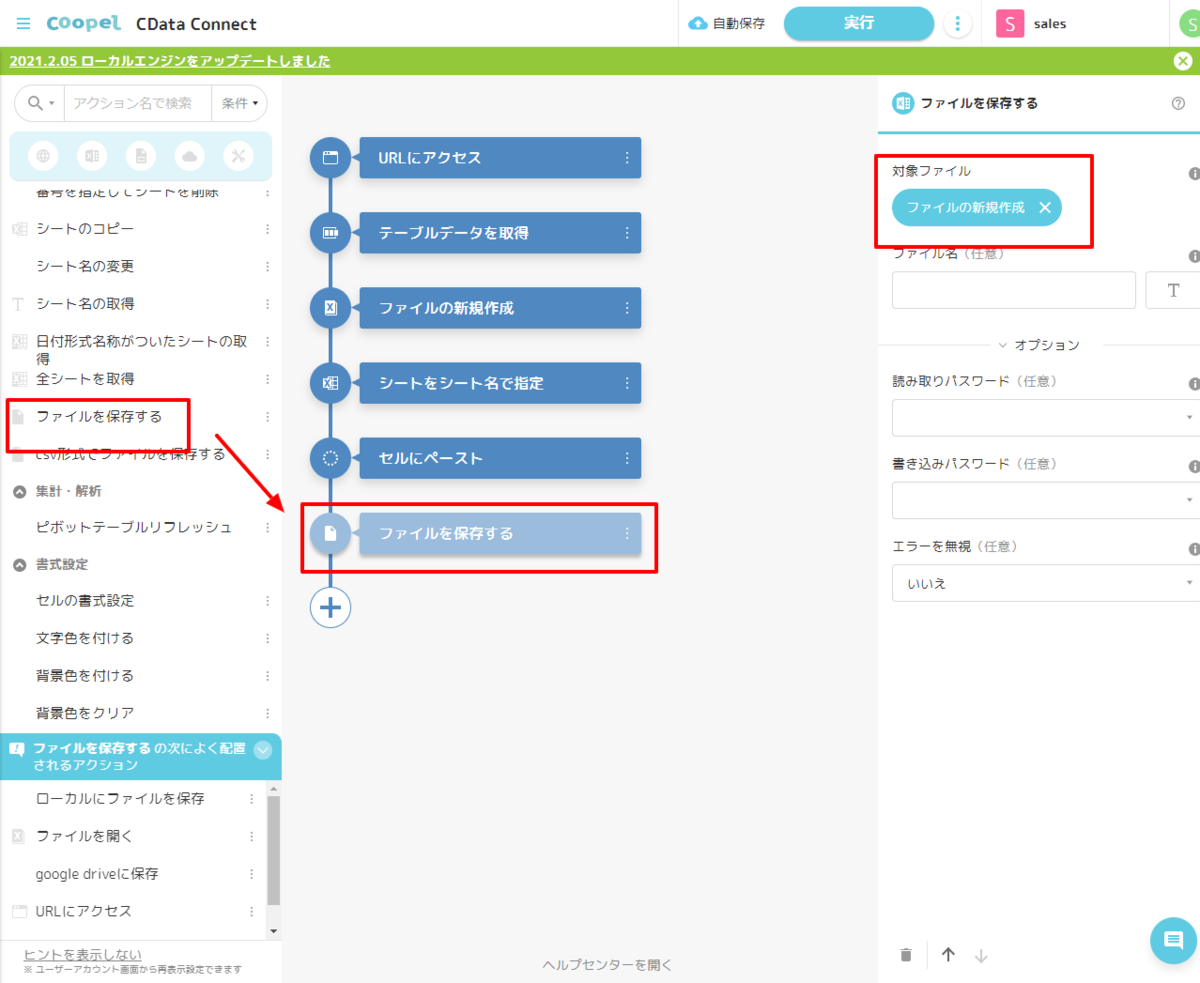
- 最後に作成したExcel ファイルを「ファイルを保存する」アクションで保存します。以上ですべてのシナリオが完成しました。
実行
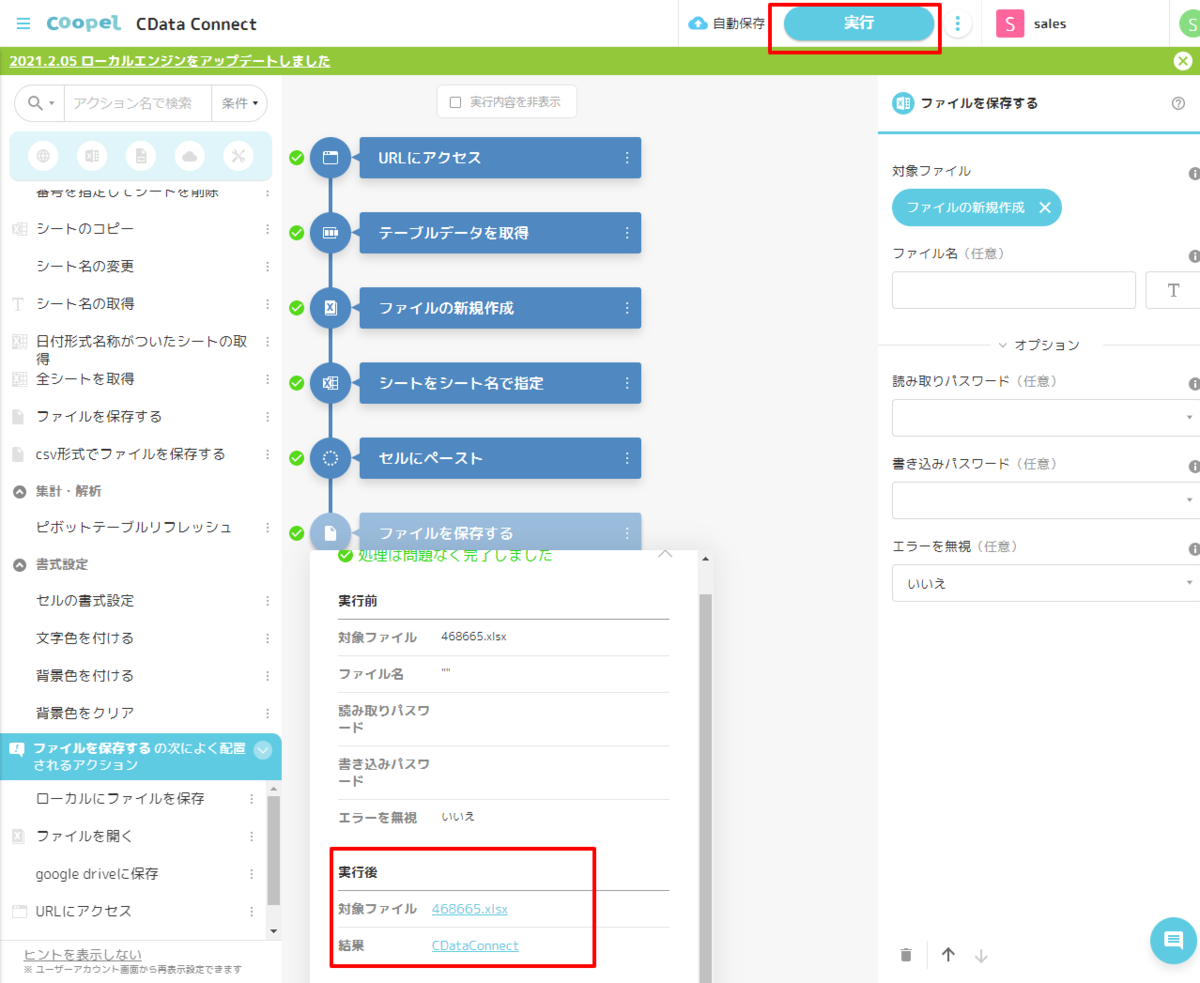
それでは完成したシナリオを実行してみましょう。
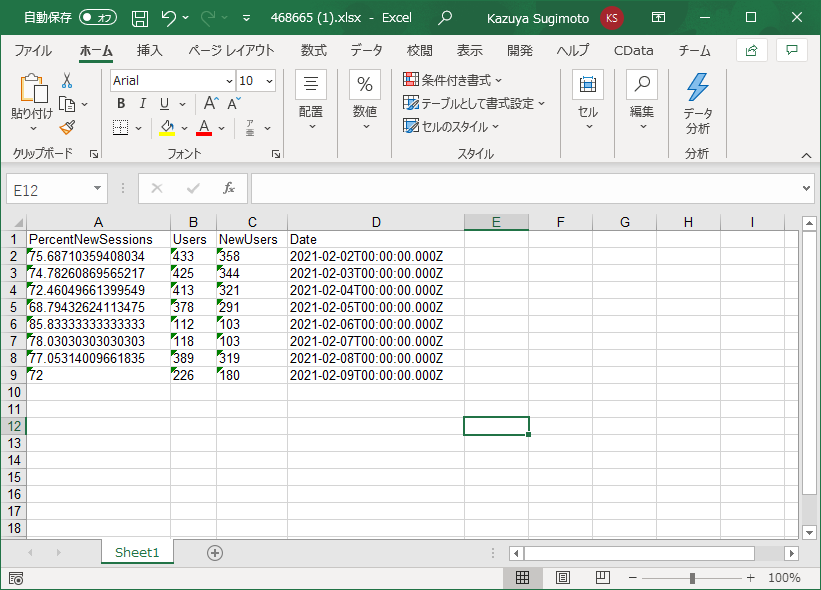
- Coopelでは画面右上の「実行」ボタンでシナリオを試すことができます。正常に実行されると、以下のように「ファイルを保存する」アクションのダイアログに生成されたExcel ファイルが表示されます。
- これをダウンロードして、Excelで開いてみると、以下のようにCData Connect Cloud 経由で取得したデータが入力されていることが確認できます。
クラウドRPA からSpark のデータへのライブ接続
Coopel からSpark リアルタイムデータに直接接続できるようになりました。これで、Spark のデータを複製せずにより多くの接続とシナリオを作成できます。
クラウドRPA から直接100を超えるSaaS 、ビッグデータ、NoSQL ソースへのリアルタイムデータアクセスを取得するには、CData Connect Cloud を参照してください。