各製品の資料を入手。
詳細はこちら →



製品をチェック

CSV のデータを複数のデータベースにレプリケーション。
CSV をPoint-and-click 操作で複数の異なるデータベースに同期する方法。
最終更新日:2022-11-28
こんにちは!プロダクトスペシャリストの宮本です。
常時起動のアプリケーションは、自動フェイルオーバー機能およびリアルタイムなデータアクセスを必要とします。CData Sync は、リアルタイムCSV のデータをミラーリングデータベース、上記稼働のクラウドデータベース、レポーティングサーバーなどのほかのデータベースに連携し、Windows からリモートCSV に接続し、自動的に同期を取ります。
レプリケーションの同期先の設定
CData Sync を使って、CSV をクラウド・オンプレにかかわらず複数のデータベースレプリケーションします。レプリケーションの同期先を追加するには、[接続]タブを開きます。
それぞれのデータベース向けに以下を行います:
- [同期先]タブをクリックします。
- 同期先を選択します。この記事では、SQLite を使います。
- 必要な接続プロパティを入力します。SQLite データベースにCSV をレプリケートするためにDataSource ボックスにファイルパスを入力します。
- [接続のテスト]をクリックして、正しく接続できているかをテストします。
- [変更を保存]をクリックします。
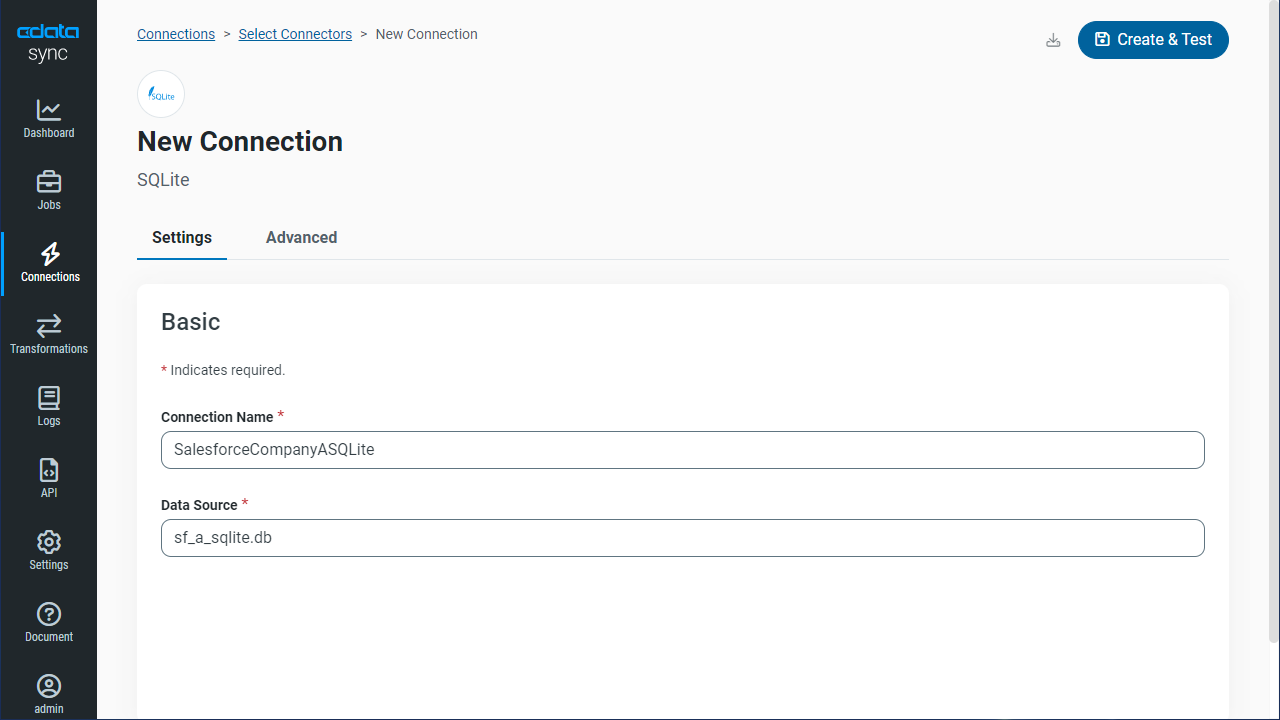
CSV 接続の設定
データソース側にCSV を設定します。[接続]タブをクリックします。
- [同期先]タブをクリックします。
- CSV アイコンをデータソースとして選択します。プリインストールされたソースにCSV がない場合には、追加データソースとしてダウンロードします。
- 接続プロパティに入力をします。
CSV 接続プロパティの取得・設定方法
DataSource プロパティにローカルフォルダ名を設定します。
.csv、.tab、.txt ではない拡張子のファイルを扱う場合には、IncludeFiles 使用する拡張子をカンマ区切りで設定します。Microsoft Jet OLE DB 4.0 driver 準拠の場合にはExtended Properties を設定することができます。別の方法として、Schema.ini ファイルにファイル形式を記述することも可能です。
CSV ファイルの削除や更新を行う場合には、UseRowNumbers をTRUE に設定します。RowNumber はテーブルKey として扱われます。
Amazon S3 内のCSV への接続
URI をバケットおよびフォルダに設定します。さらに、次のプロパティを設定して認証します。
- AWSAccessKey:AWS アクセスキー(username)に設定。
- AWSSecretKey:AWS シークレットキーに設定。
Box 内のCSV への接続
URI をCSV ファイルを含むフォルダへのパスに設定します。Box へ認証するには、OAuth 認証標準を使います。 認証方法については、Box への接続 を参照してください。
Dropbox 内のCSV への接続
URI をCSV ファイルを含むフォルダへのパスに設定します。Dropbox へ認証するには、OAuth 認証標準を使います。 認証方法については、Dropbox への接続 を参照してください。ユーザーアカウントまたはサービスアカウントで認証できます。ユーザーアカウントフローでは、以下の接続文字列で示すように、ユーザー資格情報の接続プロパティを設定する必要はありません。
SharePoint Online SOAP 内のCSV への接続
URI をCSV ファイルを含むドキュメントライブラリに設定します。認証するには、User、Password、およびStorageBaseURL を設定します。
SharePoint Online REST 内のCSV への接続
URI をCSV ファイルを含むドキュメントライブラリに設定します。StorageBaseURL は任意です。指定しない場合、ドライバーはルートドライブで動作します。 認証するには、OAuth 認証標準を使用します。
FTP 内のCSV への接続
URI をルートフォルダとして使用されるフォルダへのパスが付いたサーバーのアドレスに設定します。認証するには、User およびPassword を設定します。
Google Drive 内のCSV への接続
デスクトップアプリケーションからのGoogle への認証には、InitiateOAuth をGETANDREFRESH に設定して、接続してください。詳細はドキュメントの「Google Drive への接続」を参照してください。
- [接続のテスト]をクリックして、正しく接続できているかをテストします。
- [変更を保存]をクリックします。
レプリケーションを実行するクエリの設定
CData Sync はレプリケーションをコントロールするSQL クエリを簡単なGUI 操作で設定できます。レプリケーションジョブ設定には、[ジョブ]タブに進み、[ジョブを追加]ボタンをクリックします。 次にデータソースおよび同期先をそれぞれドロップダウンから選択します。
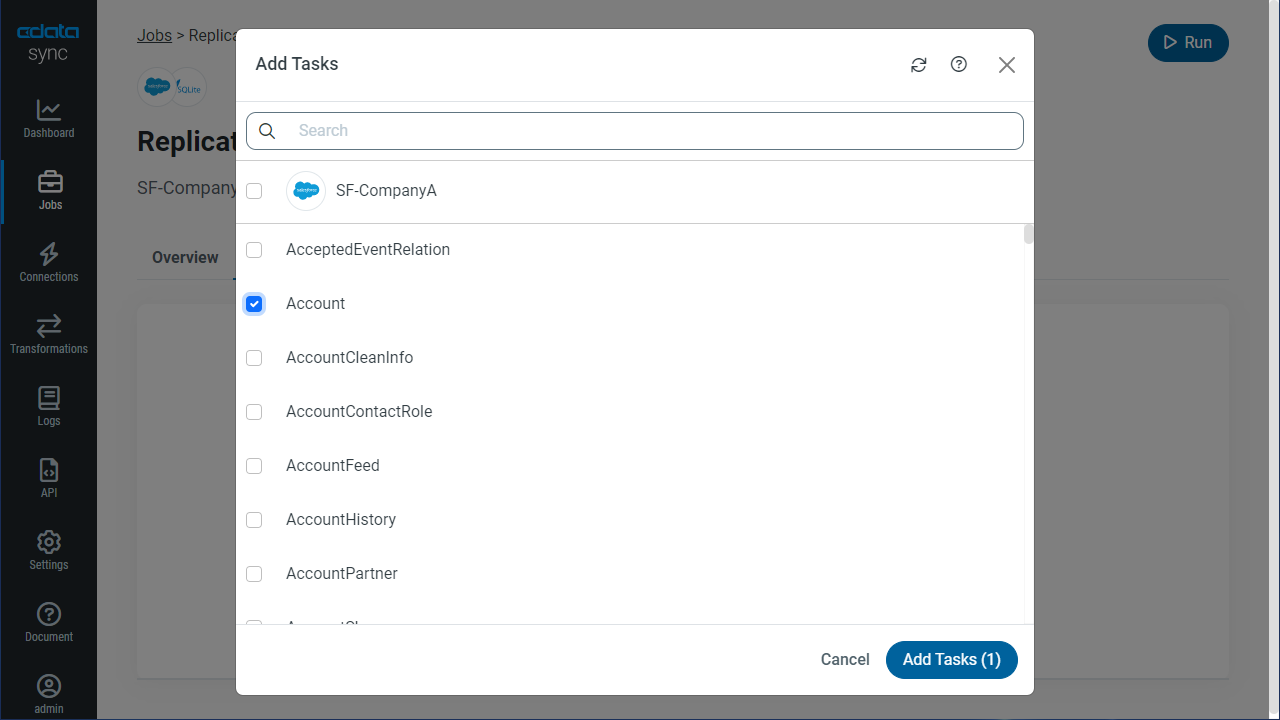
テーブル全体をレプリケーションする
テーブル全体をレプリケーションするには、[テーブル]セクションで[テーブルを追加]をクリックします。表示されたテーブルリストからレプリケーションするテーブルをチェックします。
テーブルをカスタマイズしてレプリケーションする
SQL クエリを使って、レプリケーションをカスタマイズすることができます。REPLICATE ステートメントは、データベースにテーブルをキャッシュして、保持するハイレベルなコマンドです。CSV API でサポートされているSELECT クエリを使うことができます。レプリケーションのカスタマイズには、[カスタムクエリを追加]をクリックして、カスタムクエリステートメントを定義します。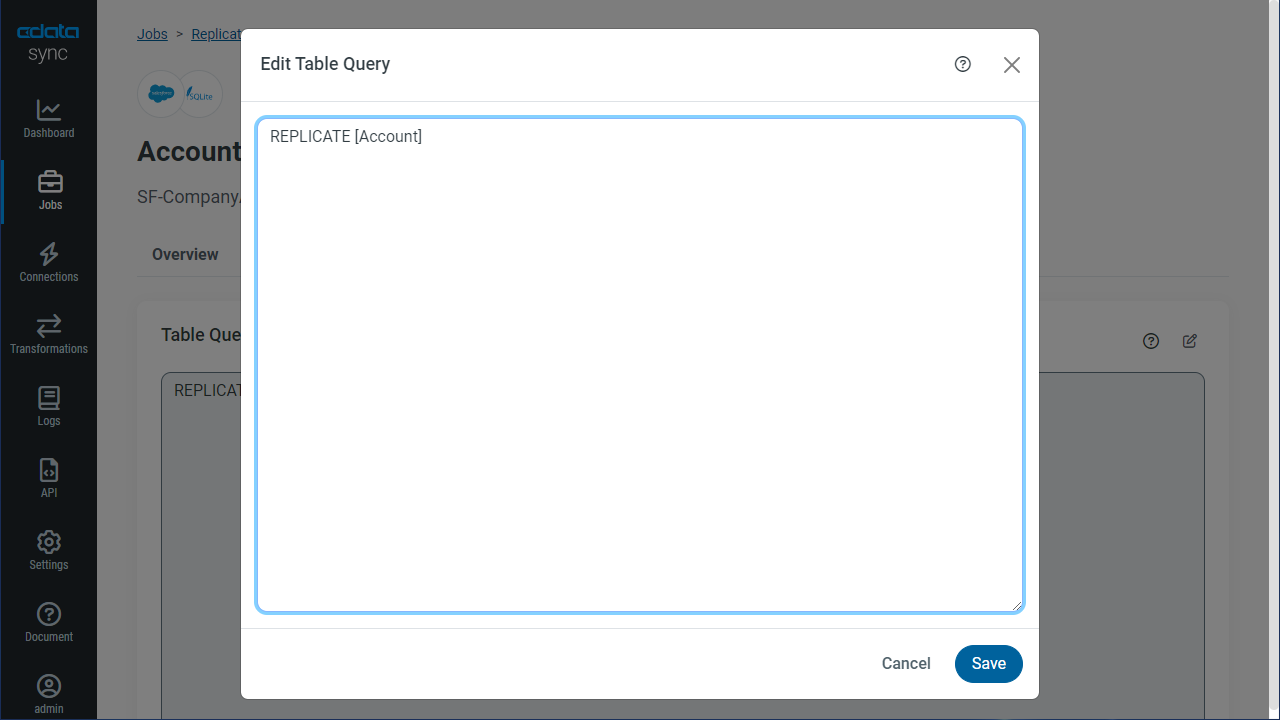
次のステートメントは、CSV のテーブルのアップデートを差分更新でキャッシュします:
REPLICATE Customer;
特定のデータベースを更新するために、レプリケーションクエリを含むファイルを指定することもできます。レプリケーションクエリをセミコロンで区切ります。複数のCSV アカウントを同じデータベースに同期しようとする際には、以下のオプションが便利です:
-
REPLICATE SELECT ステートメントで別のprefix を使う:
REPLICATE PROD_Customer SELECT * FROM Customer; -
別の方法では、別のスキーマを使う:
REPLICATE PROD.Customer SELECT * FROM Customer;
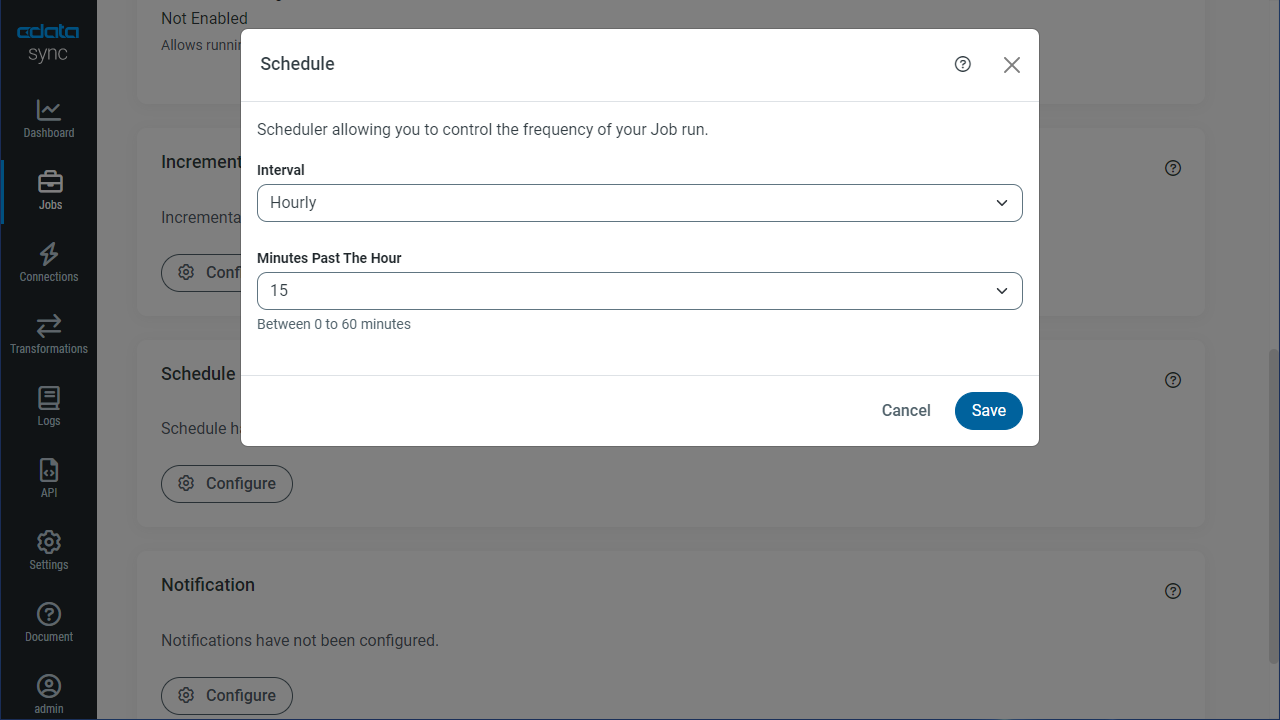
レプリケーションのスケジュール起動設定
[スケジュール]セクションでは、レプリケーションジョブの自動起動スケジュール設定が可能です。反復同期間隔は、15分おきから毎月1回までの間で設定が可能です。
レプリケーションジョブを設定したら、[変更を保存]ボタンを押して保存します。CSV のオンプレミス、クラウドなどのデータベースへのレプリケーションジョブは一つではなく複数を作成することが可能です。