各製品の資料を入手。
詳細はこちら →



ADO.NET 経由でTIBCO Spotfire でSpark のデータに連携してをビジュアライズ
TIBCO Spotfire のダッシュボードにSpark のデータの連携が驚くほど簡単に。
最終更新日:2022-09-16
こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
この記事では、CData ADO.NET Provider for SparkSQL をTIBCO Spotfire で使う方法を説明します。接続を確立して、簡単なダッシュボードを作成していきます。
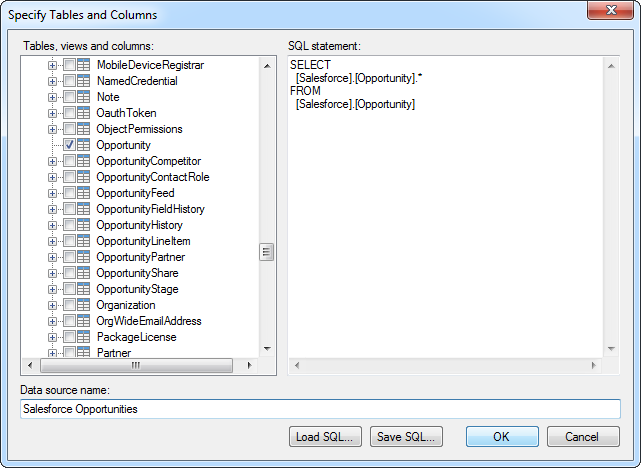
- [Add Data Tables]をクリックして、CData ADO.NET データソースを追加します。
- [Add]>[Database]をクリックします。
- プロバイダーを選択して[Configure]をクリックします。
- 接続設定を定義します。一般的な接続文字列は次のとおりです。
Server=127.0.0.1;
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。

- ダッシュボードに追加したいテーブルを選択します。この例ではCustomers を使います。SQL クエリも指定できます。ドライバーは標準SQL シンタックスをサポートしています。
- リアルタイムデータを使いたい場合は、[Keep Data Table External]オプションをクリックします。このオプションは、データの変更をリアルタイムでダッシュボードに反映します。
データをメモリにロードしてローカルで処理したい場合は、[Import Data Table]オプションをクリックします。このオプションは、オフラインでの使用、またはスローなネットワーク接続によりダッシュボードがインタラクティブでない場合に使用します。
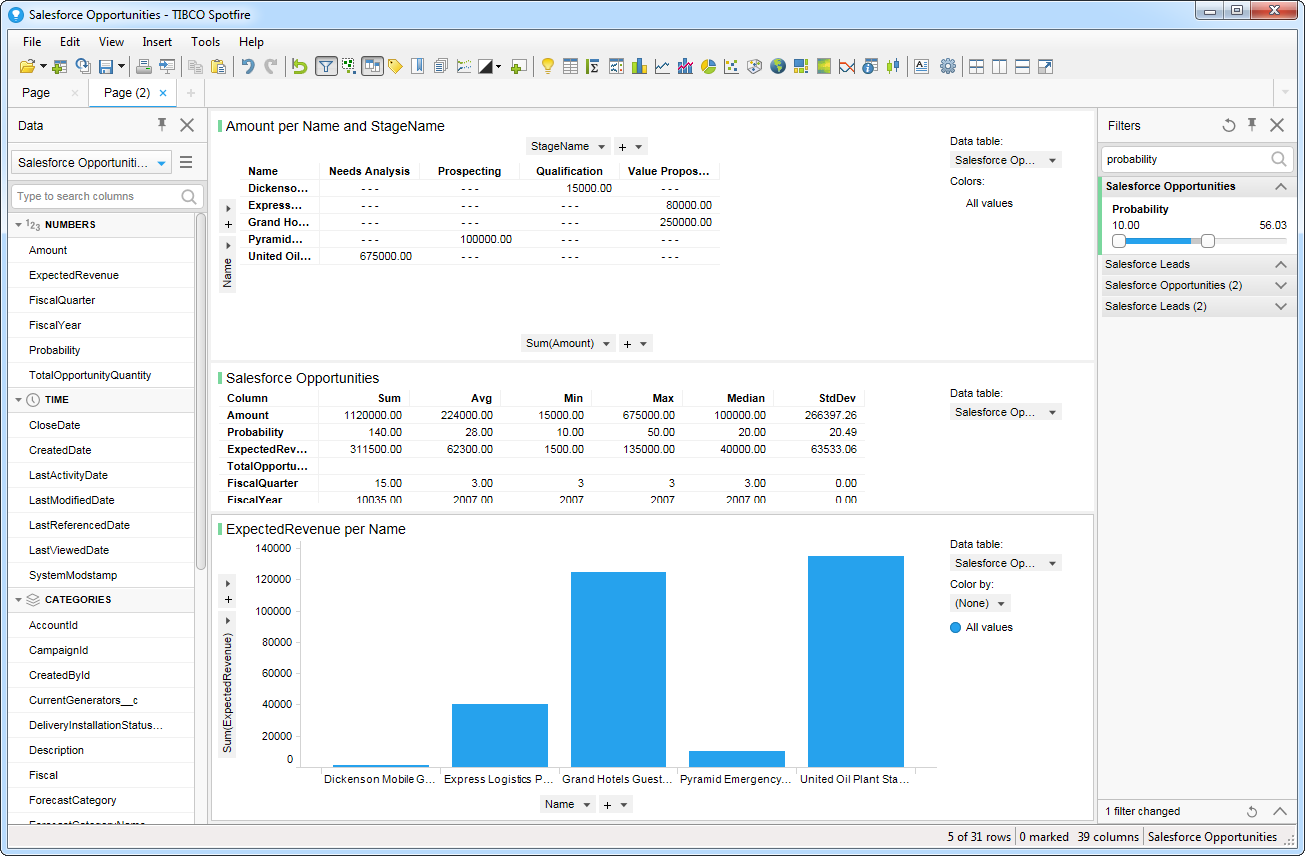
- テーブルを追加すると[Recommended Visualizations]ウィザードが表示されます。テーブルを選択すると、Spotfire はカラムのデータ型を使ってnumber、time、category カラムを検出します。この例ではNumbers セクションでBalance を、Categories セクションでCity を使用しています。
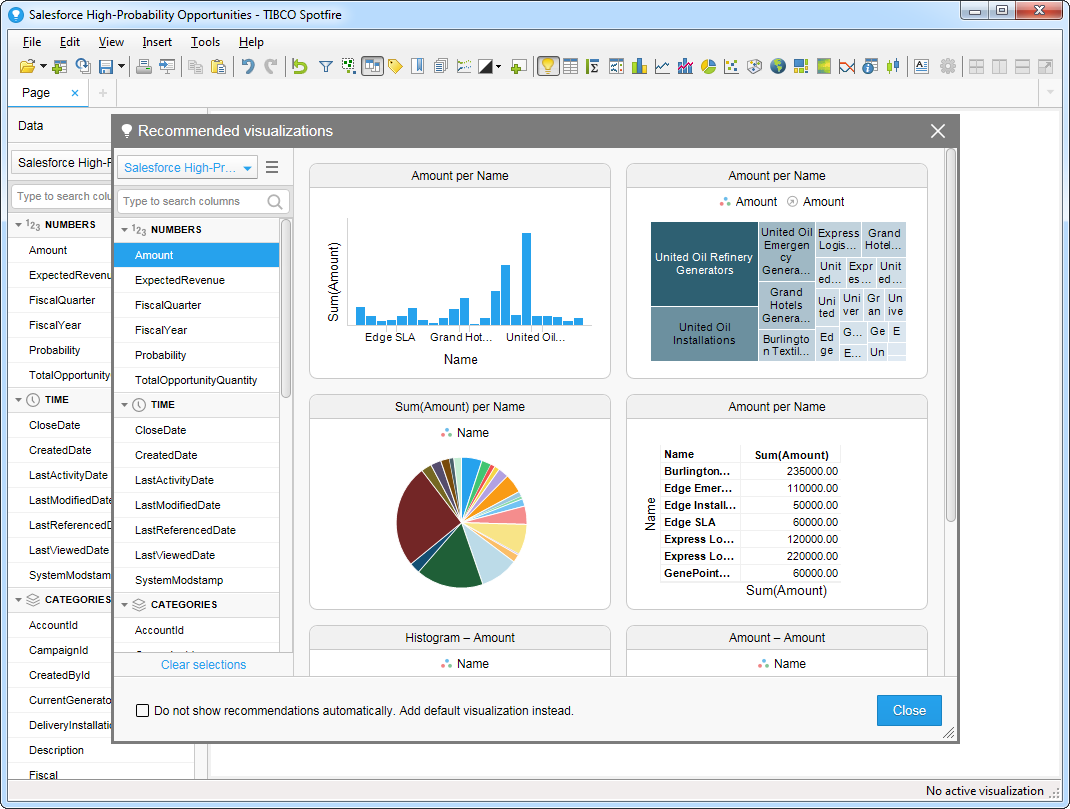
[Recommended Visualizations]ウィザードでいくつかビジュアライズしたら、ダッシュボードにその他の修正を加えられます。例えば、ページにフィルタを適用することで、高確率なopportunities にズームインできます。フィルタを追加するには、[Filter]ボタンをクリックします。各クエリで利用可能なフィルタは、[Filters]ペインに表示されます。