各製品の資料を入手。
詳細はこちら →



Active Directory
Airtable
Asana
Autify
Azure Active Directory
Azure DevOps
Backlog
Basecamp
Bitbucket
Business b-ridge
Confluence
DocuSign
Email
Excel
Excel Online
Garoon
GitHub
Gmail
Google Calendar
Google Contacts
Google Sheets
Greenhouse
HCL Domino
Jira
Jira Assets
Jira Service Management
Kintone
Microsoft Entra ID
Microsoft Exchange
Microsoft Planner
Microsoft Project
Microsoft Teams
Monday.com
Office 365
Okta
OneNote
Oracle Service Cloud
PingOne
Quickbase
Raisers Edge NXT
Salesforce Data Cloud
SAP BusinessObjects BI
SAP SuccessFactors
SharePoint
SharePoint Excel Services
Slack
Smartsheet
TeamSpirit
Trello
WordPress
Zendesk
Zoho Creator
Zoho Projects
クラウドサイン
Act CRM
Act-On
ActiveCampaign
Acumatica
Bullhorn CRM
Certinia
Dynamics 365
Dynamics 365 Business Central
Dynamics CRM
Epicor Kinetic
Exact Online
Highrise
HubDB
Kingdee K3 WISE
nCino
NetSuite
Odoo
Oracle Financials Cloud
Oracle HCM Cloud
Oracle SCM
Outreach.io
Pipedrive
Sage 300
Salesforce
Salesforce Financial Service Cloud
SAP
SAP Ariba Source
SAP ByDesign
SAP Netweaver Gateway
ServiceNow
Sugar CRM
SuiteCRM
Tally
Tier1
UM SaaS Cloud
Veeva
Veeva CRM
Workday
Zoho CRM
Zoho Inventory
Adobe Analytics
Bing Ads
Cvent
Facebook
Facebook Ads
Google Ad Manager
Google Ads
Google Analytics
Google Campaign Manager 360
HubSpot
Instagram
LinkedIn
LinkedIn Ads
MailChimp
Marketo
Oracle Eloqua
Oracle Sales
Pinterest
Salesforce Marketing
Salesforce Marketing Cloud Account Engagement
Salesforce Pardot
Salesloft
Sansan
SendGrid
Snapchat Ads
Splunk
SurveyMonkey
Tableau CRM Analytics
Twitter
Twitter Ads
Yahoo! Ads
Yahoo! JAPAN DATA SOLUTION
YouTube Analytics
Amazon Athena
Amazon DynamoDB
Azure Data Catalog
Azure Table
BigQuery
Cassandra
Cloudant
CockroachDB
Cosmos DB
Couchbase
CouchDB
Databricks
Elasticsearch
Google Data Catalog
Google Spanner
GraphQL
HarperDB
HBase
Hive
IBM Cloud Data Engine
Kafka
MarkLogic
MongoDB
Neo4J
Phoenix
Presto
Redis
Redshift
Snowflake
Spark
TigerGraph
Trino
Power BI Desktop
MicroStrategy
QlikView
Dash
SAS
Tableau
Actionista!
Alteryx Designer
Amazon QuickSight
Aqua Data Studio
Birst
board
biz-Stream
Create!Form
Microsoft Excel Online
Microsoft Excel: Microsoft Query
Microsoft Power Query
Databricks
Data Knowledge
Dataiku DSS
Domo
Exploratory
FineReport
Looker Studio
Google Sheets
IBM Cognos Analytics
IBM Cognos BI
JasperServer
Jaspersoft Studio
JReport Designer
Klipfolio
KNIME
LINQPad
Metabase
OpenOffice
Qlik Sense
Power BI Online
Power BI Dataflow
Power BI
Power BI Service
Power BI Service Gateway
MATLAB
Microsoft SSAS
MotionBoard
OBIEE
Python pandas
Pentaho Report Designer
R
RapidMiner
Redash
SAP Business Objects
SAP Crystal Reports
SAP Lumira
Sisense
Slingshot
Spago BI
SPSS Modeler
Tableau Cloud: Connect Cloud
Tableau Cloud: 接続方法一覧
Tableau Desktop
Tableau Desktop
Tableau Bridge
Tableau Server
ThoughtSpot
TIBCO Spotfire Server
Visio
Yellowfin BI
XC-Gate
Zoho Analytics
AlloyDB
Couchbase
Snowflake
Amazon S3
Amazon Redshift
Google BigQuery
Google Cloud SQL
Kafka
SQLite
SQL Server
PostgreSQL
Oracle Database
MySQL
MongoDB
IBM DB2
CSV
Apache Cassandra
Azure Data Lake
Azure Synapse
Microsoft Azure SQL
Microsoft Access
Vertica
SAP HANA
AWS Glue
KARTE Datahub
Snowflake:リバースETL
Oracle Data Integrator
Apache Nifi
Apache Solr
ASTERIA WARP
Boomi
Google Cloud Data Fusion
CS Analtyics Data Uploader
Databricks
DataSpider
Elasticsearch Logstash
Embulk
FoxPro
Heroku / Salesforce Connect
Informatica Cloud
Informatica PowerCenter
Magic xpi
Microsoft Excel
Neuron
petl
Qlik Replicate
PowerShell:MySQL へのレプリケーション
AUTORO
Talend
TranSpeed
UiPath
Waha!Transformer
WinActor
appsmith
Contexer
.NET
LINQ
FastAPP
FileMaker ESS
Go
PHP
Python
PHP(Linux)
.NET
Adalo
AngularJS
App Builder
Microsoft Azure Logic Apps
Apache Spark
AppSheet
Blazor
Bubble
Choreo
ColdFusion
Coopel
DevExpress
Entity Framework
Entity Framework: MVC
Filemaker Pro
Google Apps Script
Hibernate
IntelliJ
JBoss
JDBI
Jetty
JRuby
Mendix
NEXACRO BEYOND
Monaca
NodeJS
OutSystems
PEP
Power Apps
PowerShell
PowerBuilder
PyCharm
Retool
React
Ruby
SAP AppGyver
SAP UI5
Servoy
StiLL
TALON
Tomcat
Unifinity
Wagby
製品をチェック
製品の詳細・30日間の無償トライアルはこちら
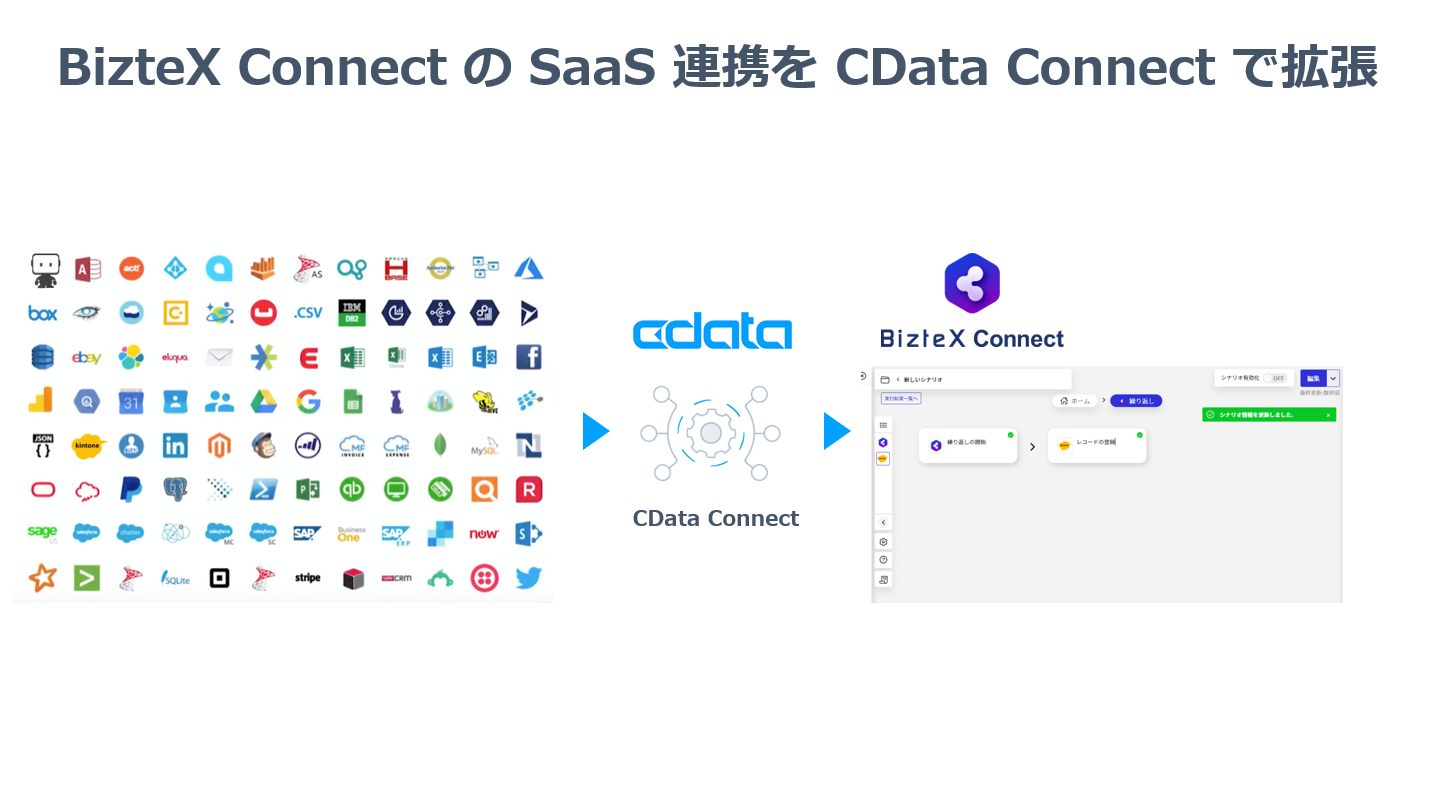
CData ConnectクラウドRPA BizteX Connect でSpark のデータにアクセス
CData Connect Server を使ってSpark のデータのOData API エンドポイントを作成し、BizteX Connect からSpark のデータにアクセスする方法。
杉本和也リードエンジニア
最終更新日:2021-12-23
こんにちは!リードエンジニアの杉本です。
BizteX Connect は BizteX 社が提供する国産iPaaS です。ノーコードでkintone やChatwork などさまざまなクラウドサービスと連携したフローを作成し、業務の自動化・効率化を実現することができます。この記事では、CData Connect Server を経由して BizteX Connect からSpark のデータを取得し活用する方法を説明します。
CData Connect Server は、Spark のデータのクラウド to クラウドの仮想OData インターフェースを提供し、BizteX Connect からリアルタイムにSpark のデータへ連携することができます。
Spark の仮想OData API エンドポイントを作成
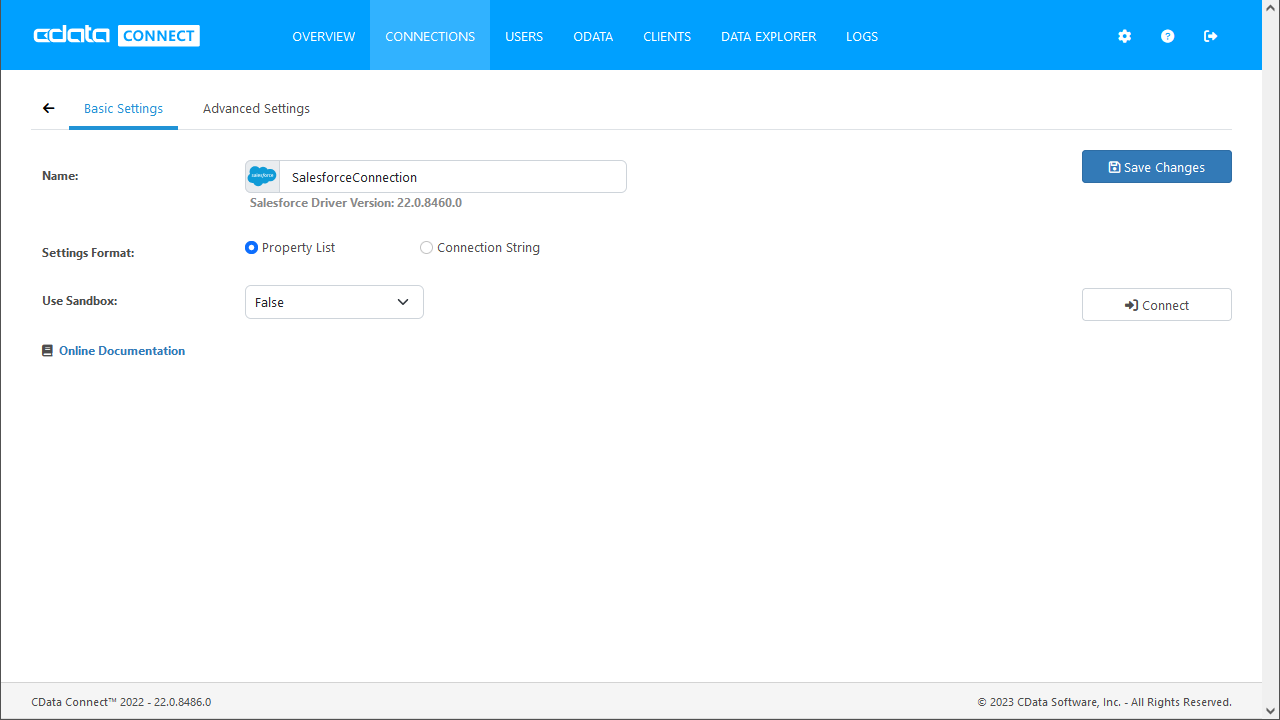
まずCData Connect Server でデータソースへの接続およびOData API エンドポイント作成を行います。
- CData Connect Server にログインして、Databases をクリックします。

- 利用できるデータソースアイコンから"Spark" を選択します。
-
Spark に接続するために必要なプロパティを入力します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
- Test Database をクリックします。
- Permission -> Add をクリックして、新しいユーザーを追加し、適切な権限を指定します。
- API タブをクリックして OData API エンドポイントが生成されていることを確認します。
プロジェクト・シナリオの作成
CData Connect Server 側の準備が完了したら、早速BizteX Connect 側でプロジェクト・シナリオの作成を開始します。
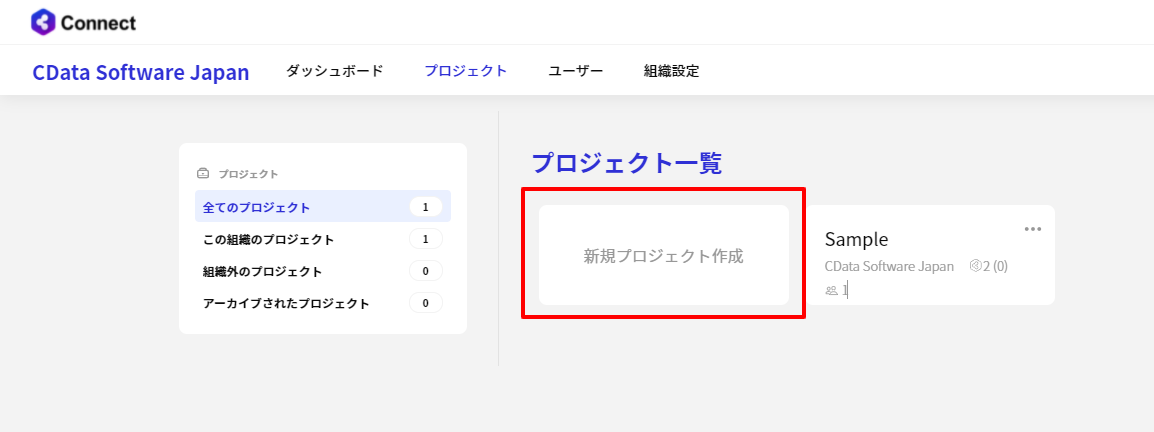
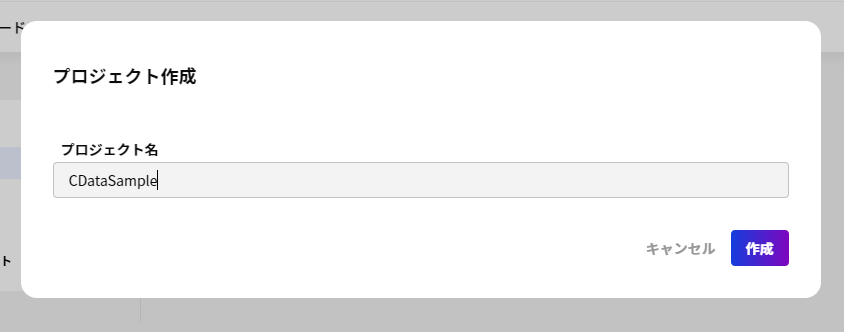
- まずはプロジェクトとシナリオ(フロー)を作成します。シナリオ(フロー)はプロジェクト単位でまとめて管理できるようです。
- 「新規プロジェクト作成」をクリック
- 任意の名称でプロジェクトを作成します。
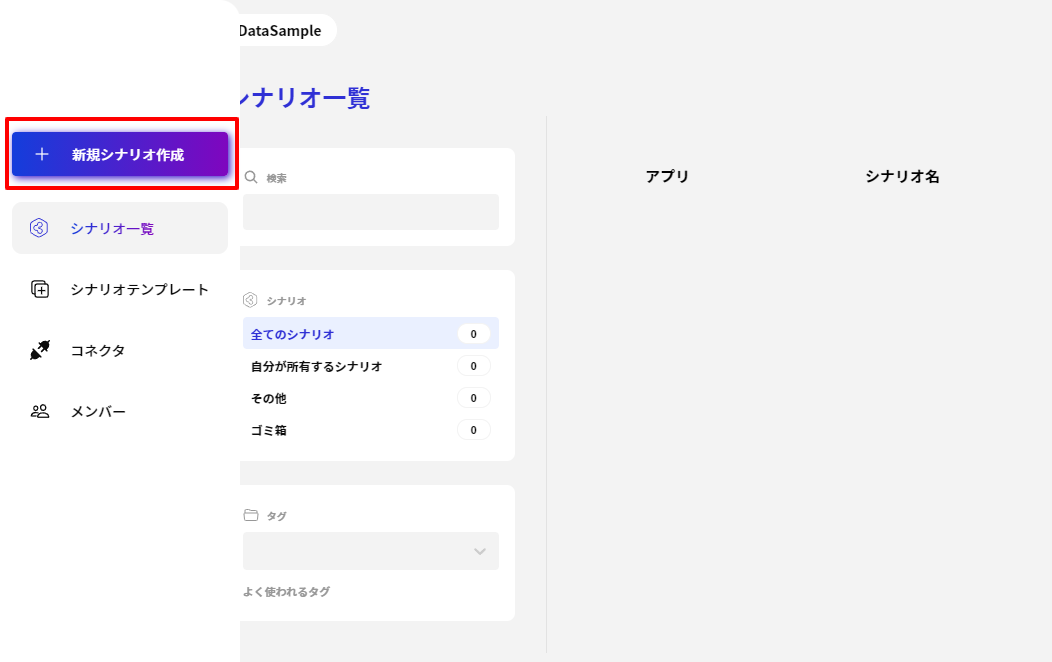
- その後「+新規シナリオ作成」をクリックして、Spark のデータ連携シナリオの作成を進めていきます。
起動イベントの設定
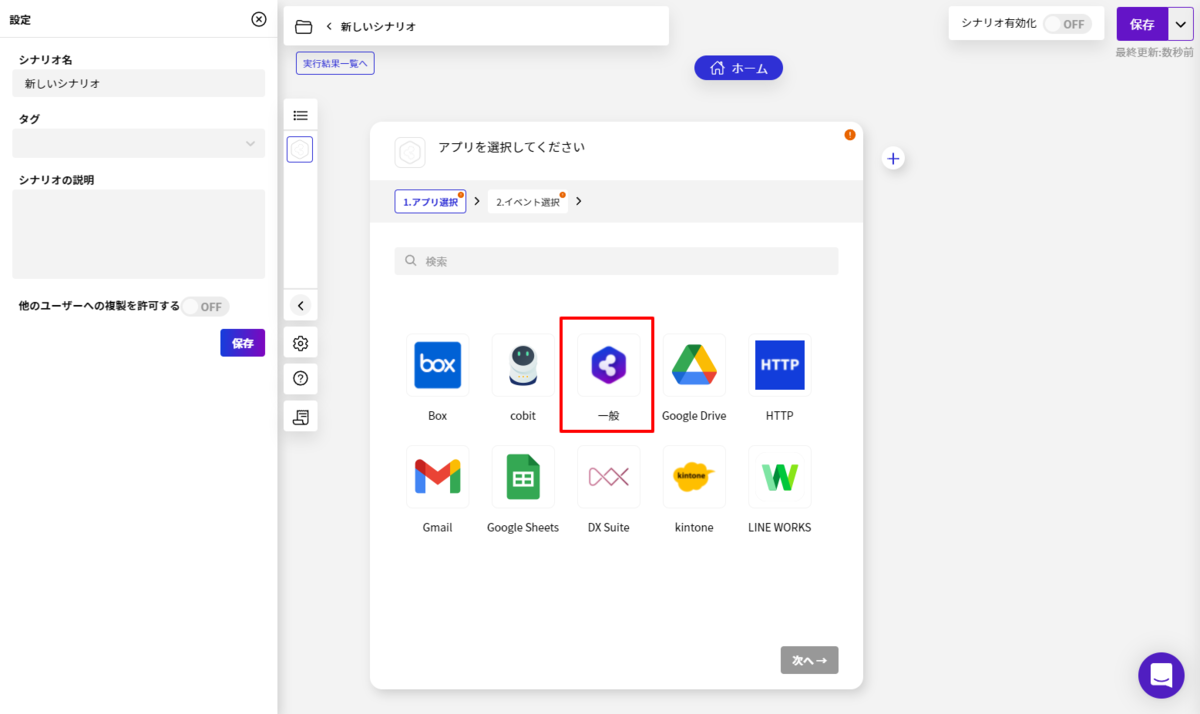
シナリオの作成で一番最初に設定することが、起動イベントの構成です。BizteX Connect ではさまざまな起動イベントが存在しますが、今回は検証用途として「手動」実行にしてみました。
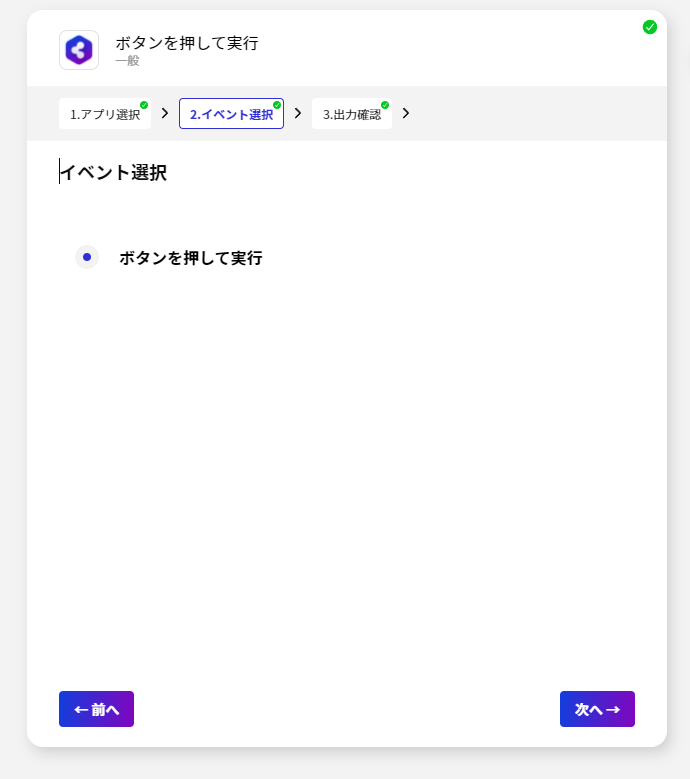
- 「アプリ選択」の一覧から「一般」を選択し
- 「ボタンを押して実行」を選択します。
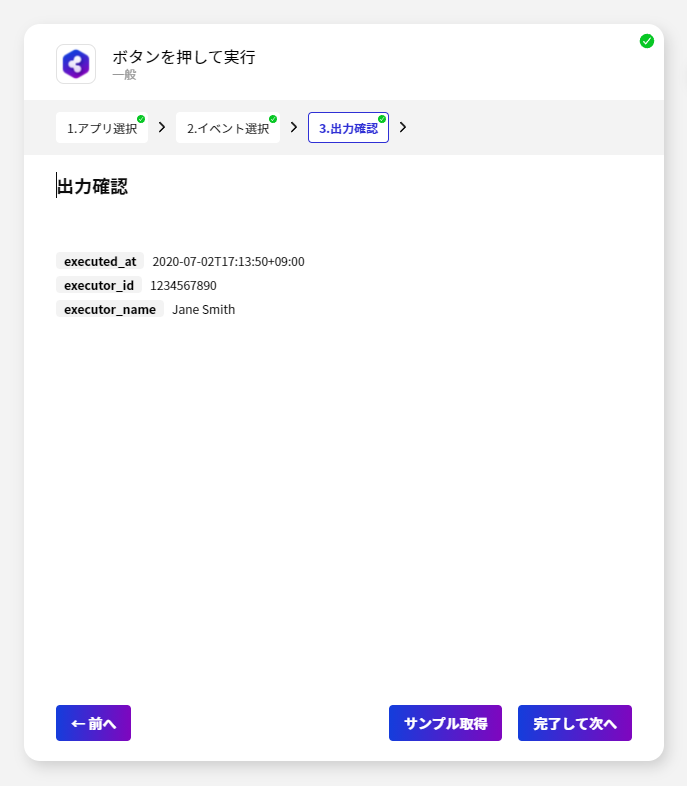
- それぞれのイベントでは出力データが変数として格納されます。内容を確認して「完了して次へ」をクリックしましょう。
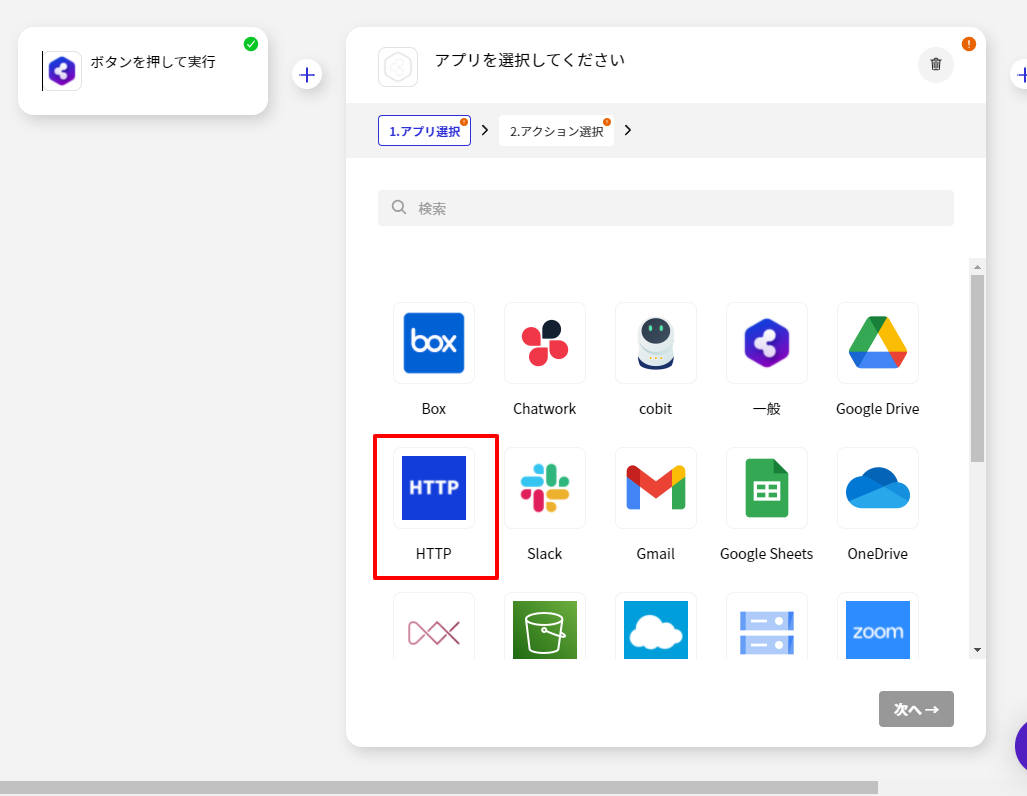
HTTP コネクタの構成
今回のシナリオでは、Spark のデータを取得して BizteX Connect で扱えるようにします。
- CData Connect Server へのアクセスには「HTTPコネクタ」が利用できるので、アプリの一覧から選択します。
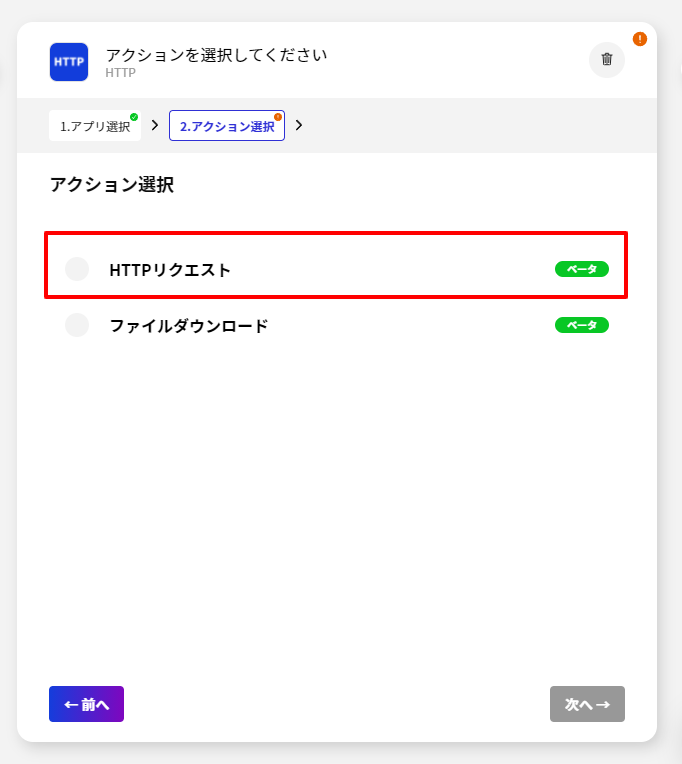
- アクションは「HTTPリクエスト」を指定します。
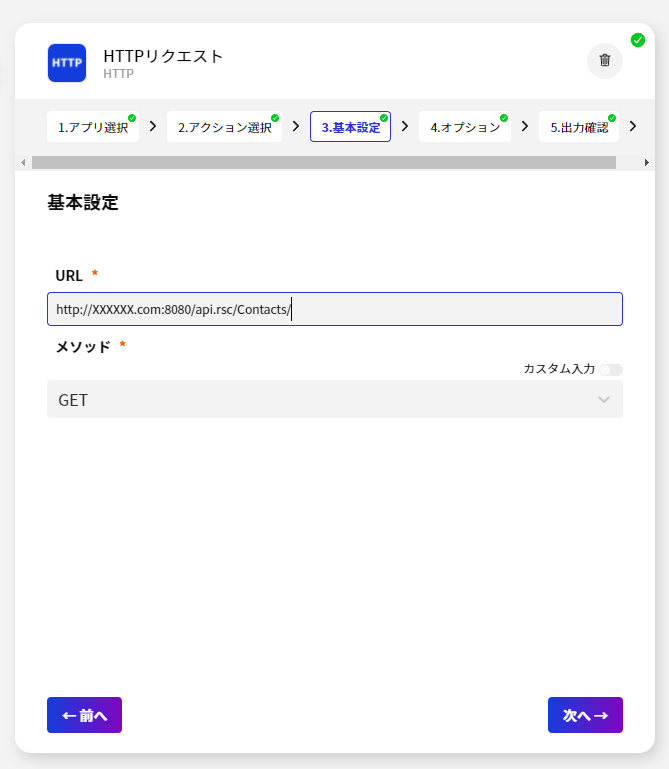
- 続いて、データを取得するためのAPI リクエストを指定します。今回はデータを取得するのでGET リクエストです。対象のURL はCData Connect Server のAPI ドキュメントから取得してきて指定しましょう。
- 基本設定が完了したら、オプションを指定します。ここで最低限必要になるオプションはCData Connect Server への認証情報の指定です。以下のようなJSON 形式でx-cdata-authtoken のプロパティにCData Connect Server で構成したユーザーのトークンを指定すれば接続が行えます。
- すべての設定が完了したら出力結果を確認してみましょう。以下のようにBody の中の「value」オブジェクトの中に配列形式でデータが格納されていることが確認できます。正常にBizteX Connect からSpark のデータが取得できていますね。
- あとはBizteX Connect の各種機能を活用して、さまざまなサービスとの連携を実現できます。


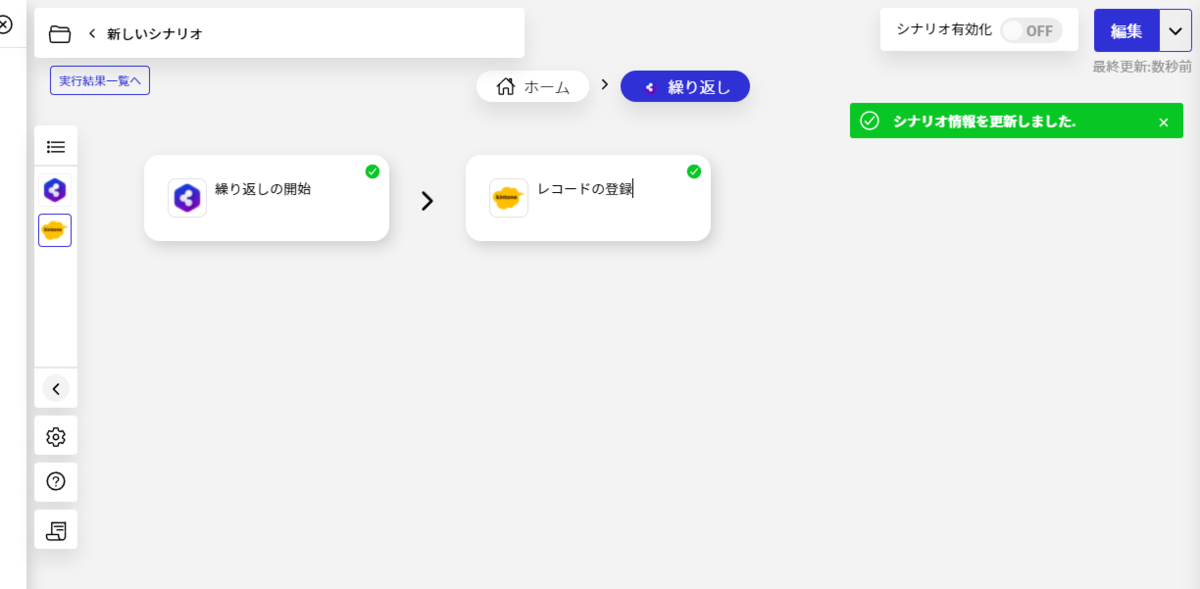
このように、CData Connect Server を経由することで、API 側の複雑な仕様を意識せずにSpark と連携をしたシナリオをBizteX Connect で作成できます。他にも多くのデータソースに対応するCData Connect Server の詳細をこちらからご覧ください。
CData Software は、データアクセスおよびデータ接続ソリューションのリーディングプロバイダーです。CData の標準コネクタはあらゆるツール・ミドルウェアからのSaaS やDB データの連携を簡単にします。
データコネクタ
ETL / ELT ソリューション
クラウド & API 接続
OEM & カスタムドライバー開発
データ分析 & BI
お役立ち情報
© 2025 CData Software, Inc. All rights reserved. Various trademarks held by their respective owners.
This website stores cookies on your computer. These cookies are used to collect information about how you interact with our website and allow us to remember you. We use this information in order to improve and customize your browsing experience and for analytics and metrics about our visitors both on this website and other media. To find out more about the cookies we use, see our Privacy Policy.