各製品の資料を入手。
詳細はこちら →



製品をチェック
Mule アプリケーションからSpark のデータにアクセス:CData JDBC Driver
CData JDBC ドライバとHTTP、SQL を組み合わせれば、Spark のデータのJSON エンドポイントに接続できるMule アプリケーションを簡単に作成できます。
最終更新日:2022-07-28
この記事で実現できるSpark 連携のシナリオ


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData JDBC Driver for SparkSQL はSpark のデータをMule アプリケーションと連携することで、読み、書き、更新、削除といった機能をおなじみのSQL クエリを使って実現します。JDBC ドライバーを使えば、Spark のデータをバックアップ、変換、レポート作成、分析するMule アプリケーションをユーザーは簡単に作成できます。
本記事では、Mule プロジェクト内でCData JDBC Driver for SparkSQL を使用して、Spark のデータのWeb インターフェースを作成する方法を紹介します。作成したアプリケーションを使えば、HTTP 経由でSpark のデータをリクエストして、JSON 形式で結果を取得できます。まったく同様の手順で、すべてのCData JDBC ドライバで250 を超えるデータソースのWeb インターフェースを作成できます。手順は以下のとおりです。
- Anypoint Studio で新しいMule プロジェクトを作る。
- Message Flow にHTTP コネクタを追加する。
- HTTP コネクタのアドレスを設定する。
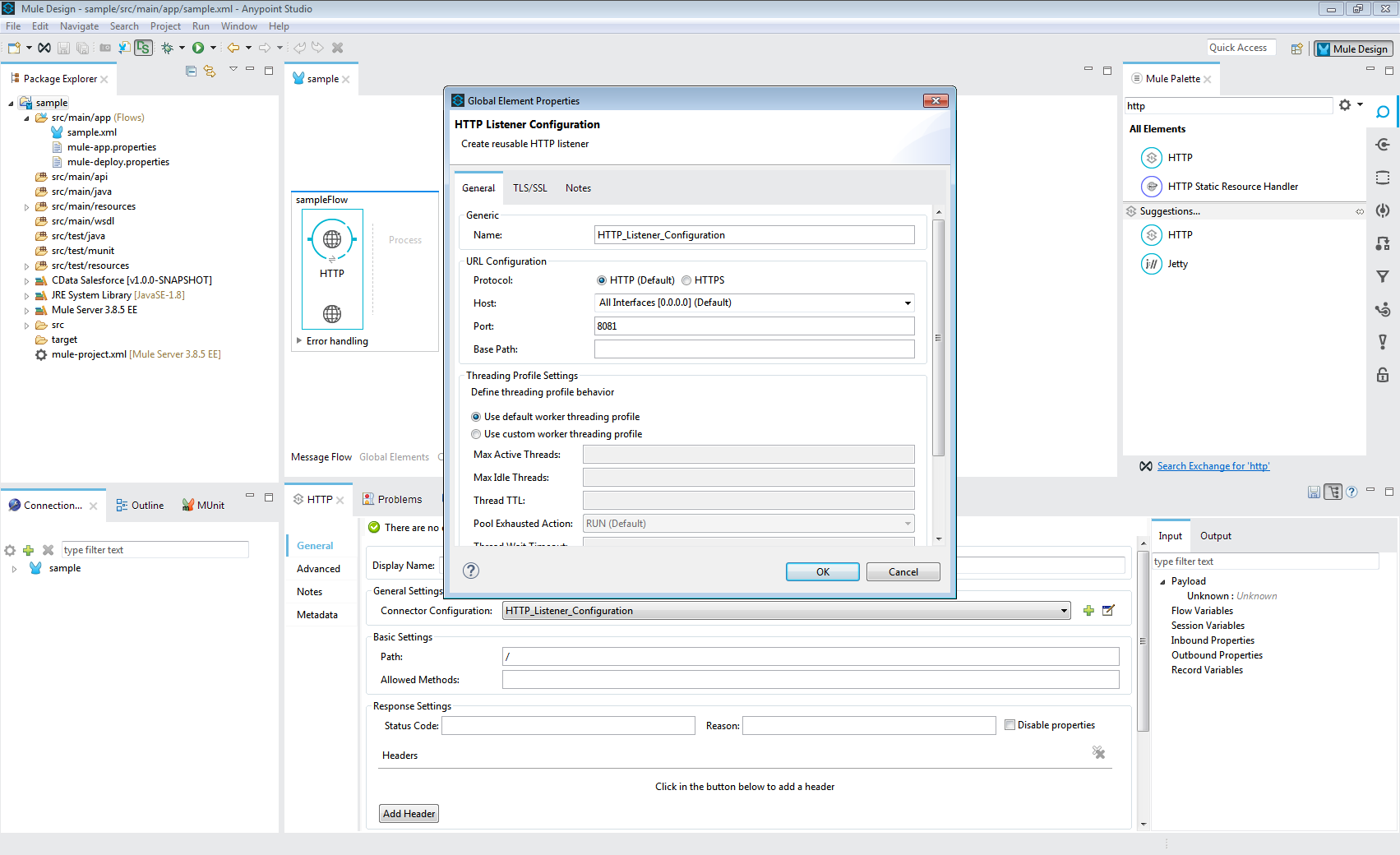
- HTTP コネクタの追加後、Database Select コネクタを同じフローに追加する。
- データベースへの新しい接続を作成し(または既存の接続を編集し)、プロパティを設定する。
- 接続を「Generic Connection」に設定
- Required Libraries セクションでCData JDBC ドライバのJAR ファイルを指定する(例:cdata.jdbc.sparksql.jar)。

- Spark の接続文字列にURL を指定
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
組み込みの接続文字列デザイナ
JDBC 用のURL の作成にサポートが必要な場合は、Spark JDBC Driver に組み込まれた接続文字列デザイナを使用できます。JAR ファイルをダブルクリックするか、コマンドラインからJAR ファイルを実行してください。
java -jar cdata.jdbc.sparksql.jar接続プロパティを入力して、接続文字列をクリップボードにコピーします。
- Driver クラス名をcdata.jdbc.sparksql.SparkSQLDriver に指定します。
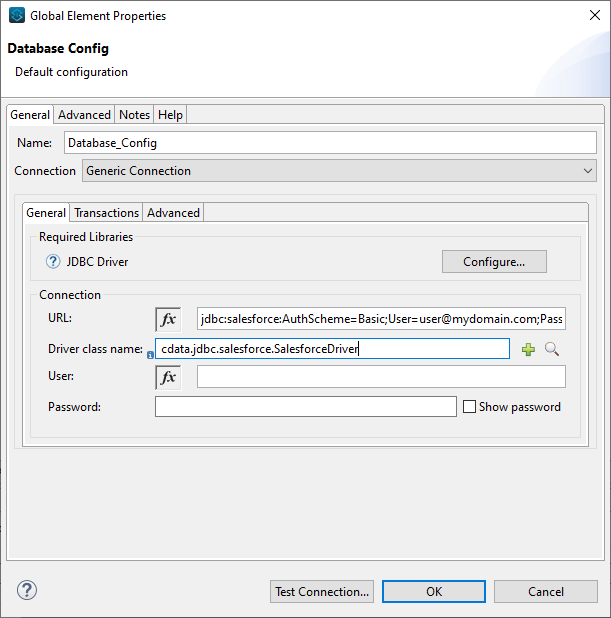
- 「接続テスト」をクリックします。
- SQL Query Text をSpark のデータをリクエストするためのSQL クエリに設定します。例えば、
SELECT City, Balance FROM Customers。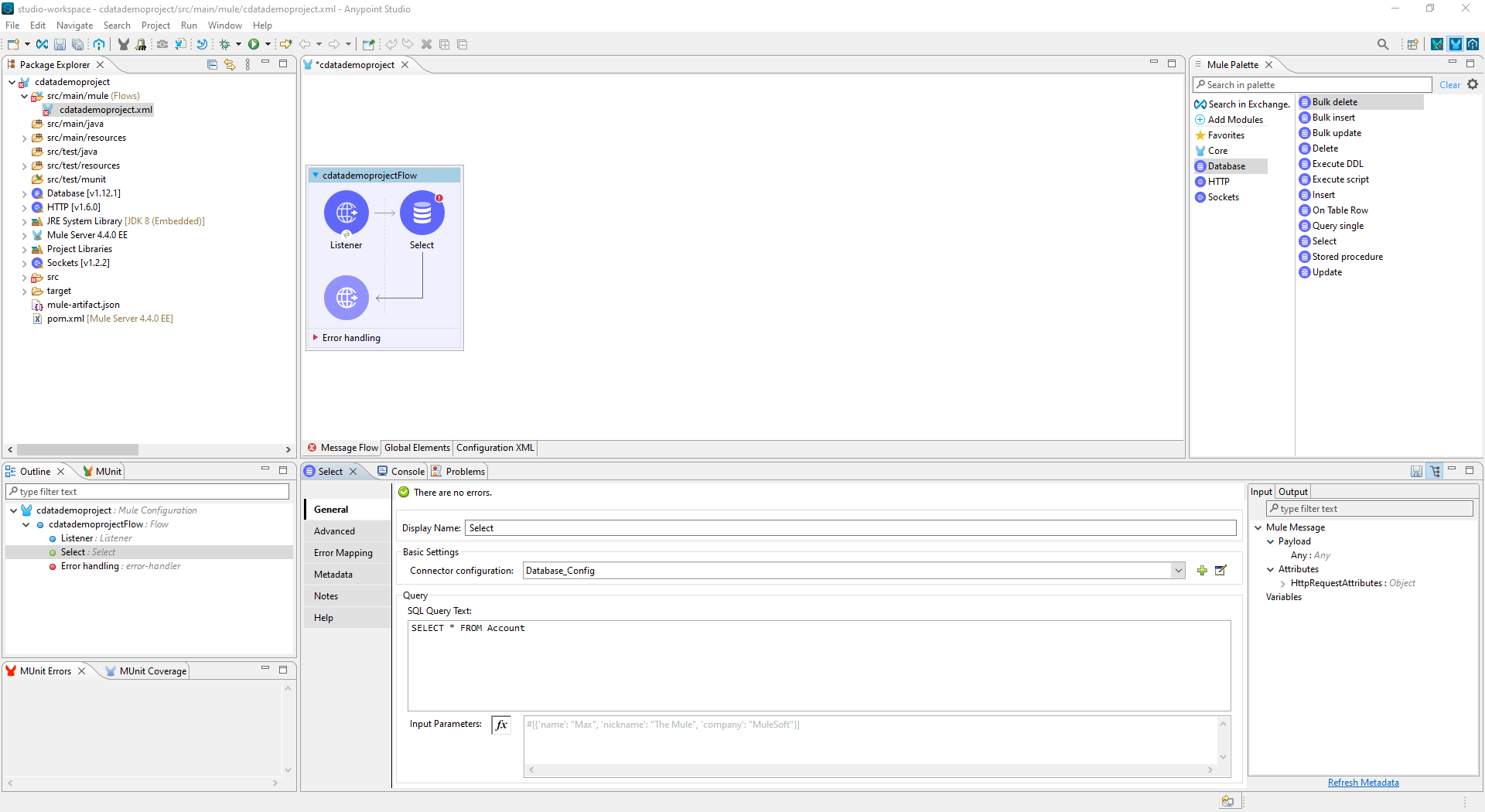
- Transform Message コンポーネントをフローに追加します。
- Output スクリプトを次のように設定して、ペイロードをJSON に変換します。
%dw 2.0 output application/json --- payload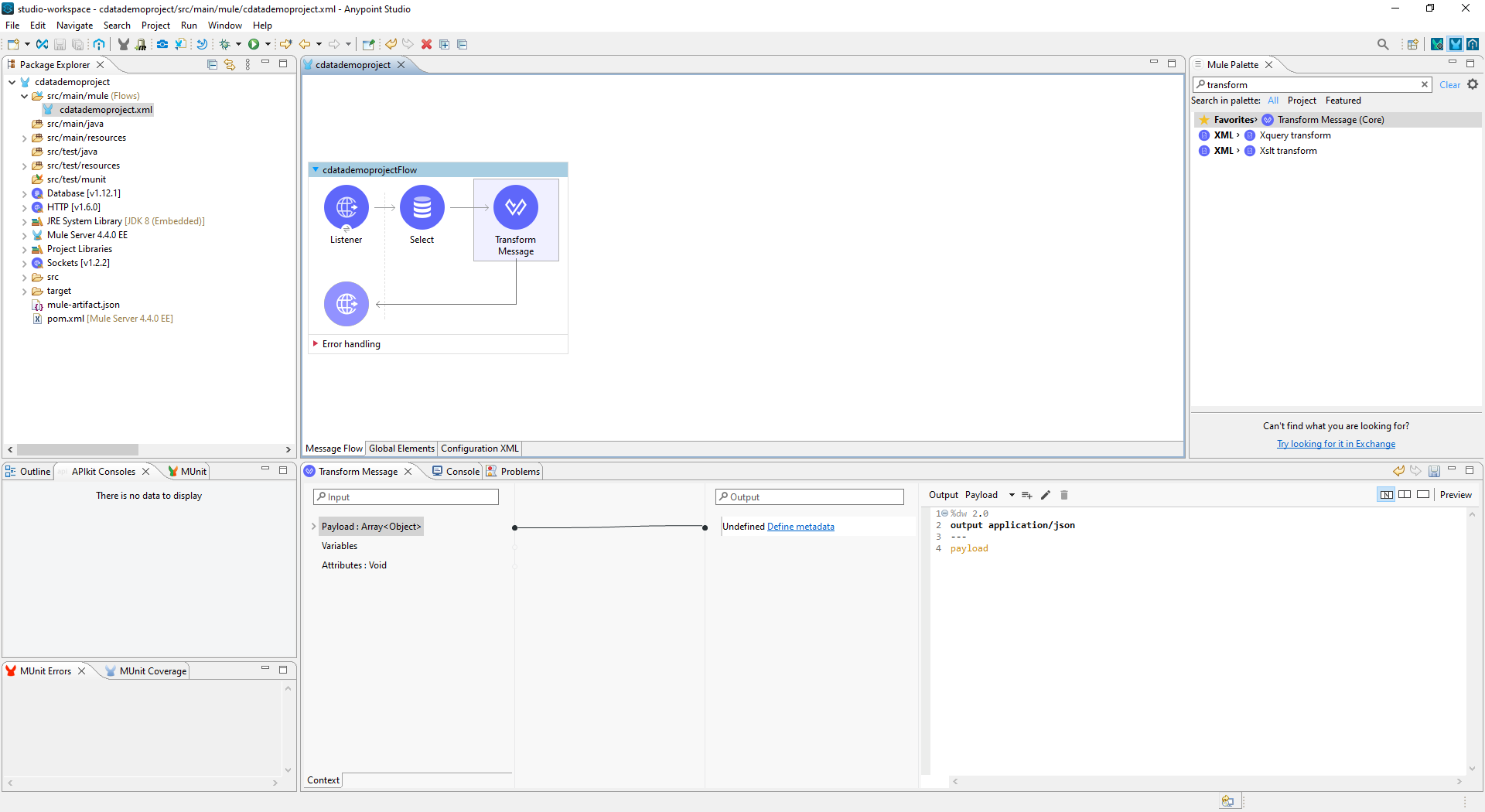
- Spark のデータを閲覧するには、HTTP コネクタ用に設定したアドレスに移動します(デフォルトでは、localhost:8081):http://localhost:8081。Web ブラウザおよびJSON エンドポイントを使用可能な他のツール内で、Spark のデータをJSON として利用できます。
これで、カスタムアプリケーションおよび他のさまざまなBI、帳票、ETL ツールからSpark のデータを(JSON データとして)扱うための簡易なWeb インターフェースを作成できました。Mule アプリケーションからお好みのデータソースにアクセスできる、JDBC Driver for SparkSQL の30日の無償評価版のダウンロードはこちらから。