各製品の資料を入手。
詳細はこちら →



製品をチェック
CData ODBC Driver を使ってAsprovaをSpark と連携
CData ODBC Driver を使って、AsprovaとSpark とのデータ連携を実現します。
最終更新日:2022-02-13
こんにちは!プロダクトスペシャリストの浦邉です。
生産スケジューラ「Asprova」はODBC によるデータベース接続をサポートしているため、これを通してSparkとのデータ連携を行うことが可能です。 通常、SparkなどのSaaS として提供されるアプリケーションにはWeb API でアクセスしますが、CData Spark ODBC Driver によって、RDB にアクセスするのと同じ感覚で、Spark のデータを扱うことができます。 本記事ではSparkからAsprovaへの「品目」データ取り込みの例を通してデータ連携手順を示します。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持った製品です。
- Spark をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレデータソースに対応
- 多様なアプリケーション、ツールにSpark のデータを連携
- ノーコードでの手軽な接続設定
- 標準SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.Asprova 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとSpark への接続設定
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
インストールが完了したら、DSN 設定画面が開くので、必要な接続プロパティを入力してSpark への接続を行います。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
Asprovaでの接続情報の設定
-
メニューの「ファイル」から「データ入出力」を選択し、「データ入出力」ダイアログを開きます。

-
「品目」行のヘッダをダブルクリックし、「データ入出力の編集」ダイアログを開きます。
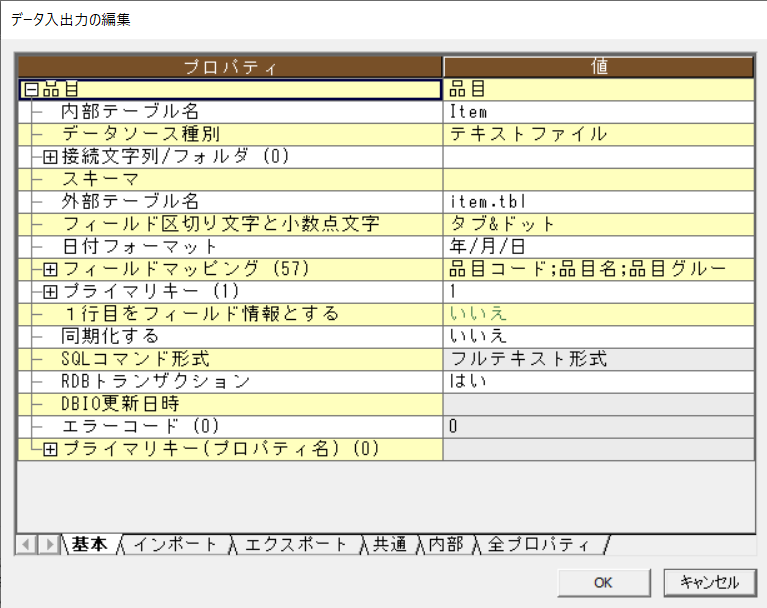
-
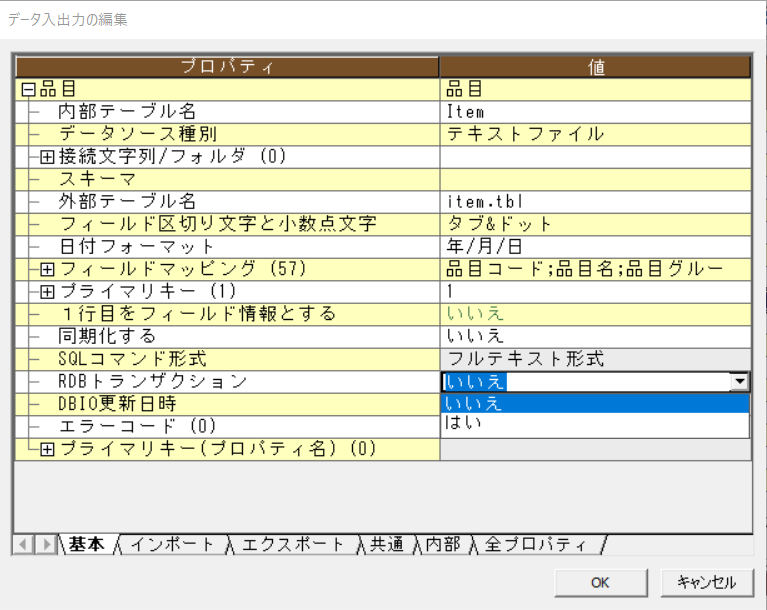
「RDBトランザクション」を「いいえ」に変更し、「OK」を押下します。
データドライバの設定
-
「品目」の「データソースの種類」を「OLE DB」に変更します。
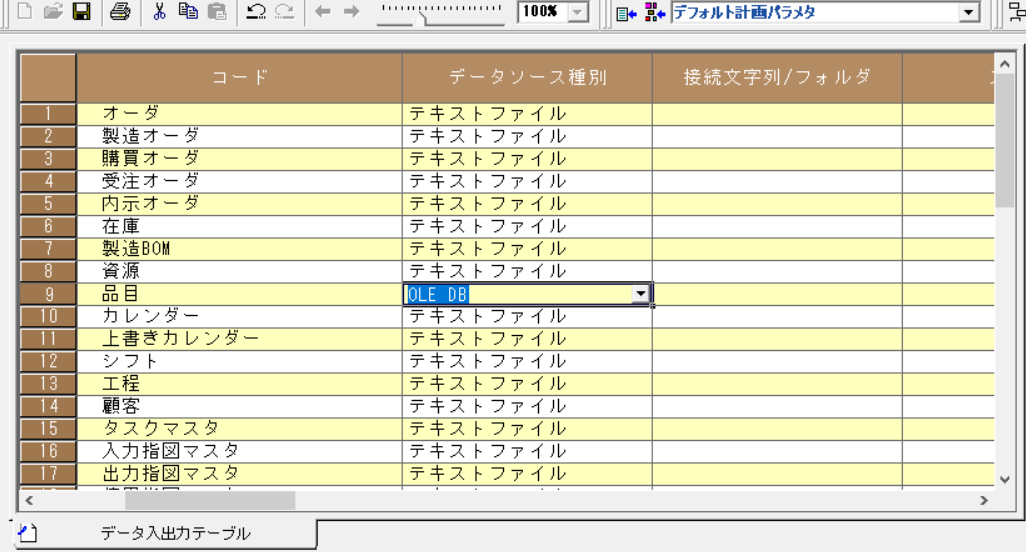
-
「接続文字列/フォルダ」列のボタンを押下し、「データ リンク プロパティ」ダイアログを開きます。 「プロバイダー」タブで「Microsoft OLE DB Provider for ODBC Drivers」を選択し「次へ」を押下します。
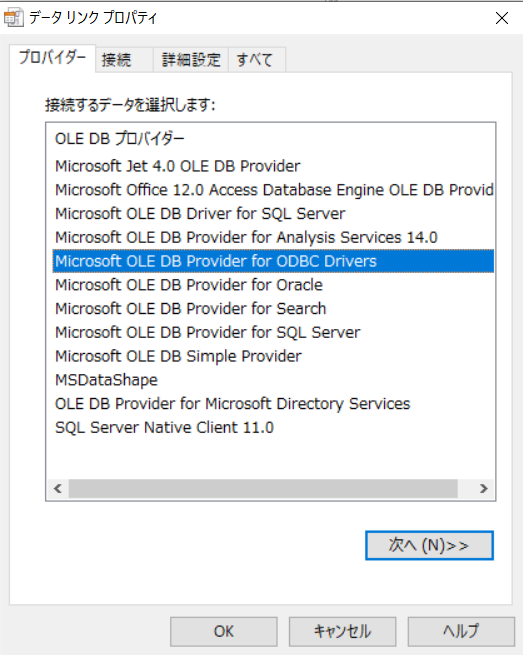
-
「接続」タブで「データソース名を使用する」が選択されていることを確認し、コンボボックスで「CData Spark Source」を選択します。
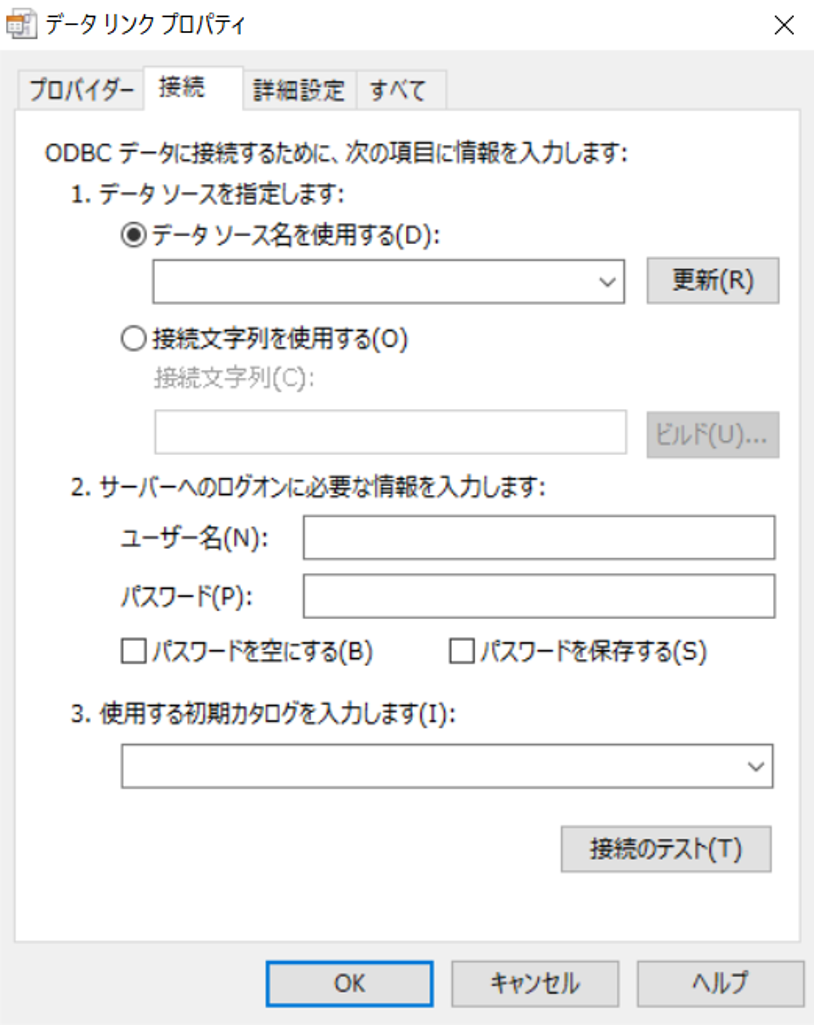
-
「接続のテスト」を押下し「接続のテストに成功しました」というメッセージが表示されればドライバの設定に成功です。
スキーマの設定
-
「外部テーブル名」列のボタンを押下し、「テーブル一覧」ダイアログを開きます。 ここでSparkのテーブル一覧が表示されることを確認してください。
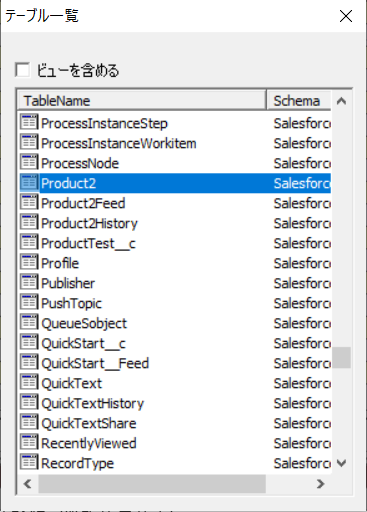
-
出力先テーブル(Asprovaの品目)、入力元テーブルの項目の対応付けを行います。「フィールドマッピング」列のボタンを押下し、「品目-フィールドマッピング」画面を開きます。
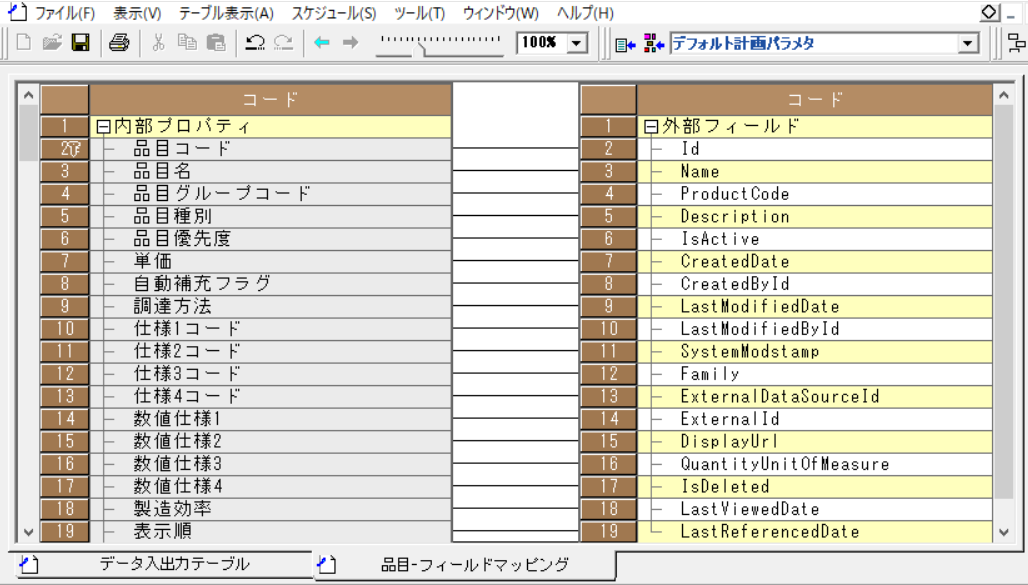
-
画面の二つのテーブルの間で右クリックし、コンテキストメニューの「全削除」を選択します。すべてのマッピングが削除されたことを確認し、項目同士をドラッグアンドドロップでつなぎ上記のマッピングを設定します。
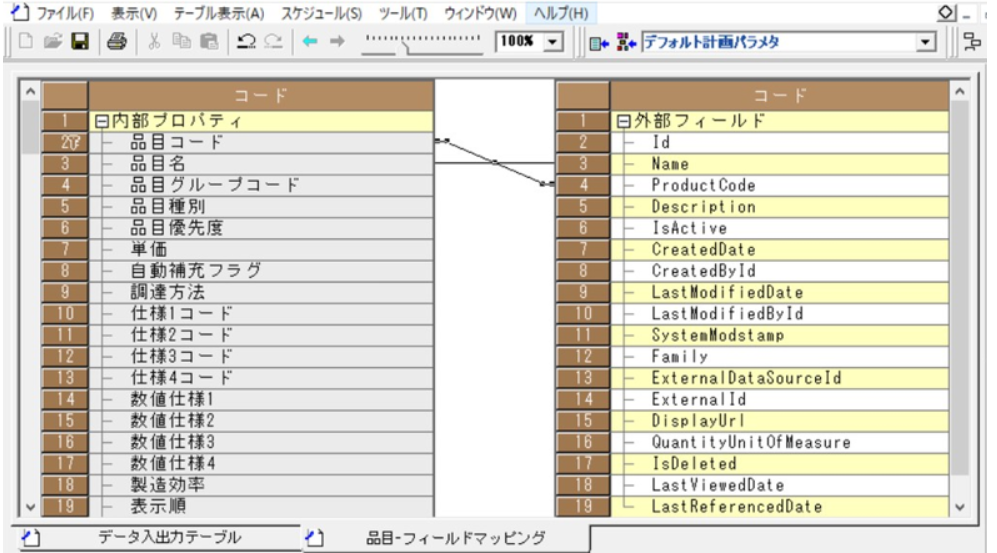
-
これでデータ取り込みの設定は終了です。メニューの「ファイル」から「インポート」をクリックします。画面下のメッセージでエラーが出なければインポートは完了です。
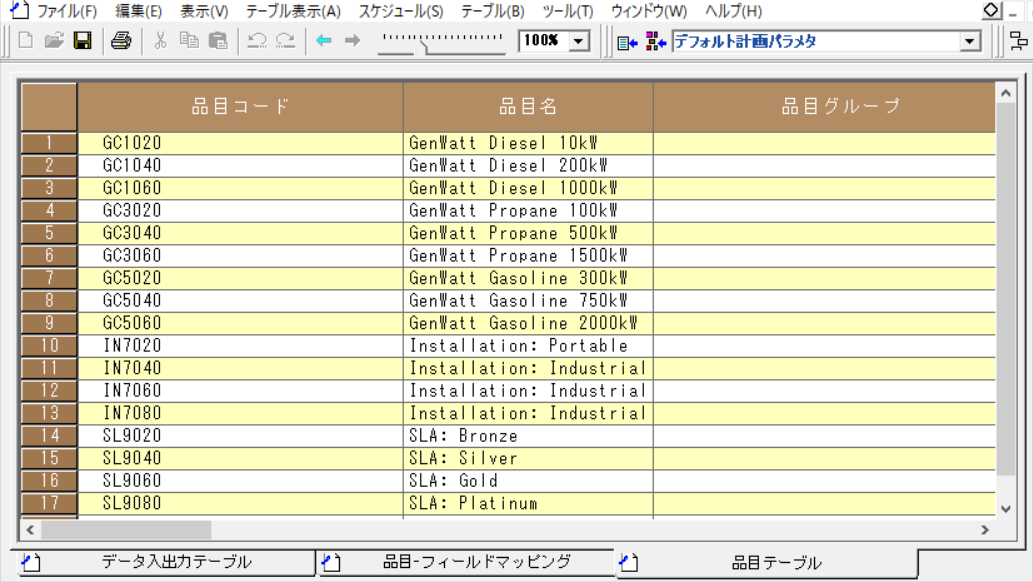
データの確認
メニューの「テーブル表示」から「品目」を選択します。下図のように、Sparkから取り込んだ商品データが表示されれば成功です。