各製品の資料を入手。
詳細はこちら →



製品をチェック
PowerPivot でSpark のデータを連携して取得し分析
この記事では、PowerPivot からCData ODBC Driver を使う方法を説明します。「Table Import Wizard」を使ってSpark のデータをロードします。インポートに使うクエリをビジュアルに作成、あるいはドライバーがサポートするSQL を使って作成できます。
最終更新日:2022-02-13
こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
ODBC プロトコルは多くのBI および帳票ツールで多様なデータベースのデータにアクセスするために使われています。CData ODBC Drive を使って、簡単にSpark をデータ連携できます。この記事では、CData Driver for SparkSQL を使ってPowerPivot にデータをインポートします。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
- Spark をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレミスデータソースに対応
- 多様なアプリケーション、ツールにSpark のデータを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.PowerPivot 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとSpark への接続設定
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
-
接続プロパティが未設定の場合には、DSN(データソース名)の設定を行います。Microsoft ODBC データソースアドミニストレーターを使ってODBC DSN を作成および設定できます。
未指定の場合は、初めにODBC DSN (data source name) で接続プロパティを指定します。ドライバーのインストールの最後にアドミニストレーターが開きます。Microsoft ODBC Data Source Administrator を使用して、ODBC DSN を作成および構成できます。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
Microsoft ODBC データソースアドミニストレーターで必要なプロパティを設定する方法は、ヘルプドキュメントの「はじめに」を参照してください。
- Excel で[PowerPivot]タブの[管理]アイコンをクリックしてPowerPivot を開きます。
[外部データソースの取り込み]から[その他のソース]ボタンをクリックします。
- OLEDB/ODBC ソースオプションを選択して、[次へ]をクリックします。
- [ビルド]をクリックして[データリンクプロパティ]ダイアログを開きます。このダイアログでは、DSN に基づいて自動的に接続文字列がビルドされます。
- [プロバイダー]タブで[Microsoft OLEDB Provider for ODBC Drivers]オプションを選択します。
- [接続]タブで[データソース名を使用する]オプションを選択して、メニューからSpark DSN を選択します。CData Spark Source DSN はインストール時に作成されます。
Spark のデータをインポート
下記の手順に従って、ウィザードを使ってSpark のテーブルからデータをロードします。Spark のカラムをウィザードを使って選択、フィルタ、およびソートすると、PowerPivot は実行されるクエリを生成します。
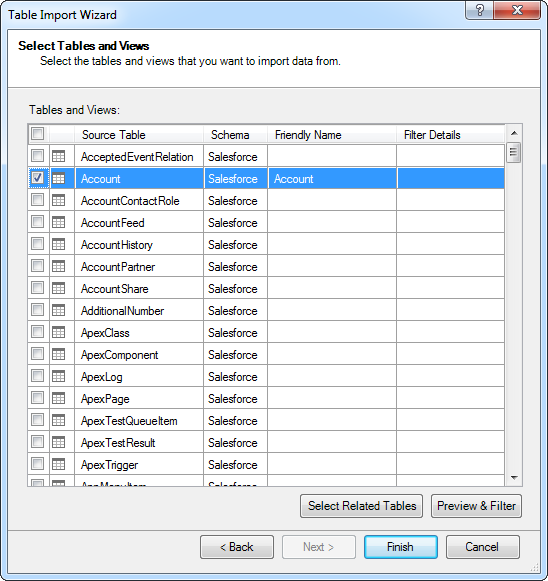
- [テーブルのインポートウィザード]でDSN を選択してから、[テーブルとビューの一覧から選択し、インポートするデータを選択する]オプションを選択すると、Spark で利用できるテーブルとビューのリストを見ることができます。
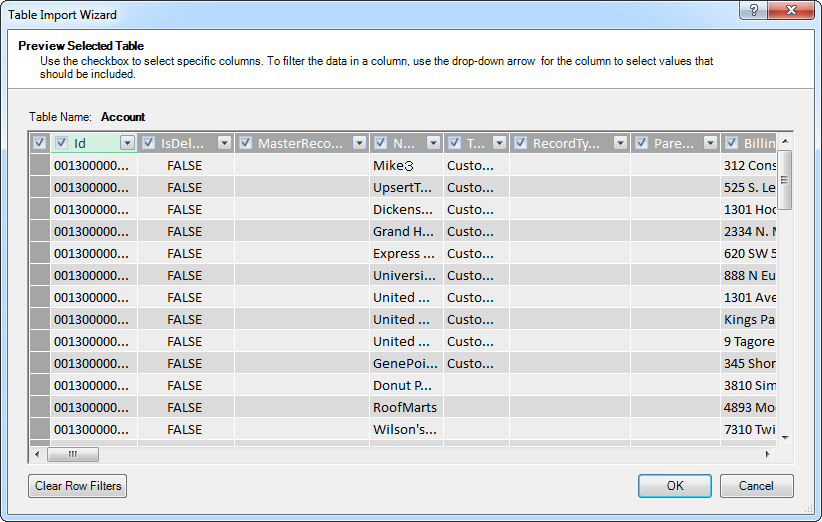
- [プレビューとフィルター]をクリックして特定のカラムを選択、データをソート、およびフィルタをカラム値に基づいて視覚的にビルドします。
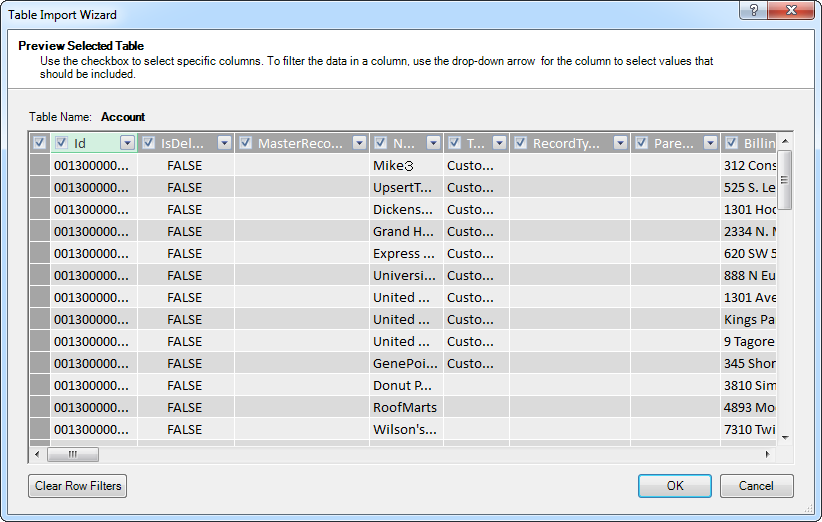
カスタムクエリインポート
インポートするテーブルを選ぶ以外に、特定のカラムをインポートするクエリの指定やフィルタの定義もできます。ドライバーは元になるSpark API に相当する、シンプルで直観的なSQL ダイアレクトをサポートします。
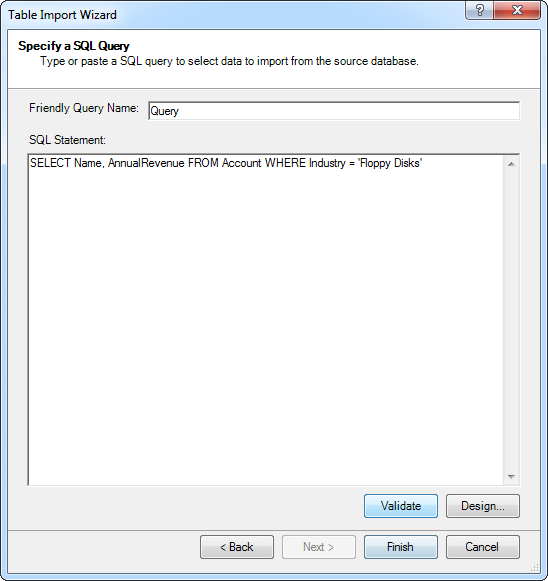
- [テーブルのインポートウィザード]でDSN を選択してから、[インポートするデータを指定するクエリを記述する]オプションを選択してクエリを書きます。
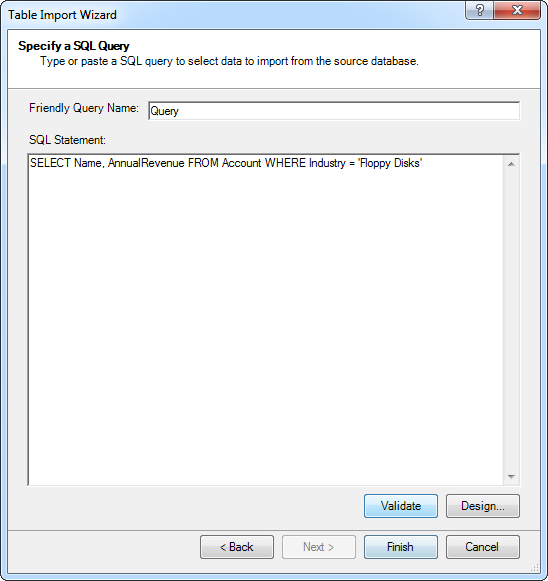
[SQL ステートメント]ボックスにクエリを入れます。[検証]をクリックしてクエリステートメントが有効かどうかを確認します。[デザイン]をクリックして結果をプレビューし、インポートする前にクエリを直します。
WHERE 句を使ってフィルタライテリアクを指定できます。利用可能なSQL 機能の例については、ヘルプドキュメントの「サポートされるSQL」を参照してください。
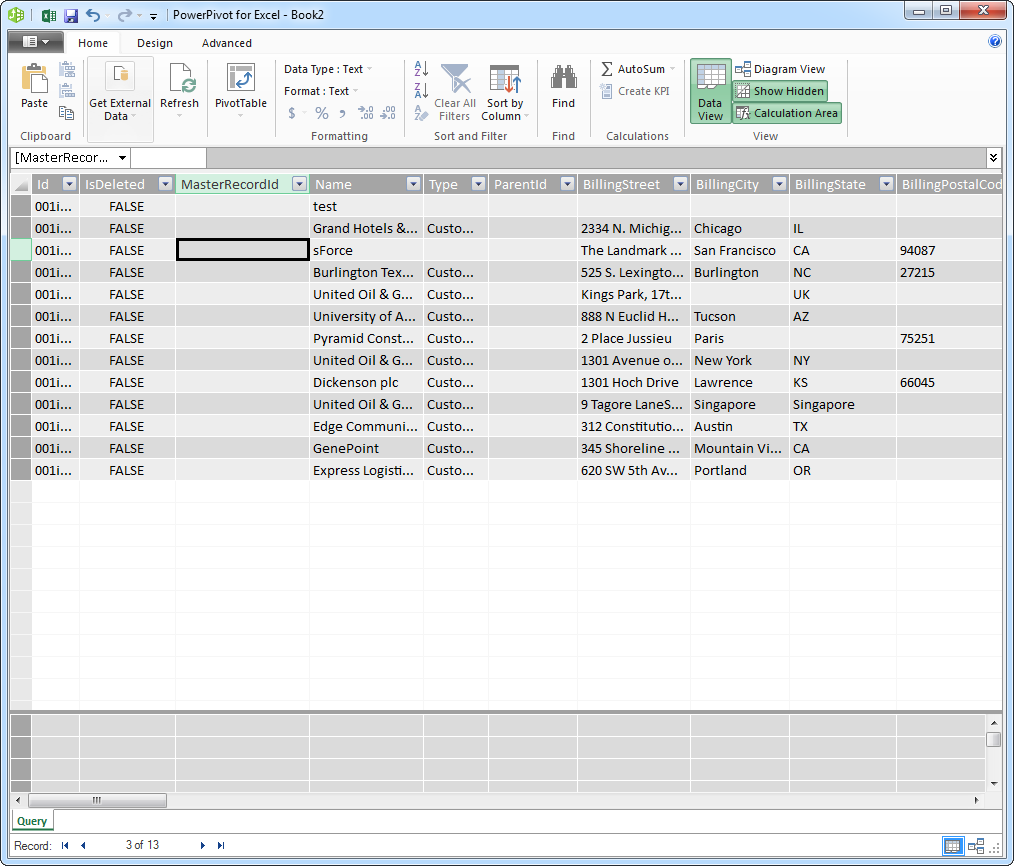
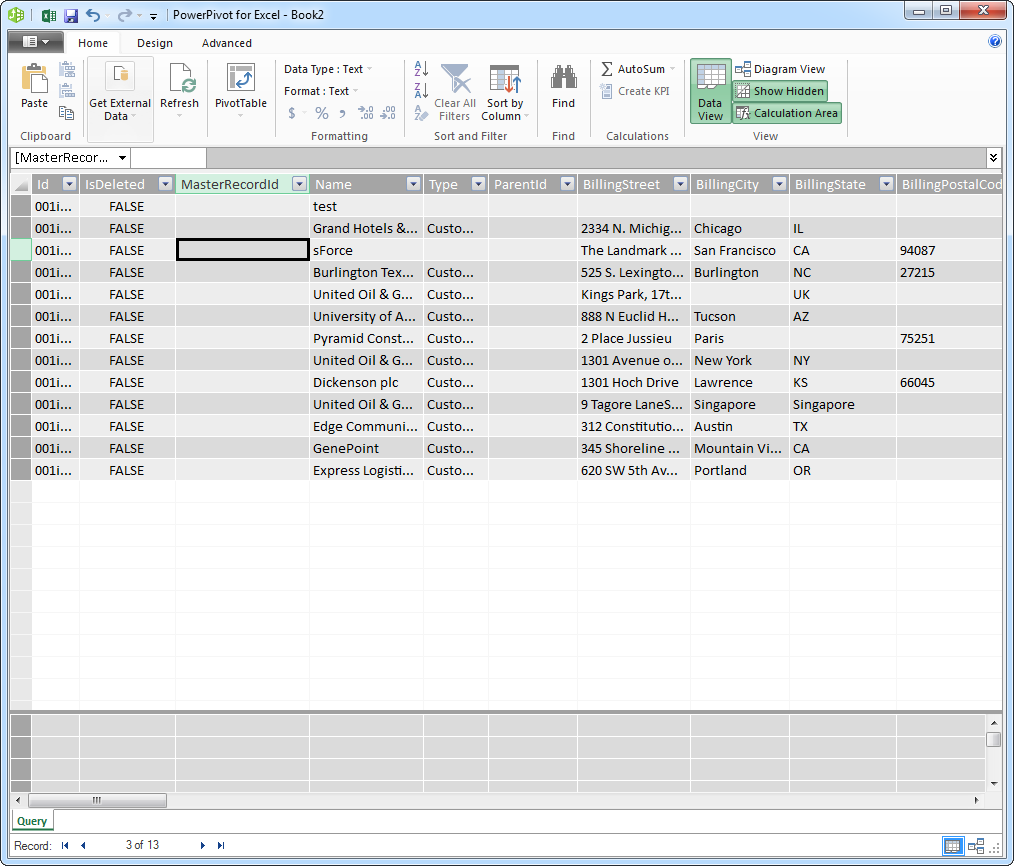
- ウィザードを終了して選んだクエリでデータをインポートします。
Spark からPowerPivot へのデータ連携には、ぜひCData ODBC ドライバをご利用ください
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。