各製品の資料を入手。
詳細はこちら →



製品をチェック
IBM SPSS Modeler にPipedrive のデータをシームレスに読み込む方法
IBM SPSS Modeler とCData ODBC ドライバを使ってPipedrive のデータを取り込む方法をご紹介します。
最終更新日:2023-10-01
この記事で実現できるPipedrive 連携のシナリオ


こんにちは!リードエンジニアの杉本です。
本記事では、データサイエンティスト向けのツールとして有名なIBM SPSS Modeler でCData Driver を利用し、各種クラウドサービスのデータを取り込み、予測モデル作成につなげる方法を紹介したいと思います。
IBM SPSS Modeler とは?
IBMが提供するビジュアル・データサイエンスと機械学習(ML)のソリューションです。
https://www.ibm.com/jp-ja/products/spss-modeler
SPSS Modeler はローコードで予測モデルの作成およびモデルの作成に必要なデータ加工などのプレパレーションを実施できます。今回の記事では、このSPSS Modeler にPipedrive のデータを取り込んでみたいと思います。データの取得ができれば、予測モデルの作成などに自在に活用できます。
連携シナリオ
さて、今回の記事ではSPSS からPipedrive に接続していきますが、このときに必要となるのがCData ODBC ドライバです。
SPSS にはODBC を経由して他サービスに接続する機能が標準提供されています。この機能とCData が提供しているODBC Drivers ラインナップを組み合わせることで、各種クラウドサービスのAPI やデータベースにシームレスにアクセスすることができるようになります。
とは言っても、説明だけではイメージできない部分もあると思うので、実際に連携を試してみましょう。
CData Pipedrive ODBC Driver のインストール
最初にCData Pipedrive ODBC Driver を対象のマシンにインストールします。
以下のページから30日間のトライアルがダウンロードできます。
Pipedrive ドライバーページインストーラーを入手後、対象のマシンでセットアップを進めていきます。
セットアップが完了すると接続設定画面が表示されるので、Pipedrive への認証に必要な情報を入力します。
Pipedrive 接続プロパティの取得・設定方法
Pipedrive には、接続および認証する2つの方法があります。Basic およびOAuth です。
Basic 認証
Basic 認証で認証するには:- API トークンを取得します。
- Pipedrive ポータルを開きます。
- ページ右上のアカウント名をクリックします。Pipedrive はドロップダウンリストを表示します。
- 会社設定 -> Personal Preferences -> API -> Generate Token に移動します。
- 生成されたAPI トークンの値を記録します。また、CompanyDomain を控えておきます。これは、PipeDrive ホームページのURL に表示されます。(これは会社の開発者用サンドボックスのURL です。)
- 次の接続プロパティを設定します。
- APIToken:取得したAPI トークンの値。
- CompanyDomain:開発者サンドボックスURL のCompanyDomain。
- AuthScheme:Basic。
- 承認されたユーザー名とパスワードでログインします。
API トークンはPipedrive ポータルに保存されます。これを取得するには、会社名をクリックし、ドロップダウンリストを使用して会社設定 -> Personal Preferences -> API に移動します。
OAuth 認証
ユーザー名やパスワードへのアクセスを保有していない場合や、それらを使いたくない場合にはOAuth ユーザー同意フローを使用します。認証方法については、ヘルプドキュメントの「OAuth 認証」セクションを参照してください。
あとは「接続のテスト」ボタンをクリックし、接続が成功したら、「接続ウィザード」の「OK」ボタンをクリックして保存します。
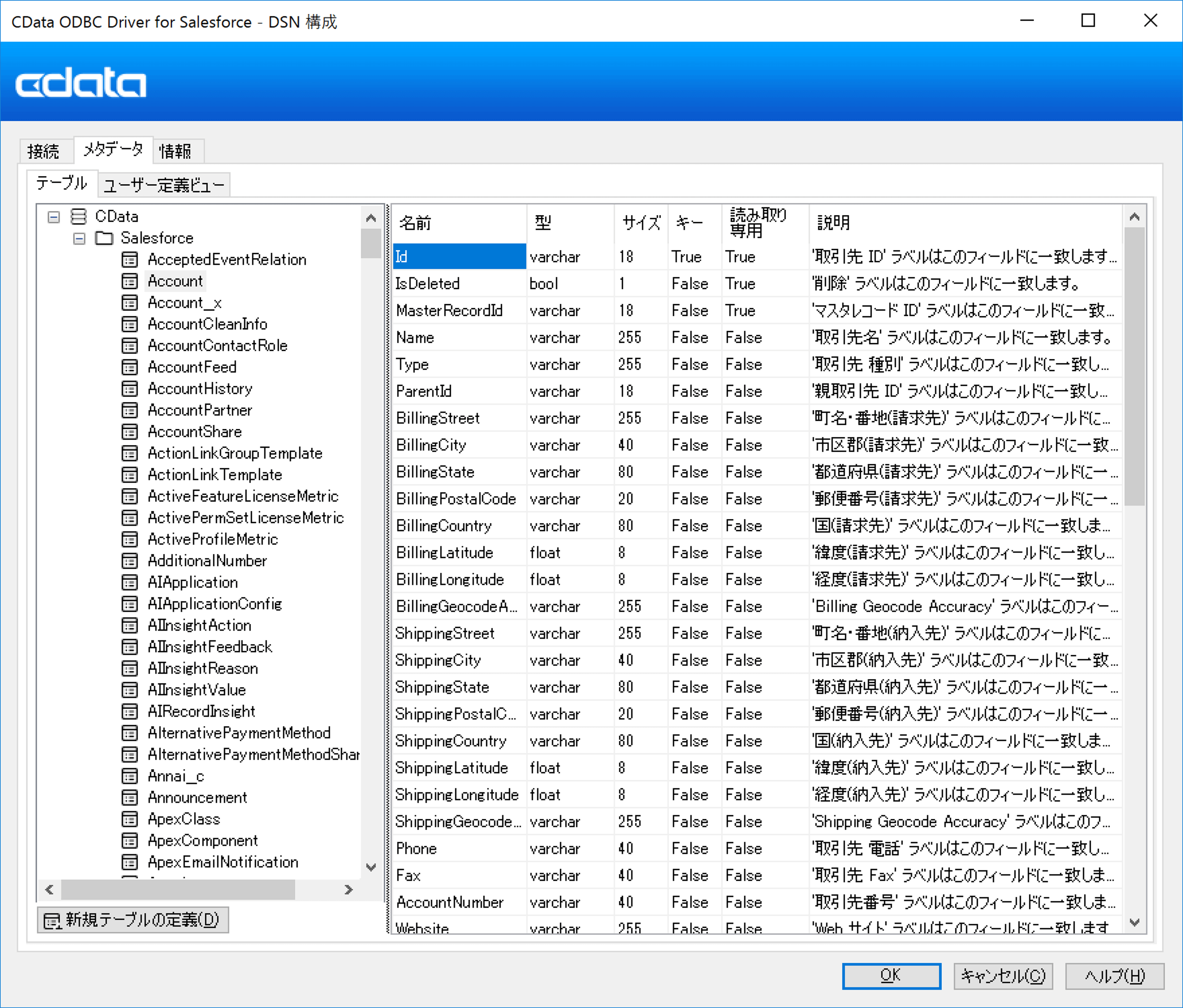
接続完了後、メタデータタブから利用できるテーブル・ビューの情報を確認できます。
ここで予めPipedrive のどのオブジェクト、項目を利用するか確認しておくと良いでしょう。
SPSS Modeler を立ち上げて新規ストリームを作成
それではSPSS Modeler を使ってPipedrive のデータを取り込んでみましょう。
Windows のスタートメニューから「IBM SPSS Modeler Subscription」を立ち上げて、新しいストリームを作成します。
データベース入力を追加
まず「入力」タブにある「データベース」をストリーム上に配置します。
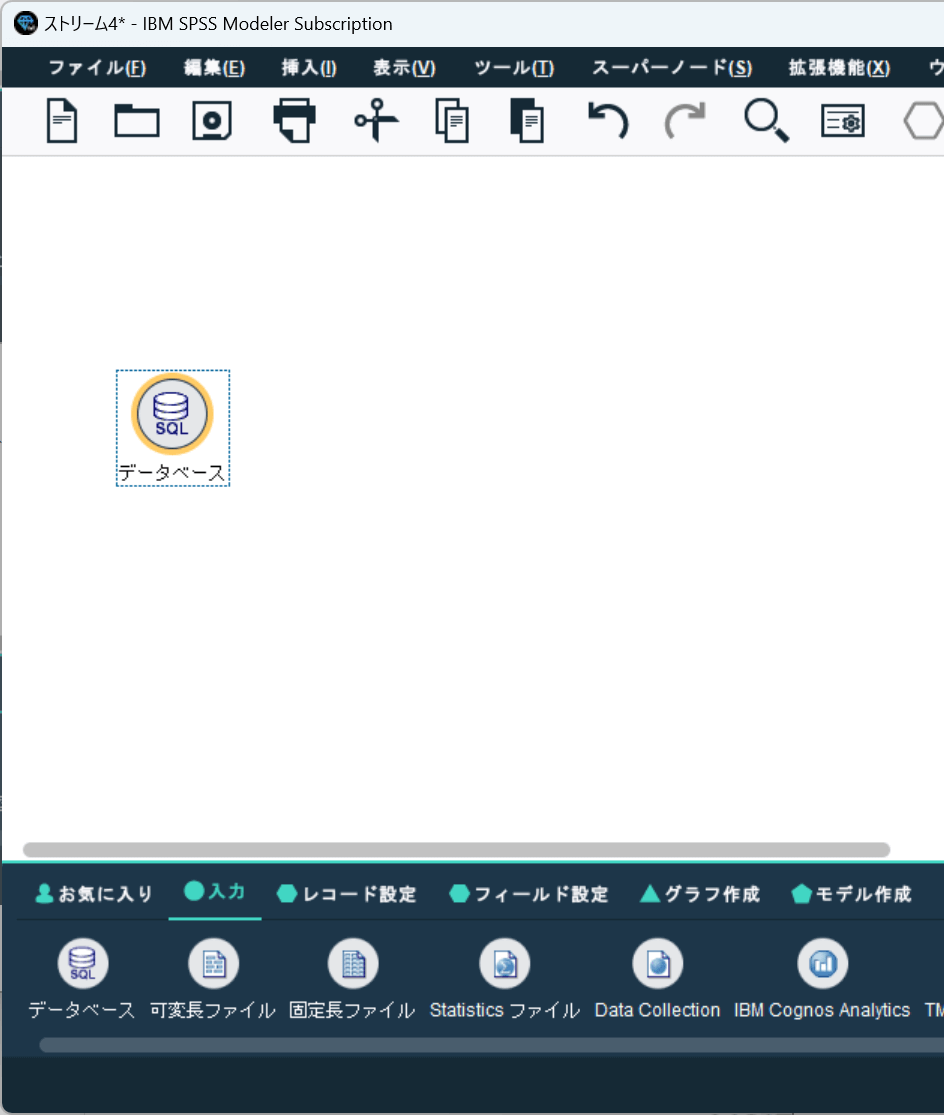
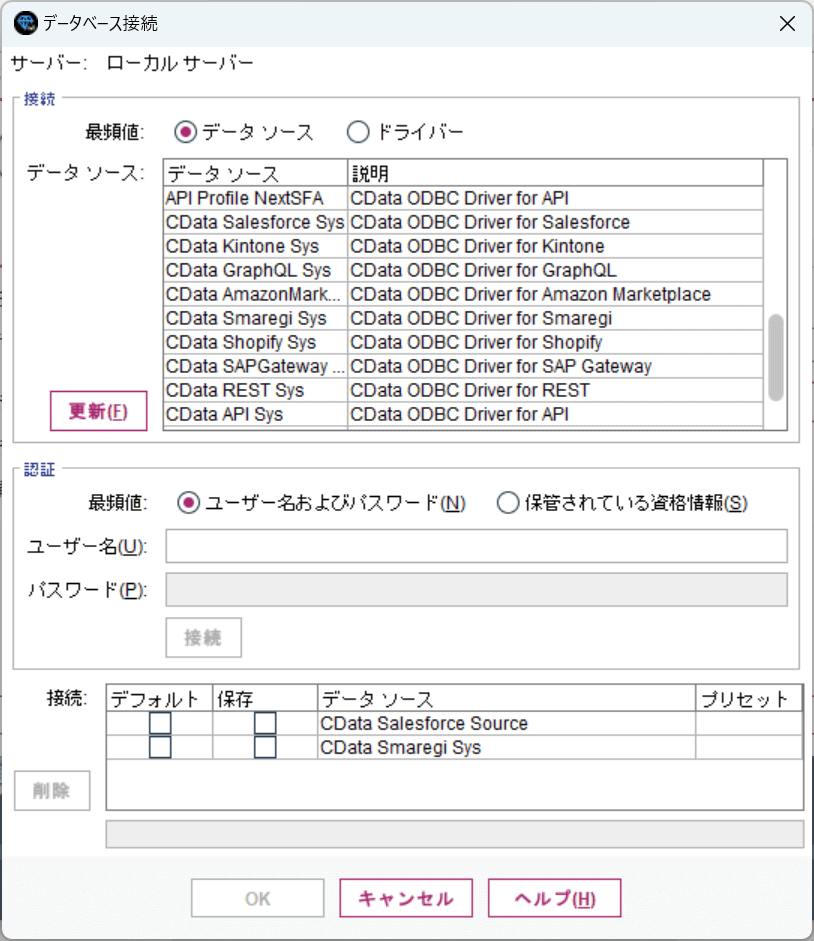
配置したアイコンをダブルクリックするとデータベースの接続設定画面が出てくるので、「データソース」から「新規データベース接続の追加」をクリックします。
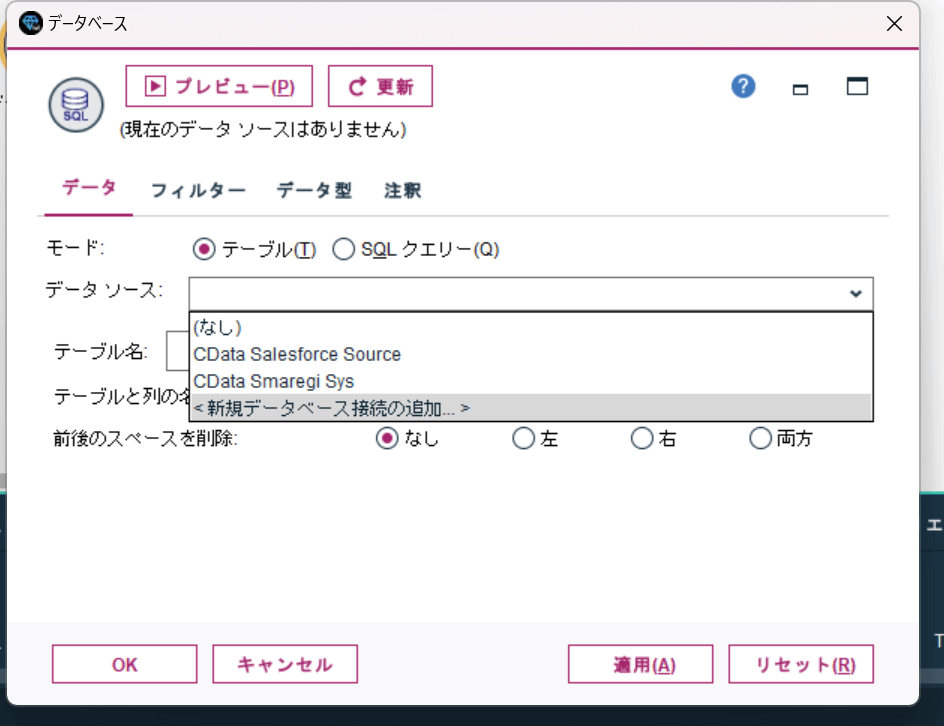
すると以下のようにODBC DSNの一覧が表示されるので、先程構成したPipedrive のDSNを選択して、「接続」をクリックしましょう。
ユーザー名・パスワードなどの認証情報は事前に入力してあるので、空白のままで構いません。これでPipedrive への接続を確立できます。
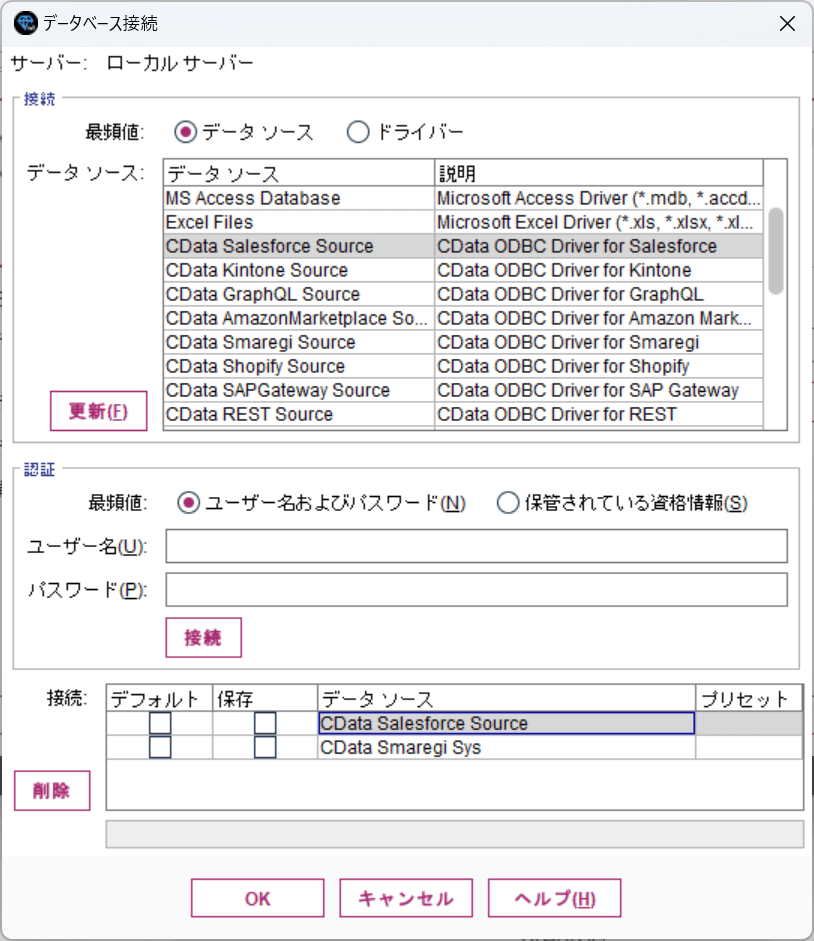
接続を追加したら、どんなデータを取り込むのか、テーブルまたはSQLクエリーで設定します。
とりあえず手軽に取り込めるテーブル名での指定を行ってみます。「データの選択」をクリックします。
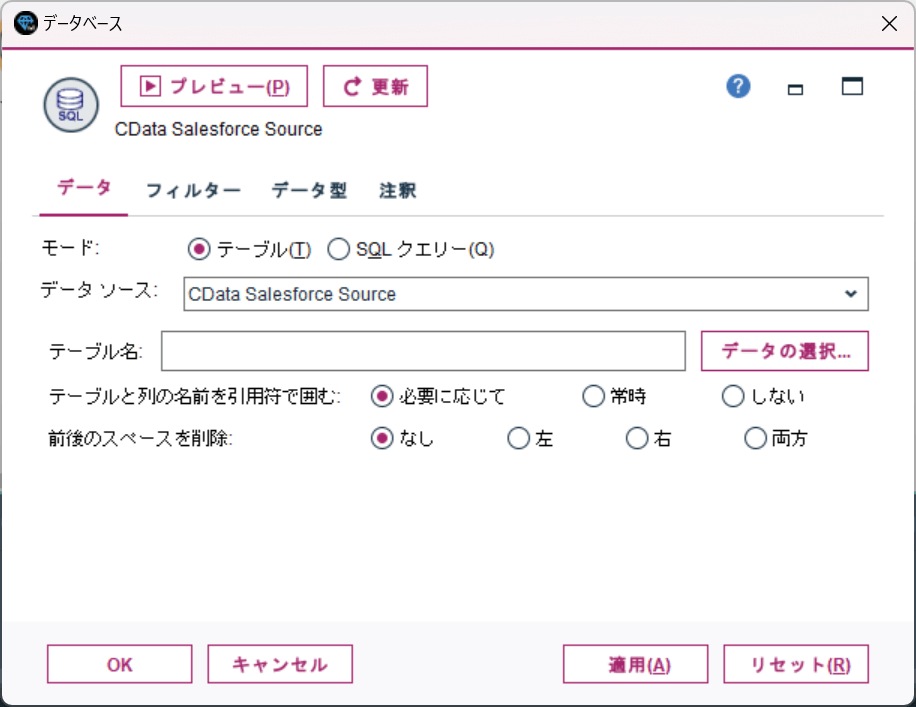
表示されたテーブル・ビューの一覧から取り込みたい対象のテーブルを選択しましょう。
フィルタリング・データ型の設定・データの取得
あとはフィルター条件として、どの項目を取り込むかどうかという設定や、
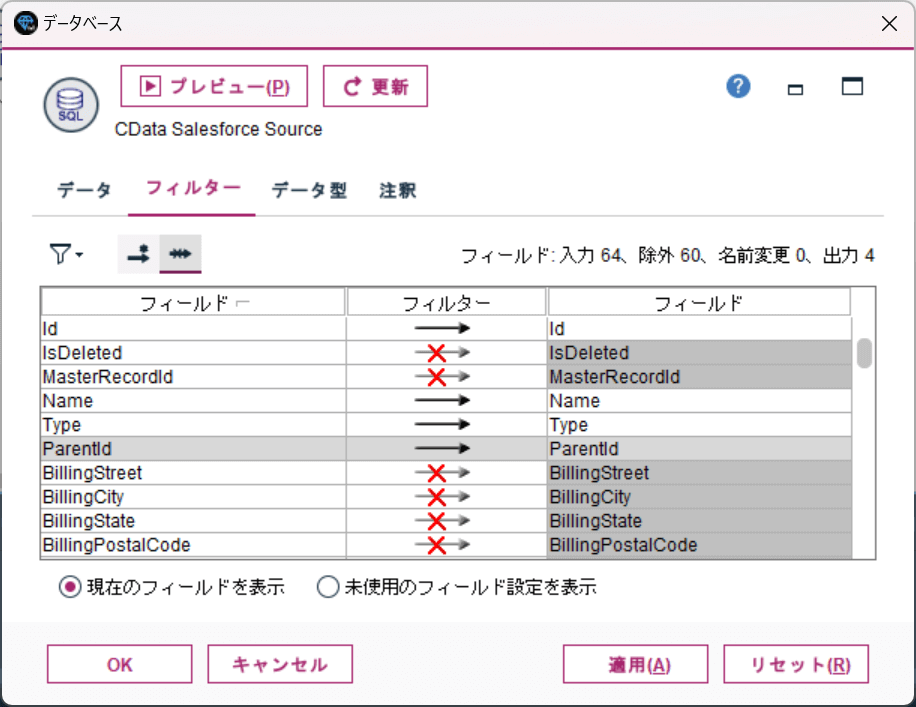
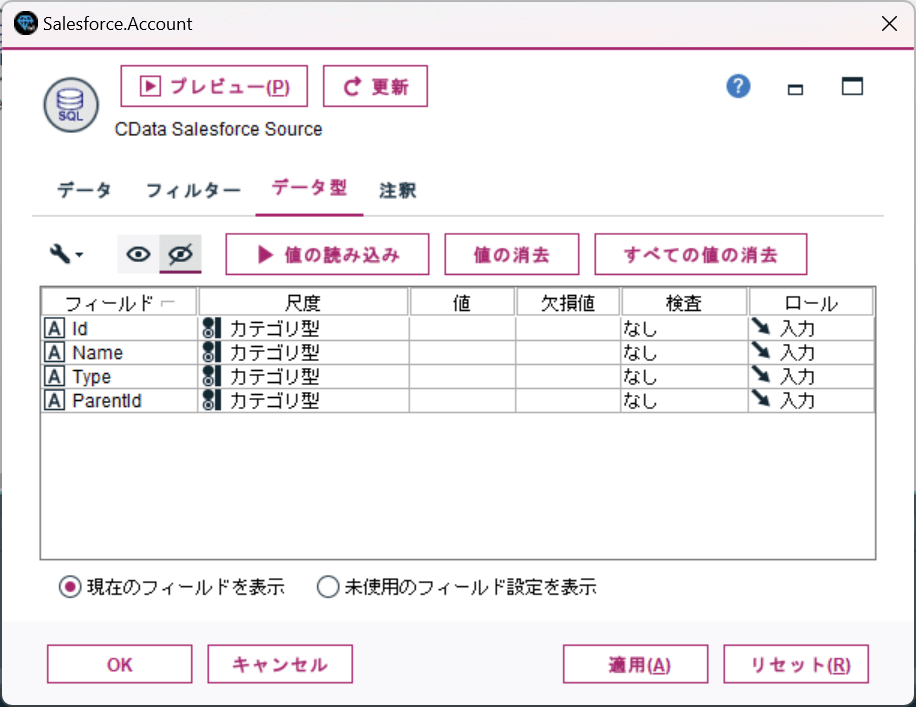
モデル作成の際に利用するデータ型やロールを設定すれば、データ取得の準備はOKです。
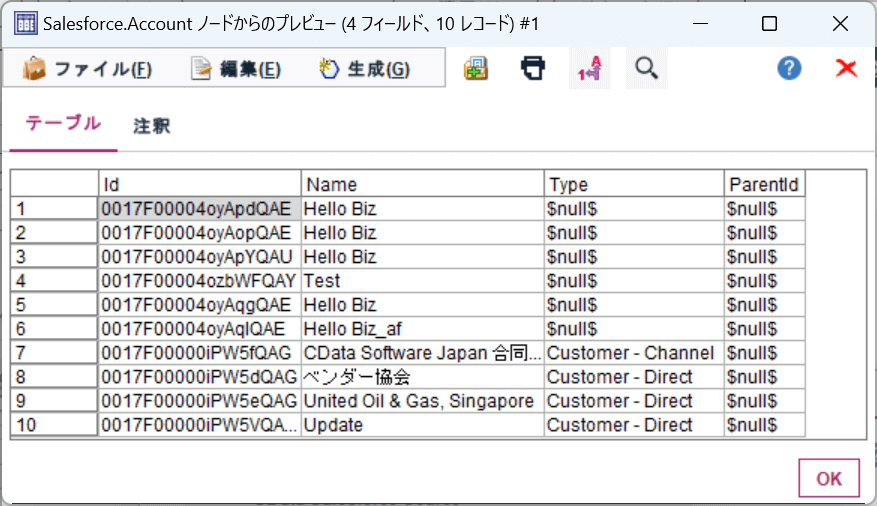
データのプレビューを確認すると、以下のようにPipedrive のデータを確認できました。
せっかくなので、「データ検査」を実行してデータの傾向も確認してみましょう。
以下のように各項目のデータの最小・最大・平均、有効な値かどうかなどが確認できます。
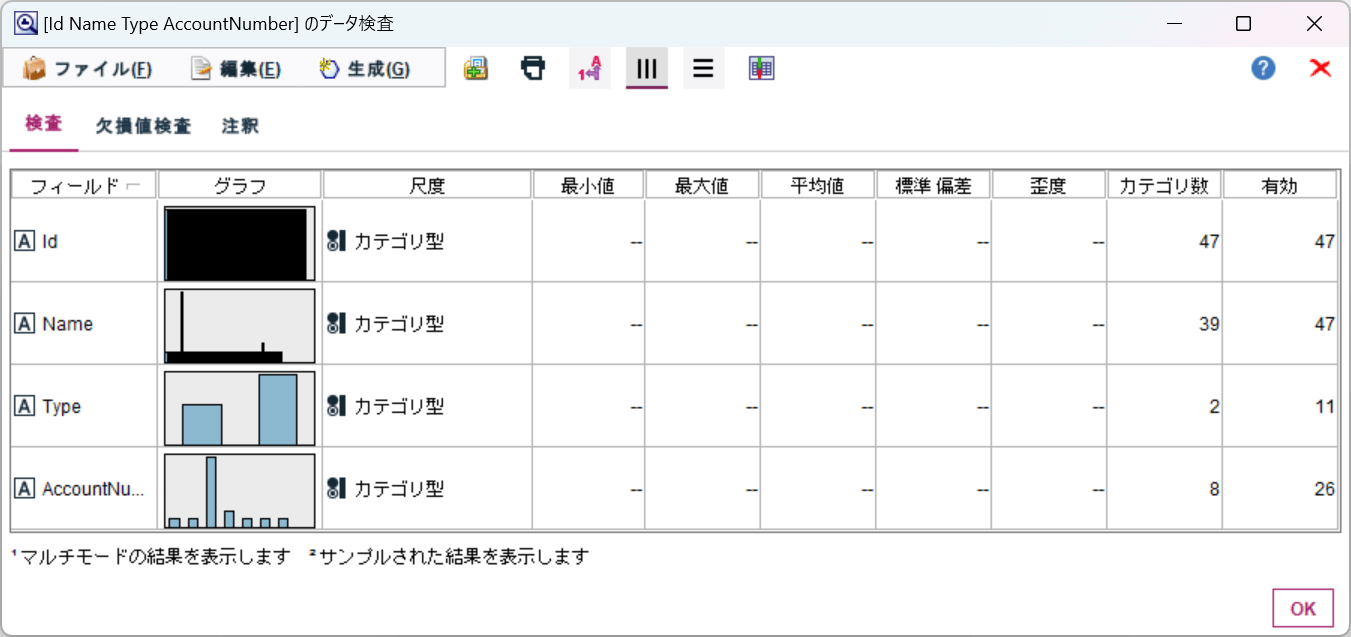
このように、とてもシンプルな手順でPipedrive のデータをSPSS Modeler に取り込むことができました。
これで、予測モデル作成などより複雑なタスクにPipedrive のデータを簡単に活用できます。
おわりに
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、RDB、NoSQL データをSPSS Modeler からコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。