各製品の資料を入手。
詳細はこちら →



製品をチェック
Spark ODBC データソースとの間にInformatica マッピングを作成
Informatica にSpark へのODBC 接続を作成し、Spark のデータを参照および転送。
最終更新日:2022-06-09
こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
Informatica はデータを転送、変換するための強力で洗練された手段です。CData ODBC Driver for SparkSQL は、Informatica の強力なデータ転送・変換機能とシームレスに連携可能な、業界で実証済みの標準ドライバです。このチュートリアルでは、Informatica PowerCenter でSpark のデータを転送および参照する方法を説明します。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
- Spark をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレミスデータソースに対応
- 多様なアプリケーション、ツールにSpark のデータを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.Informatica 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとSpark への接続設定
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
Spark への接続に関する情報と、Windows およびLinux 環境でのDSN の設定手順を以下で説明します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
Windows
接続プロパティが未設定の場合は、まずODBC DSN(データソース名)で設定します。ドライバーのインストールの最後にアドミニストレーターが開きます。Microsoft ODBC データソースアドミニストレーターを使ってODBC DSN を作成および設定できます。
Linux
CData ODBC Driver for SparkSQL をLinux 環境にインストールする場合、ドライバーのインストールによってDSN が事前に定義されます。DSN を変更するには、システムデータソースファイル(/etc/odbc.ini)を編集し、必要な接続プロパティを定義します。
/etc/odbc.ini
[CData SparkSQL Source]
Driver = CData ODBC Driver for SparkSQL
Description = My Description
Server = 127.0.0.1
これらの構成ファイルの使用方法については、オンラインのヘルプドキュメントを参照してください。
Customers データへのリンクテーブルを作成する
「オブジェクトエクスプローラー」からリンクテーブルを作成してライブCustomers データにアクセスする方法は、次のとおりです。
ODBC 接続を作成する
下記の手順に従って、Informatica PowerCenter のSpark に接続します。
- Informatica Developer ツールで、リポジトリに接続してプロジェクトを作成しておきます。
- 「Connection Explorer」ペインで右クリックし、「Create a Connection」をクリックします。
- 「New Database Connection」ウィザードが表示されたら、接続に名前とID を入力し、「Type」メニューで「ODBC」を選択します。
- 「Connection String」プロパティに
jdbc:sparksql:Server=127.0.0.1;を入力します。
注意:Linux オペレーティングシステムで作業している場合は、「Driver Manager for Linux」プロパティをunixODBC 2.3.x に設定します。
Spark のデータオブジェクトを作成する
Spark へのODBC 接続を作成したら、Informatica でSpark エンティティにアクセスできるようになります。下記の手順に従って、Customers エンティティをプロジェクトに追加します。
- 「Object Explorer」でプロジェクトを右クリックし、「New」->「Data Object」をクリックします。
- ウィザードが表示されたら「Relational Data Object」オプションを選択します。
- 「Connection」ボックス横にある「Browse」ボタンをクリックし、先に作成したODBC 接続を選択します。
- 既存のリソースからデータオブジェクトを作成するオプションを選択し、「Resource」ボックス横にある「Browse」ボタンをクリックします。
- ダイアログが表示されたら、「Show Default Schema Only」オプションの選択を解除してODBC 接続のノードを展開します。必要なエンティティを選択します。
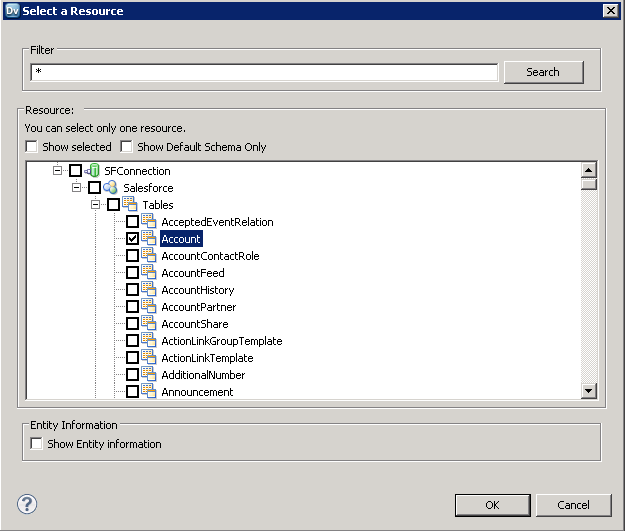
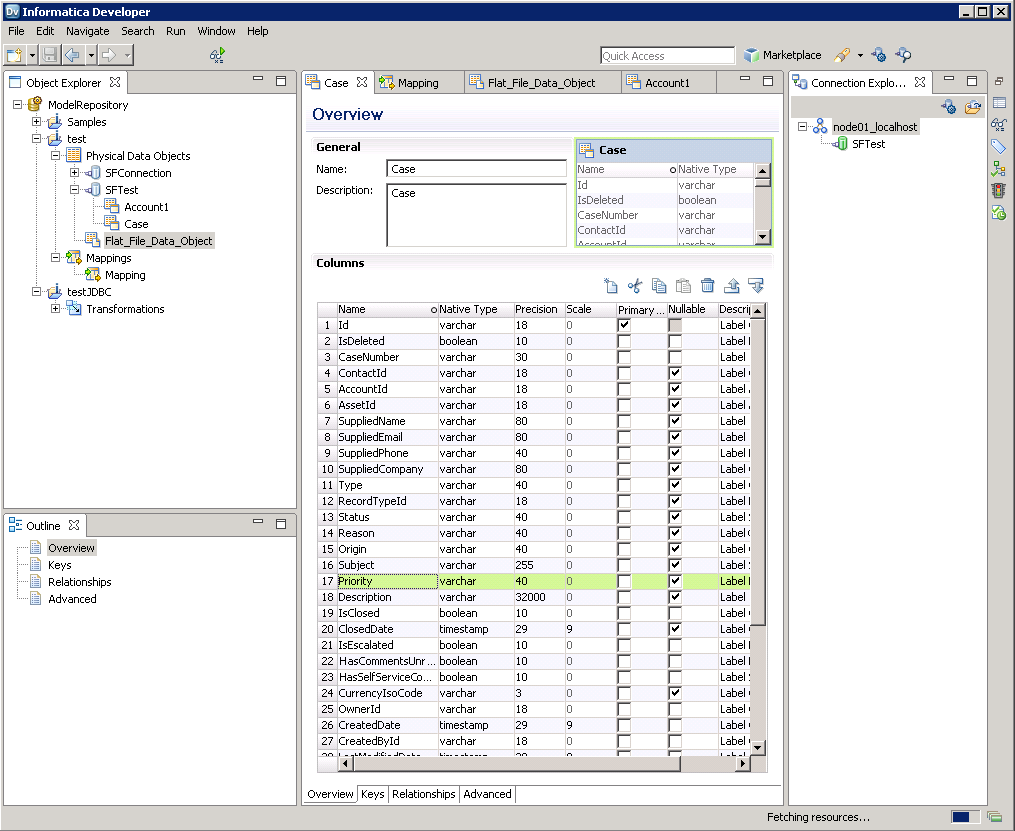
これで、Data Viewer でテーブルをブラウズできます。テーブル用ノードを右クリックし「Open」をクリックします。「Data Viewer」ビューで「Run」をクリックします。
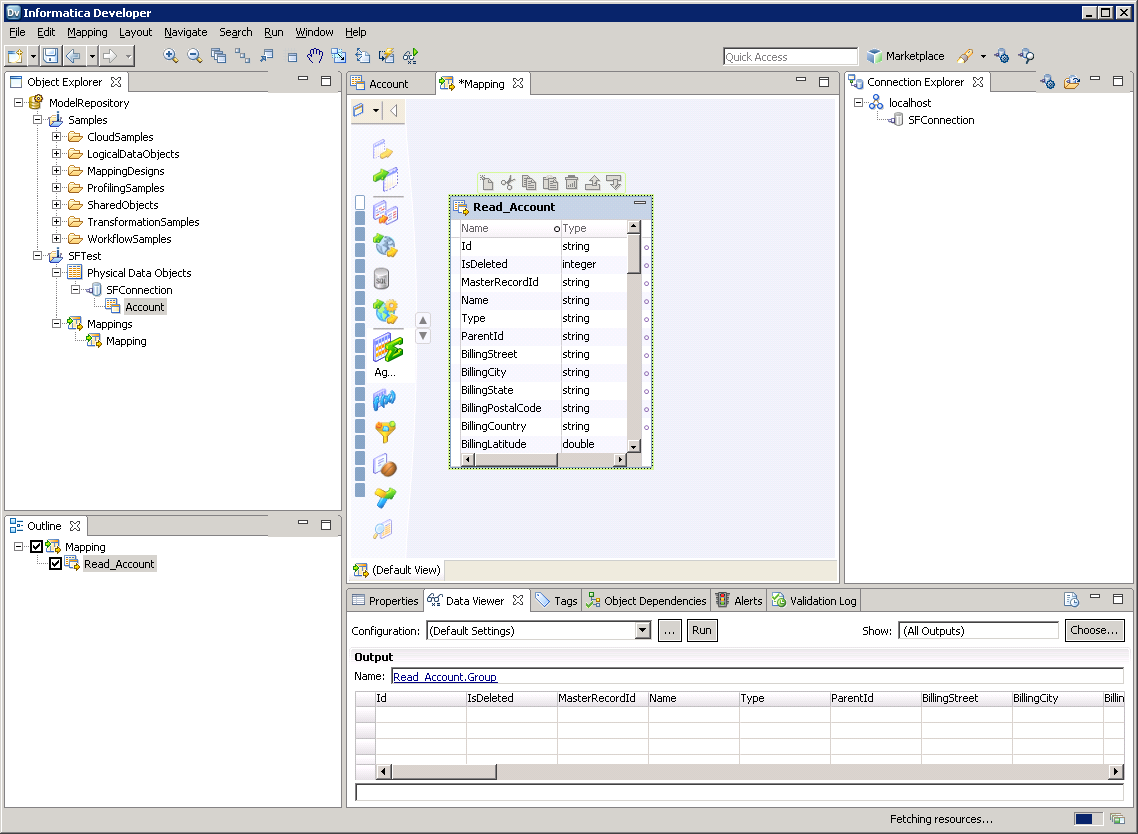
マッピングを作成する
下記の手順に従って、Spark ソースをマッピングに追加します。
- 「Object Explorer」でプロジェクトを右クリックし、「New」->「Mapping」をクリックします。
- Spark 接続のノードを展開してから、テーブル用のデータオブジェクトをエディタ上にドラッグします。
- ダイアログが表示されたら「Read」オプションを選択します。
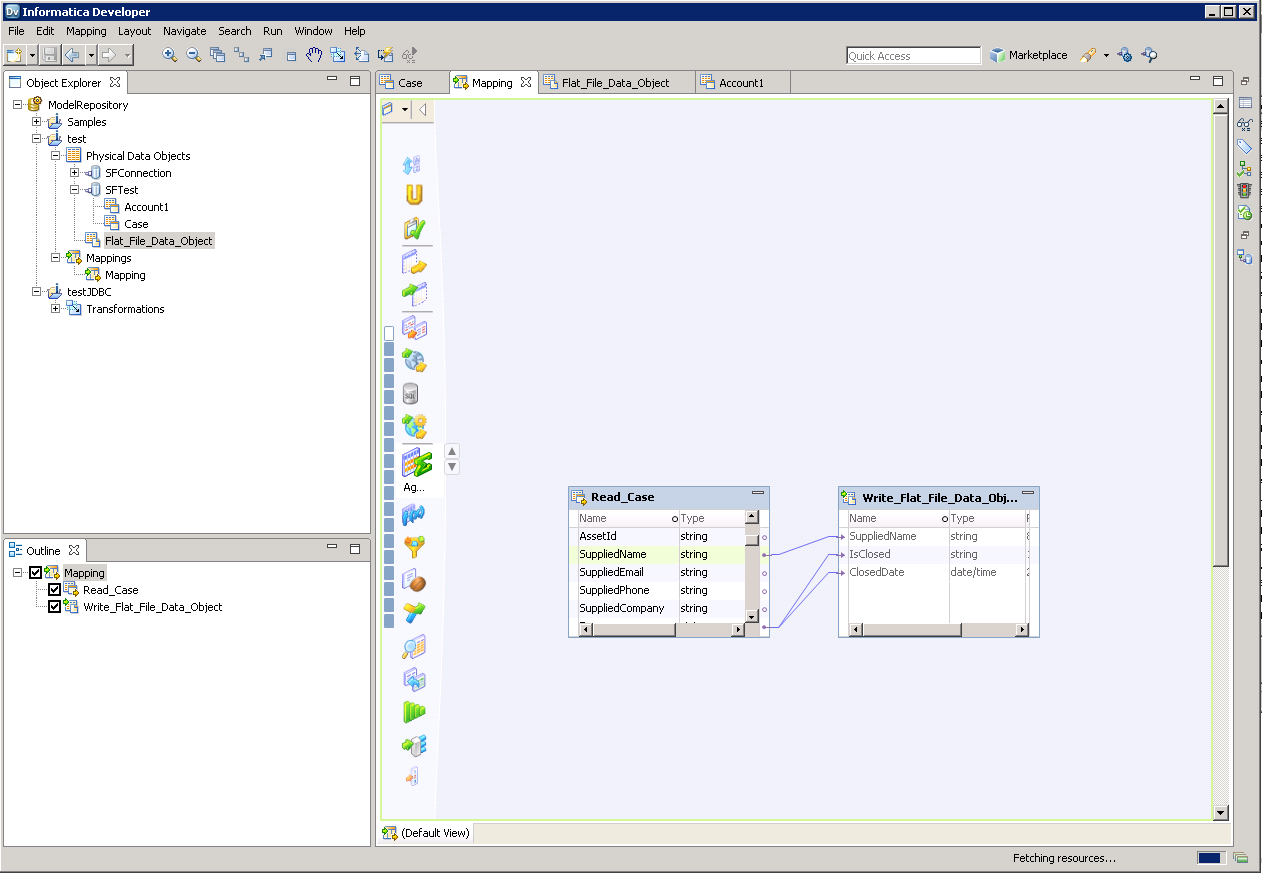
以下のステップに従って、Spark カラムをフラットファイルにマッピングします。
- 「Object Explorer」でプロジェクトを右クリックし、「New」->「Data Object」をクリックします。
- 「Flat File Data Object」->「Create as Empty」->「Fixed Width」と選択します。
- Spark オブジェクトのプロパティで目的の行を選択して右クリックし、コピーします。コピーした行をフラットファイルプロパティにペーストします。
- フラットファイルのデータオブジェクトをマッピングにドラッグします。ダイアログが表示されたら「Write」オプションを選択します。
- クリックおよびドラッグしてカラムを接続します。
Spark のデータを転送するには、ワークスペース内で右クリックして「Run Mapping」をクリックします。
おわりに
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。