各製品の資料を入手。
詳細はこちら →



Klipfolio でのKafka に接続されたビジュアライゼーションを作成
CData Connect Server を使用してKlipfolio からKafka に接続し、リアルタイムKafka のデータを使用してカスタムビジュアライゼーションを作成します。
最終更新日:2022-03-05
こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Klipfolio は、チームやクライアント向けのリアルタイムダッシュボードを構築するための、オンラインダッシュボードプラットフォームです。CData Connect Server と組み合わせると、ビジュアライゼーションやレポートなどのためにKafka のデータにアクセスできます。この記事では、Connect Server でKafka の仮想データベースを作成し、Klipfolio でKafka のデータからビジュアライゼーションを構築する方法を説明します。
CData Connect Server は、Kafka に純粋なMySQL インターフェースを提供し、ネイティブにサポートされているデータベースにデータを複製することなくKlipfolio のリアルタイムKafka のデータからレポートを作成できるようにします。ビジュアライゼーションを作成すると、Klipfolio はデータを収集するためのSQL クエリを生成します。CData Connect Server は、最適化されたデータ処理を使用してサポートされているすべてのSQL 操作(フィルタ、JOIN など)をKafka に直接プッシュし、サーバーサイドの処理を利用して、要求されたKafka のデータを素早く返します。
Kafka のデータの仮想MySQL データベースを作成
CData Connect Server は、簡単なポイントアンドクリックインターフェースを使用してAPI を生成します。
- Connect Server にログインし、「Databases」をクリックします。

- 「Available Data Sources」から「Kafka」を選択します。
-
必要な認証プロパティを入力し、Kafka に接続します。
Apache Kafka 接続プロパティの取得・設定方法
.NET ベースのエディションは、Confluent.Kafka およびlibrdkafka ライブラリに依存して機能します。 これらのアセンブリはインストーラーにバンドルされ、自動的に本製品と一緒にインストールされます。 別のインストール方法を利用する場合は、NuGet から依存関係のあるConfluent.Kafka 2.6.0 をインストールしてください。
Apache Kafka サーバーのアドレスを指定するには、BootstrapServers パラメータを使用します。
デフォルトでは、本製品はデータソースとPLAINTEXT で通信し、これはすべてのデータが暗号化なしで送信されることを意味します。 通信を暗号化するには:
- UseSSL をtrue に設定し、本製品がSSL 暗号化を使用するように構成します。
- SSLServerCert およびSSLServerCertType を設定して、サーバー証明書をロードします。
Apache Kafka への認証
Apache Kafka データソースは、次の認証メソッドをサポートしています:- Anonymous
- Plain
- SCRAM ログインモジュール
- SSL クライアント証明書
- Kerberos
Anonymous
Apache Kafka の特定のオンプレミスデプロイメントでは、認証接続プロパティを設定することなくApache Kafka に接続できます。 こうした接続はanonymous(匿名)と呼ばれます。
匿名認証を行うには、このプロパティを設定します。
- AuthScheme:None。
その他の認証方法については、ヘルプドキュメントを参照してください。
- 「 Test Database 」をクリックします。
- 「Permission」->「 Add」とクリックし、適切な権限を持つ新しいユーザー(または既存のユーザー)を追加します。
コネクションが作成されたら、Klipfolio からKafka に接続することができます。
Klipfolio からKafka に接続
以下のステップでは、Klipfolio からCData Connect Server に接続して新しいKafka のデータソースを作成する方法の概要を説明します。
- Klipfolio を開きます。
- 「Data Sources」で「」をクリックして新しいデータソースを追加します。
- MSSQL をService として検索して選択します。
- 「Create a custom MSSQL data source」をクリックします。
- MySQL 接続プロパティを設定してデータソースを構成します。
- MSSQL 接続プロパティを設定してデータソースを構成します。
- Host:接続するCData Connect Serverインスタンス、例:CONNECT_SERVER_URL
- Port:1433
- Database: データベース (例 ApacheKafka1)
- Driver:MS SQL
- Username:Connect Server ユーザー
- Password:上記のユーザーのパスワード
- SQL Query:データを取得するためのクエリ(例:SELECT * FROM SampleTable_1)
- 「Include column headers」チェックボックスをオンにします。
- サーバー側でSSL/TLS を有効にしている場合は、「Use SSL/TLS」チェックボックスをオンにします。
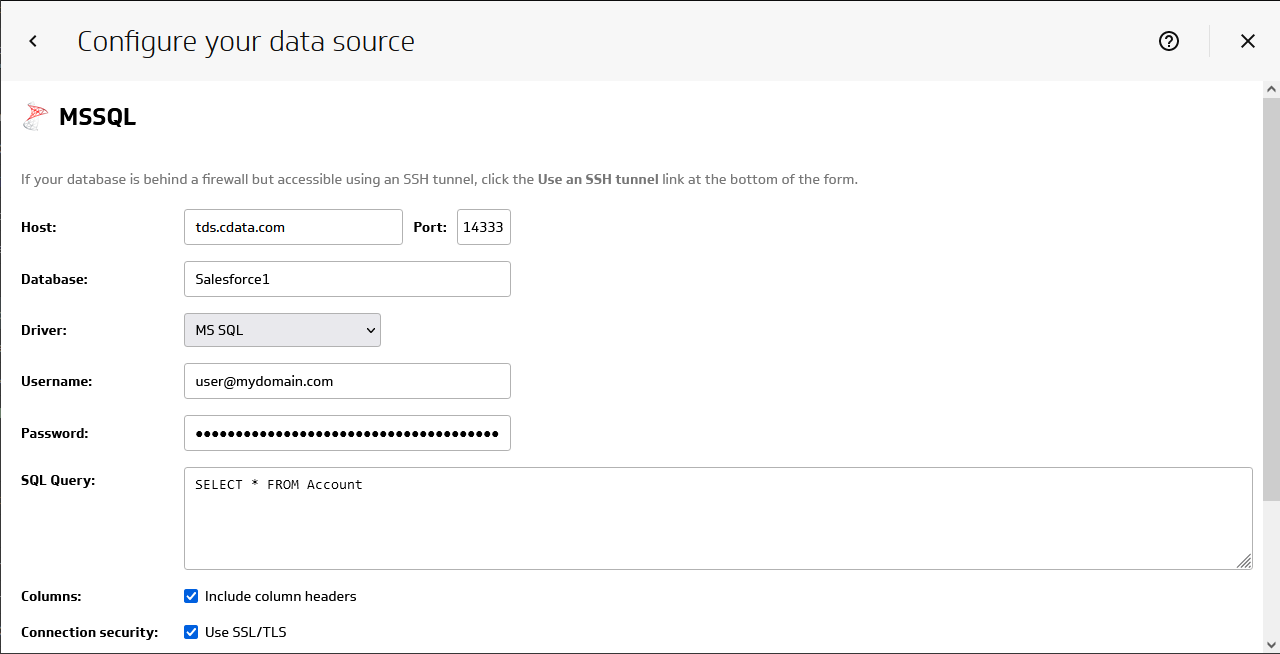
- データモデルを構築する前に「Get data」をクリックしてKafka のデータをプレビューします。
データモデルを構築
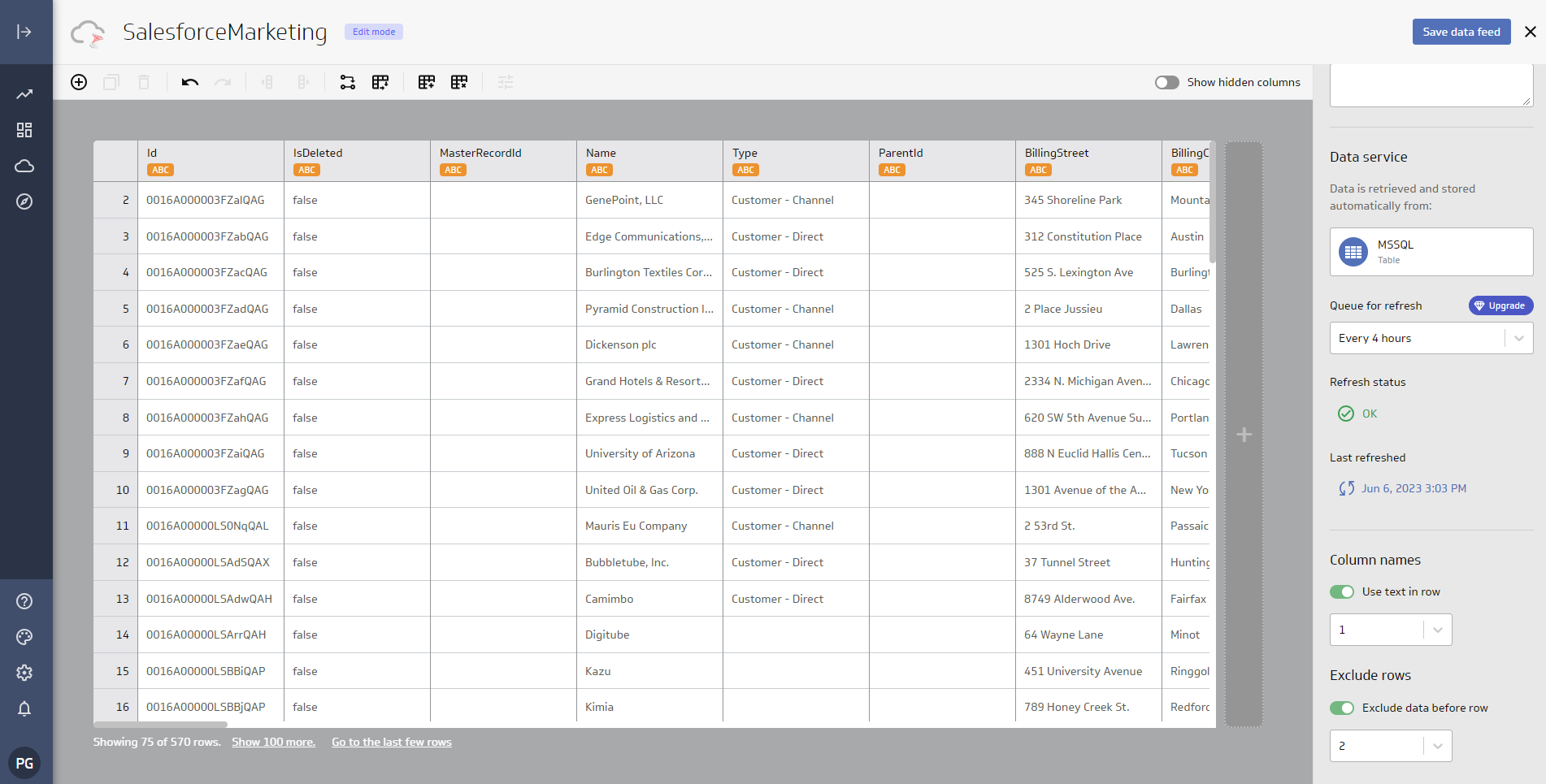
データを取得したら、「Model your data」チェックボックスを選択して「Continue」をクリックします。新しいウィンドウでデータモデルを構築します。
- 使用するすべてのカラムがモデルに含まれていることを確認します。
- モデルに名前を付けます。
- (オプション)Description を設定します。
- 「Header in row」を1に設定します。
- 「Exclude data before row」のトグルをクリックして値を2 に設定します。
- 「Save and Exit」をクリックします。
Metric を作成する
データがモデル化されたことで、ダッシュボードやレポートなどのKlipfolio プラットフォームで使用されるデータのMetric(またはビジュアライゼーション)を作成することができるようになりました。
- 「Create metrics」をクリックします。
- データソースを選択します。
- Metric の値とデフォルトの集計を選択します。
- セグメントを選択します。
- 日時を選択します。
- データのシェイプを選択します。
- 表示設定を構成します。
- Save をクリックします。
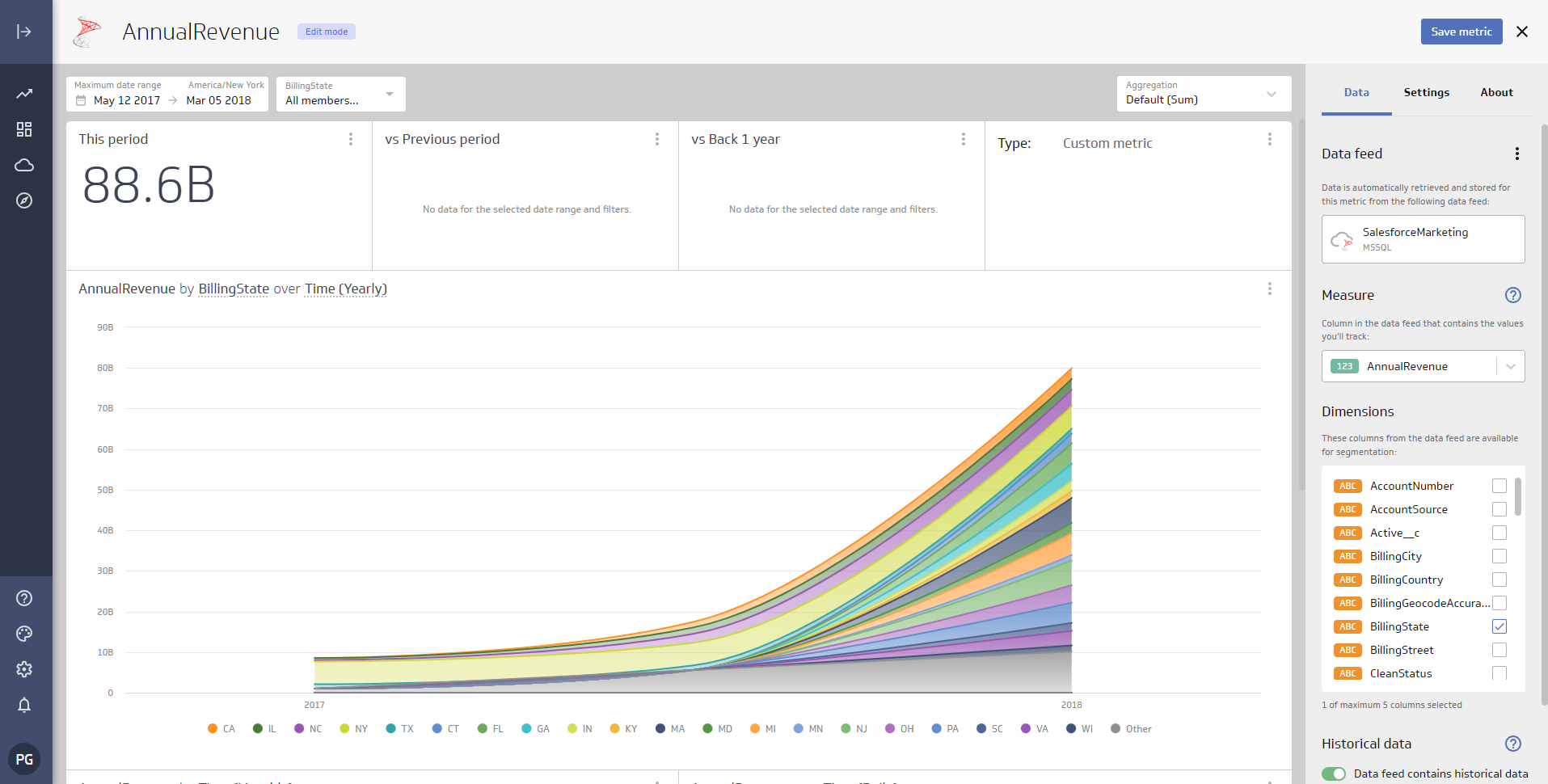
- Metric に移動し、ビジュアライゼーションをさらに設定します。
アプリケーションからKafka のデータへのSQL アクセス
これで、リアルタイムKafka のデータから作成されたMertic ができました。新しいダッシュボードに追加したり共有したりすることができます。これでKafka を複製することなく、より多くのデータソースや新しいビジュアライゼーション、レポートを作成することができます。
アプリケーションから直接250+ SaaS 、ビッグデータ 、NoSQL ソースへのSQL データアクセスを取得するには、CData Connect Server を参照してください。