各製品の資料を入手。
詳細はこちら →



Azure Data Factory を使用してKafka のデータをインポート
CData Connect Server を使用してAzure Data Factory からKafka に接続し、リアルタイムKafka のデータをインポートします。
最終更新日:2022-12-01
こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
Azure Data Factory(ADF)は、フルマネージドのサーバーレスデータ統合サービスです。 CData Connect Server と組み合わせると、ADF はデータフローでKafka のデータにクラウドベースで即座にアクセスできます。 この記事では、Connect Server を使用してKafka に接続し、ADF でKafka のデータにアクセスする方法を紹介します。
CData Connect Server は、Kafka にクラウドベースインターフェースを提供し、ネイティブにサポートされているデータベースにデータを複製することなく、Azure Data Factory でのリアルタイムKafka のデータへのアクセスを実現します。 CData Connect Server は、最適化されたデータ処理により、サポートされているすべてのSQL 操作(フィルタ、JOIN など)をKafka に直接プッシュし、サーバー側の処理を利用して要求されたKafka のデータを高速で返します。
ホスティングについて
ADF からCData Connect Server に接続するには、利用するConnect Server インスタンスをネットワーク経由での接続が可能なサーバーにホスティングして、URL での接続を設定する必要があります。CData Connect がローカルでホスティングされており、localhost アドレス(localhost:8080 など)またはローカルネットワークのIP アドレス(192.168.1.x など)からしか接続できない場合、ADF はCData Connect Server に接続することができません。
クラウドホスティングでの利用をご希望の方は、AWS Marketplace やGCP Marketplace で設定済みのインスタンスを提供しています。
Kafka のデータの仮想データベースを作成する
CData Connect Server は、シンプルなポイントアンドクリックインターフェースを使用してデータソースに接続し、データを取得します。まずは、右側のサイドバーのリンクからConnect Server をインストールしてください。
- Connect Server にログインし、「CONNECTIONS」をクリックします。

- 一覧から「Kafka」を選択します。
-
Kafka に接続するために必要な認証プロパティを入力します。
Apache Kafka 接続プロパティの取得・設定方法
.NET ベースのエディションは、Confluent.Kafka およびlibrdkafka ライブラリに依存して機能します。 これらのアセンブリはインストーラーにバンドルされ、自動的に本製品と一緒にインストールされます。 別のインストール方法を利用する場合は、NuGet から依存関係のあるConfluent.Kafka 2.6.0 をインストールしてください。
Apache Kafka サーバーのアドレスを指定するには、BootstrapServers パラメータを使用します。
デフォルトでは、本製品はデータソースとPLAINTEXT で通信し、これはすべてのデータが暗号化なしで送信されることを意味します。 通信を暗号化するには:
- UseSSL をtrue に設定し、本製品がSSL 暗号化を使用するように構成します。
- SSLServerCert およびSSLServerCertType を設定して、サーバー証明書をロードします。
Apache Kafka への認証
Apache Kafka データソースは、次の認証メソッドをサポートしています:- Anonymous
- Plain
- SCRAM ログインモジュール
- SSL クライアント証明書
- Kerberos
Anonymous
Apache Kafka の特定のオンプレミスデプロイメントでは、認証接続プロパティを設定することなくApache Kafka に接続できます。 こうした接続はanonymous(匿名)と呼ばれます。
匿名認証を行うには、このプロパティを設定します。
- AuthScheme:None。
その他の認証方法については、ヘルプドキュメントを参照してください。
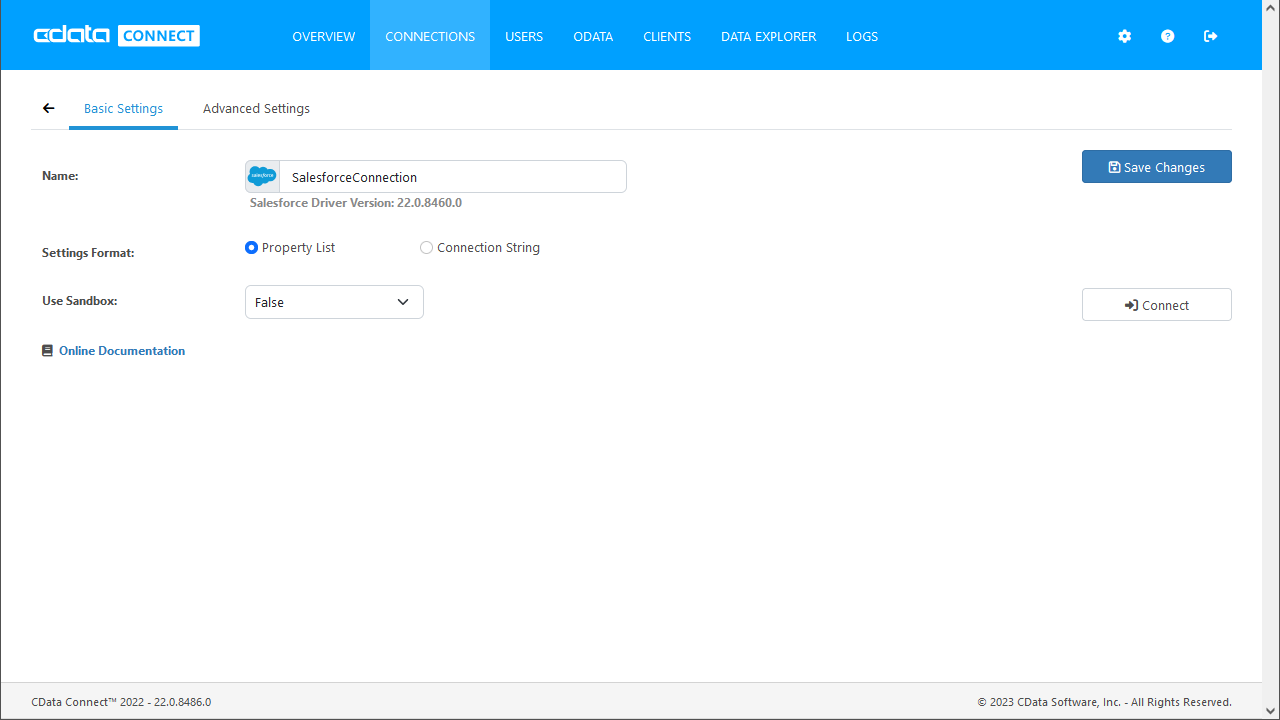
- 「 Test Connection」をクリックします。
- 「Permission」->「 Add」とクリックし、適切な権限を持つ新しいユーザー(または既存のユーザー) を追加します。
仮想データベースが作成されたら、Azure Data Factoro を含むお好みのクライアントからKafka に接続できるようになります。
Azure Data Factory からリアルタイムKafka のデータにアクセス
Azure Data Factory からCData Connect Server の仮想SQL Server API への接続を確立するには、以下の手順を実行します。
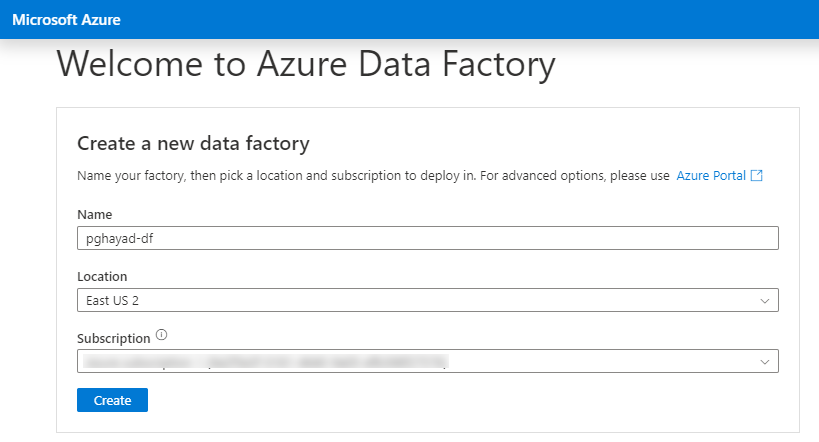
- Azure Data Factory にログインします。
- まだData Factory を作成していない場合は、「New -> Dataset」をクリックします。
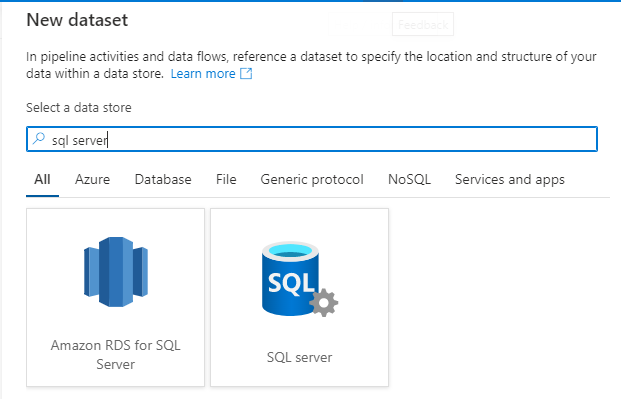
- 検索バーにSQL Server と入力し、表示されたら選択します。次の画面で、サーバーの名前を入力します。 Linked service フィールドで「New」を選択します。
-
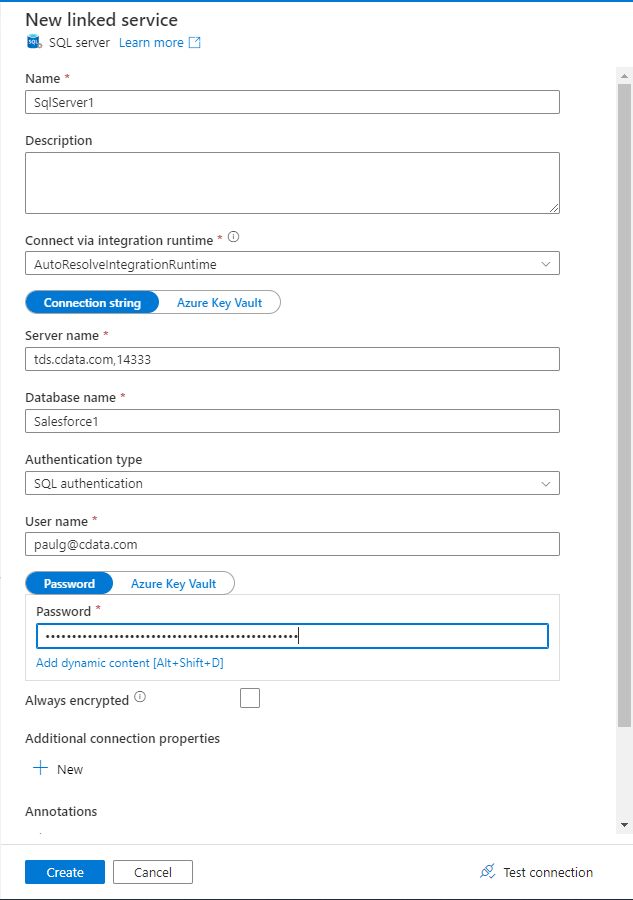
接続設定を入力します。
- Name - 任意の名前を入力。
- Server name - Connect Server のURL とポートをカンマで区切って入力。例:CONNECT_SERVER_URL,1433
- Database name - 接続したいCData Connect Server データソースのConnection Name を入力。例:ApacheKafka1
- User Name - CData Connect Server のユーザー名を入力。ユーザー名はCData Connect Server のインターフェースの右上に表示されています。 例:test@cdata.com
- Password - Password(Azure Key Vault ではありません)を選択してConnect Server のパスワードを入力。
- 「Create」をクリックします。
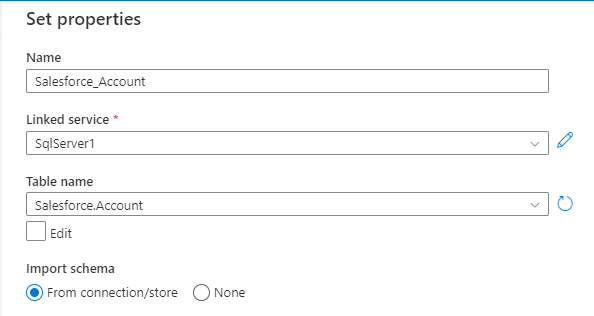
- Set properties で、Name を設定し、続けて先ほど作成したLinked service、利用可能なTable name、Import schema のfrom connection/store を選択します。 「OK」をクリックします。
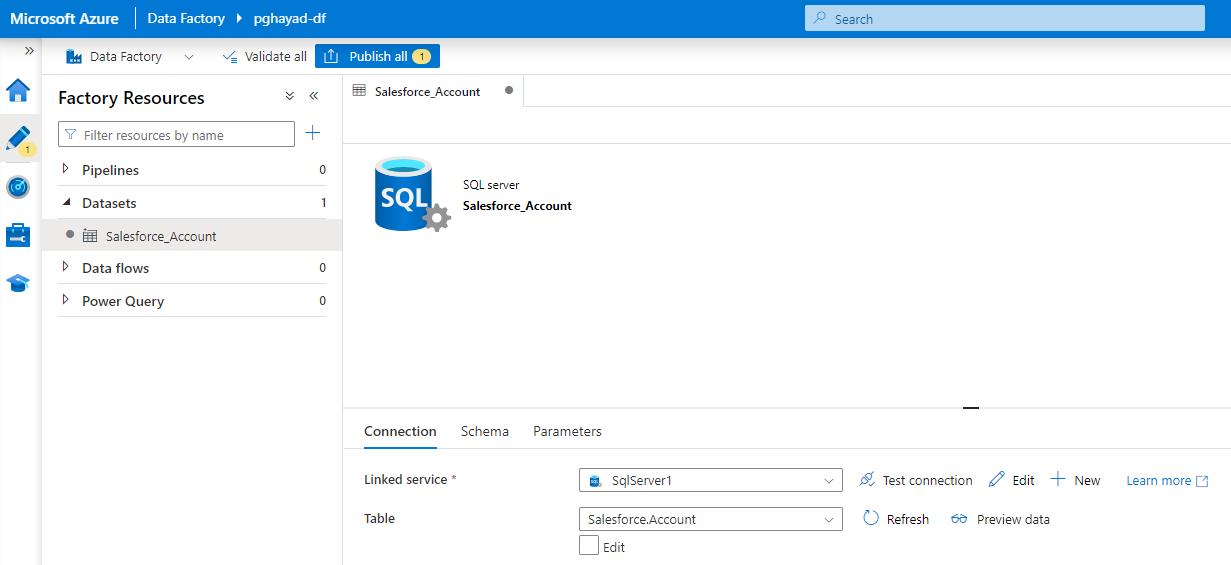
- リンクされたサービスを作成すると、以下の画面が表示されます。
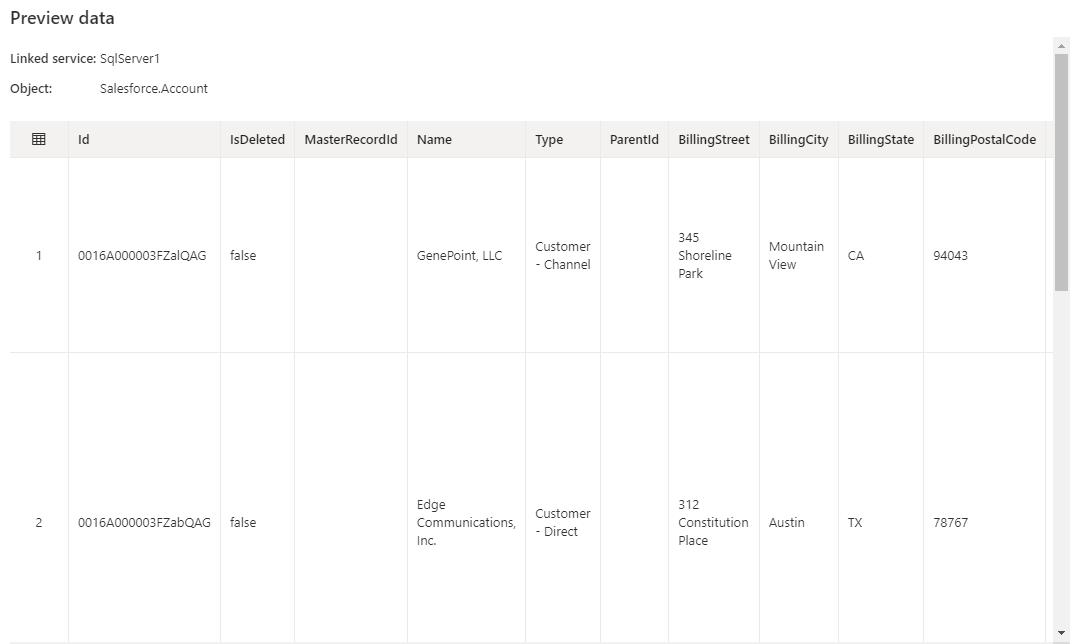
- Preview data をクリックすると、インポートされたKafka テーブルが表示されます。
 Azure Data Factory でデータフローを作成する際、このデータセットを使用できるようになりました。
Azure Data Factory でデータフローを作成する際、このデータセットを使用できるようになりました。
CData Connect Server の入手
CData Connect Server の30日間無償トライアルを利用して、クラウドアプリケーションから直接100を超えるSaaS、ビッグデータ、NoSQL データソースへのSQL アクセスをお試しください!