各製品の資料を入手。
詳細はこちら →



製品をチェック
Kafka のデータをBoomi AtomSphere で連携利用する方法:CData JDBC Driver
CData JDBC ドライバを使って、データ統合サービス(iPaaS)のBoomi で Kafka のデータ をノーコードで連携。
最終更新日:2022-05-18
この記事で実現できるKafka 連携のシナリオ


こんにちは!テクニカルディレクターの桑島です。
Boomi AtomSphere https://boomi.com/は、Boomi 社が提供する、 シングルインスタンス、マルチテナントアーキテクチャを特徴としているデータ統合サービス(iPaaS)です。データ統合機能だけでなく、マスターデータのハブ機能、EDI、APIManagement、WorkFlow といったビジネスユースに必要なデータ連携のすべてを実現する機能をシングルプラットフォームで提供しています。
この記事では、Boomi AtomSphere のオンプレミスAtom deployment 機能を使って、CData JDBC ドライバ経由でKafka のデータにアクセスする方法を紹介します。CData Drivers を使うことで、RDB のようにBoomi 内でKafka のデータを扱うことができるようになります。
Boomi のon-Premise Atom depleyment の作成
on-Premise Atom deployment (右上の青部分)を利用する構成としました。この機能を利用することでOn-Premise 側に配置したCData JDBC ドライバ経由でのSaaS 連携を実現します。
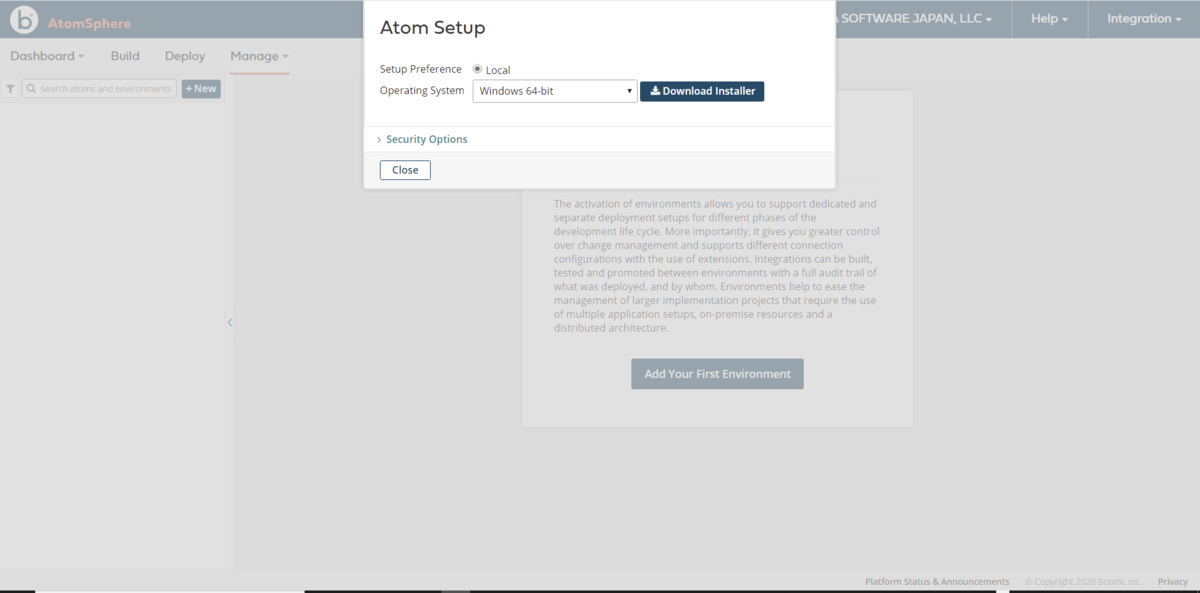
- ブラウザからBoomi Atom のManage > Atom Management のタブを開きます。
- +New > Atom を開きます。
- Atom Setup ダイアログが開くので、ブラウザを開いているマシンのOS(本例ではWindows10Pro 64bit)のSetup ファイルをダウンロードします。
- ダウンロードした「atom_install64.exe」を実行するとインストーラが起動します。
- Setup Wizard を進めます。
- ブラウザからBoomi Atom へのログインする時のUser・Password をセットして、Atom Name はデフォルトのまま、次に進みます。
- on-Premise Atom deployment のインストールディレクトリ(デフォルト)を指定して次に進みます。
- Setup Wizard を終了(Finish)します。
- ブラウザからBoomi Atom のManage > Atom Management のタブを開いて、上記で作成したon-Premise Atom Deployment が起動していることを確認します。なお、Windows マシンの場合、サービスからも起動を確認できます。on-Premise Atom deployment の作成は以上です。
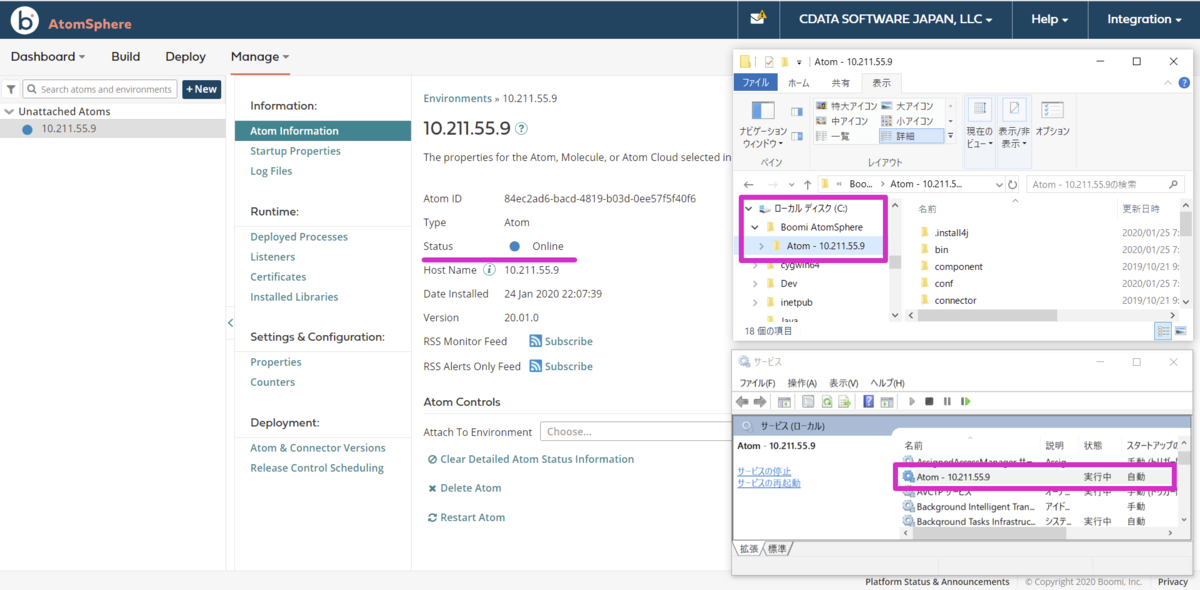
Boomi on-Premise Atom deployment モジュールへのJDBC ドライバの配置
次に別途ダウンロード・インストールしたCData JDBC Driver for ApacheKafka をBoomi on-premise Atom モジュールに配置していきます。
- JDBC Drivers ファイルをCData 製品のインストールフォルダからon-Premise Atom deployment インストールパス配下のパスにコピーします。
- cdata.jdbc.apachekafka.jar
- cdata.jdbc.apachekafka.lic (試用版では.lic ファイルは不要)
- コピー元:C:\Program Files\CData\CData JDBC Driver for ApacheKafka 2019J\lib
- コピー先:C:\Boomi AtomSphere\Atom - 10.211.55.9\lib
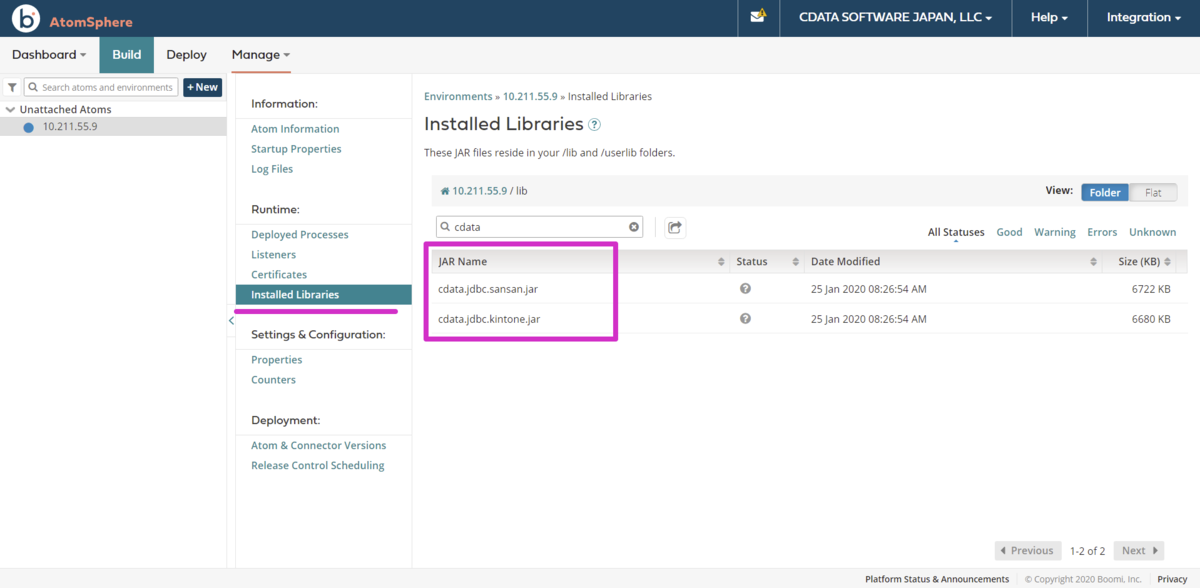
コピーしたらBoomi Atom をブラウザからリスタート(Restart Atom)してください。作成したon-Premise Atom deployment のInstalledLibraries にJDBCの.jar ファイルが表示されれば成功です。
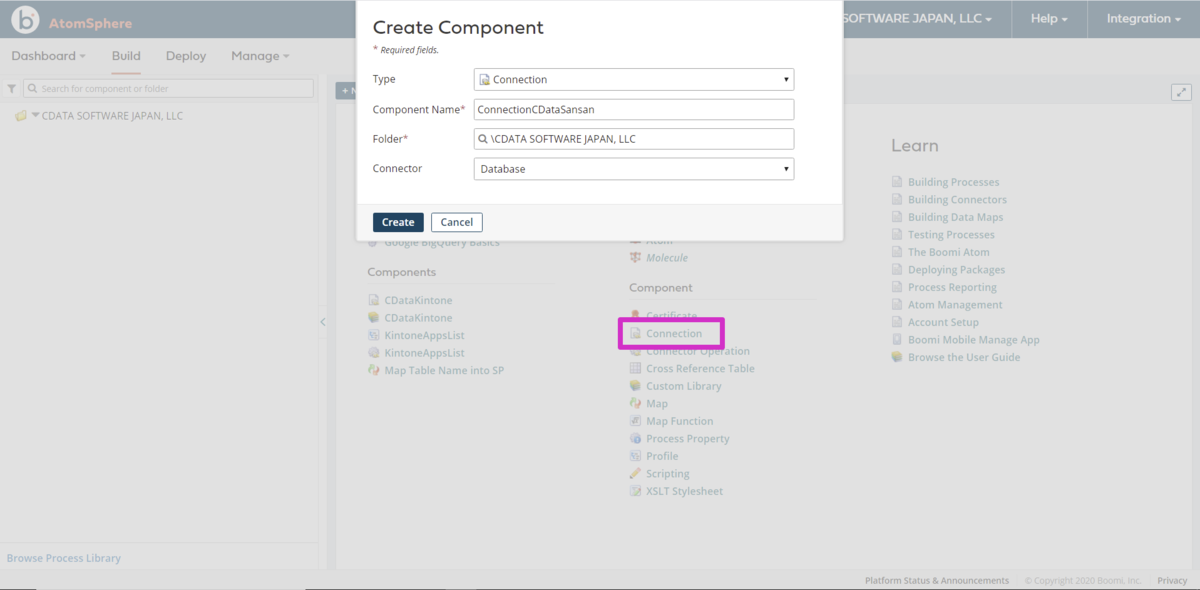
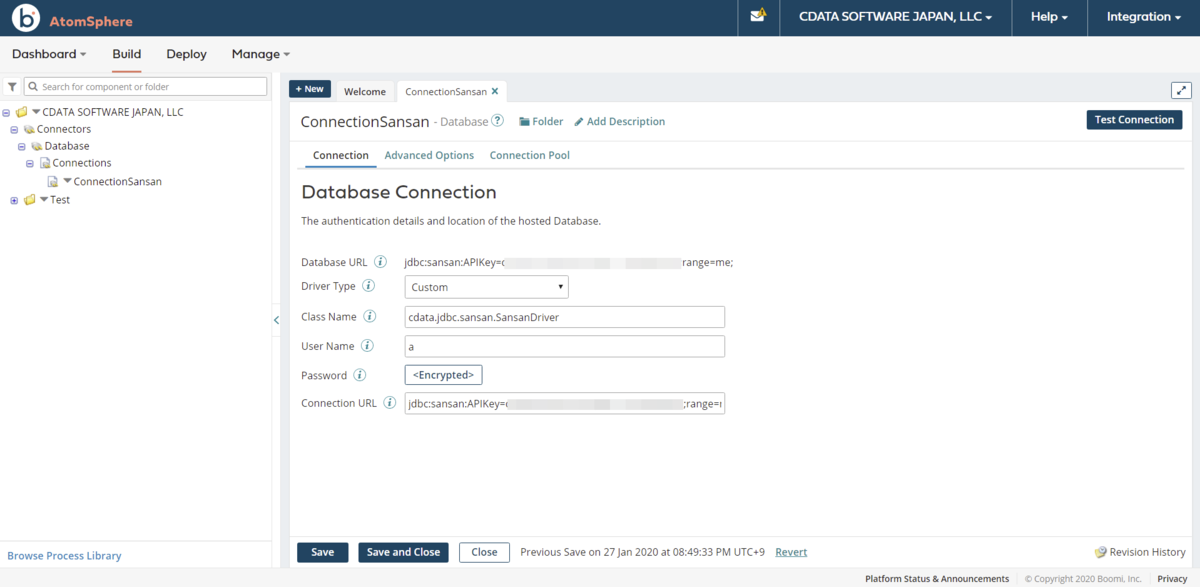
Kafka のConnectionの作成
Boomi Atom からKafka のデータソースに接続するためのConnection を作成します。
- Welcom 画面の「Component > Connetion」を選択するとCreate Component ウィザードが開きます。
- Kafka への接続用のConnection 設定として以下の値をセットします。
- Type: Connection
- Component Name: ConnectionCDataApacheKafka
- Folder: 任意のパス
- Connector: Database
- そしてJDBC Driver の接続設定を行います。
Apache Kafka 接続プロパティの取得・設定方法
.NET ベースのエディションは、Confluent.Kafka およびlibrdkafka ライブラリに依存して機能します。 これらのアセンブリはインストーラーにバンドルされ、自動的に本製品と一緒にインストールされます。 別のインストール方法を利用する場合は、NuGet から依存関係のあるConfluent.Kafka 2.6.0 をインストールしてください。
Apache Kafka サーバーのアドレスを指定するには、BootstrapServers パラメータを使用します。
デフォルトでは、本製品はデータソースとPLAINTEXT で通信し、これはすべてのデータが暗号化なしで送信されることを意味します。 通信を暗号化するには:
- UseSSL をtrue に設定し、本製品がSSL 暗号化を使用するように構成します。
- SSLServerCert およびSSLServerCertType を設定して、サーバー証明書をロードします。
Apache Kafka への認証
Apache Kafka データソースは、次の認証メソッドをサポートしています:- Anonymous
- Plain
- SCRAM ログインモジュール
- SSL クライアント証明書
- Kerberos
Anonymous
Apache Kafka の特定のオンプレミスデプロイメントでは、認証接続プロパティを設定することなくApache Kafka に接続できます。 こうした接続はanonymous(匿名)と呼ばれます。
匿名認証を行うには、このプロパティを設定します。
- AuthScheme:None。
その他の認証方法については、ヘルプドキュメントを参照してください。
- Driver Type: Custom
- Class Name: cdata.jdbc.apachekafka.ApacheKafkaDriver
- User Name: 本来であれば不要ですが、空のままだと後の手順でバリデーションエラーが発生するので適当な値をセットします
- Password: 本来であれば不要ですが、空のままだと後の手順でバリデーションエラーが発生するので適当な値をセットします
- Connection URL: jdbc:apachekafka:User=admin;Password=pass;BootStrapServers=https://localhost:9091;Topic=MyTopic;
- Connection の値を設定したら接続テストを行います。右上のTest Connection ボタンをクリックします。実行するAtom を選択する画面が表示されるので、上記手順で作成したon-Premise Atom deployment を選択します。
- テスト接続が成功することを確認してFinish ボタンでウィザードを閉じます。
- 作成した Kafka のデータ への接続Connection を保存(Save)します。
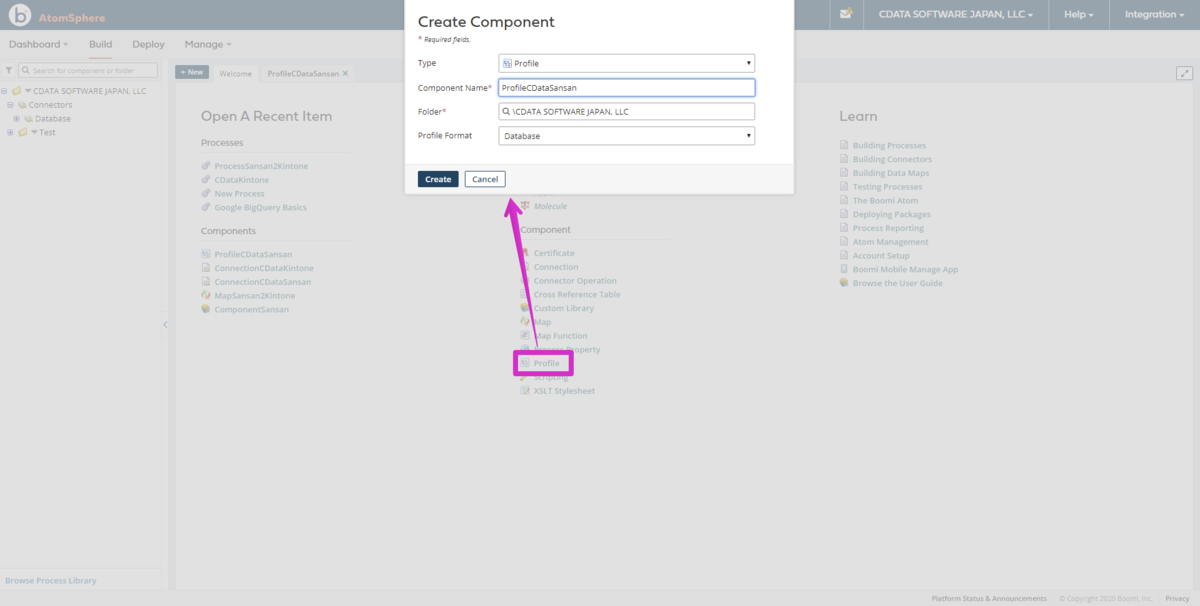
Boomi Atom でのKafka のデータ Profile の作成
次にProfile を設定していきます。ProfileとはSQL(SELECT/INSERT/UPDATE/DELETE)実行時のフィールド定義です。
- Kafka のデータ のテーブルをSELECT するProfile を作成していきます。
-
- Type: Profle
- Component Name: ProfileCDataApacheKafka
- Folder: 任意のパス
- Connector: Database
- 二つのパラメータに、Display Name: デフォルト, Type: Select と値をセットしたら右上のImportボタンをクリックします。
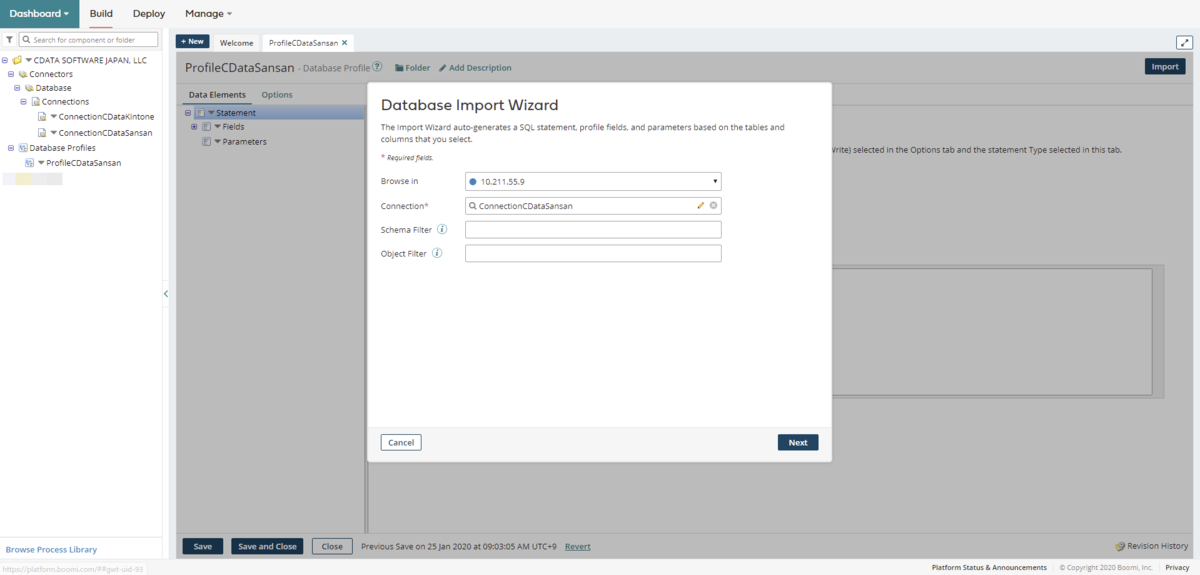
- Database Import Wizardが開くので、以下のパラメータをセットして次に進みます。
- Browse in: 上記手順で作成したon-Premise Atom deployment
- Connection: 上記手順で作成した接続Connection
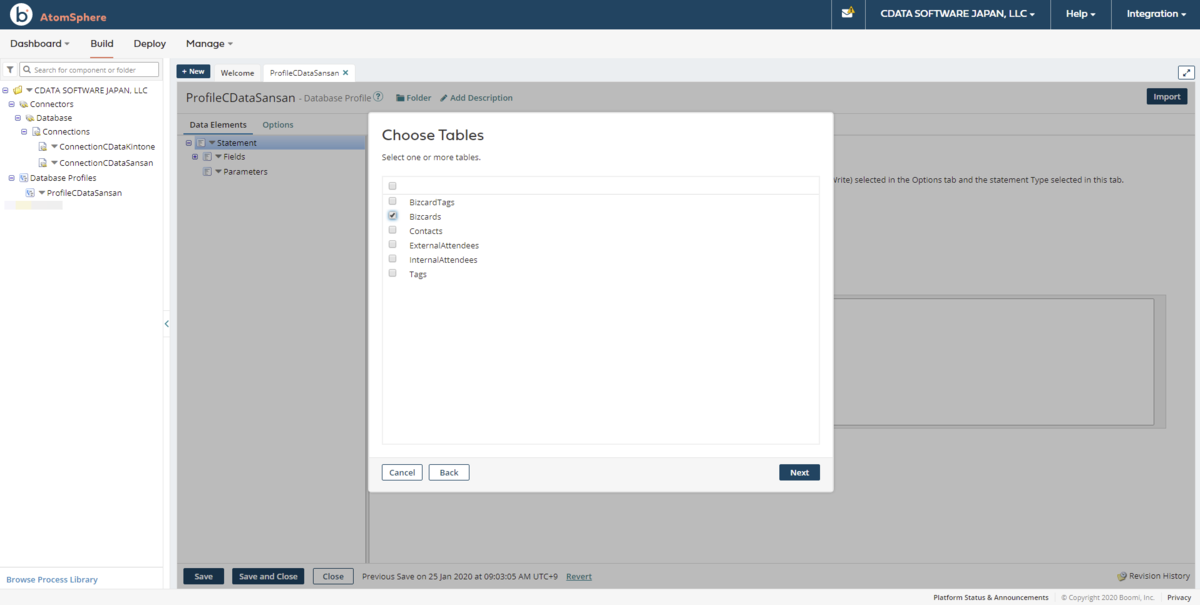
- Kafka のデータ 内のオブジェクトがテーブル一覧として表示されます。取得するテーブルにチェックをオンにして次に進みます。
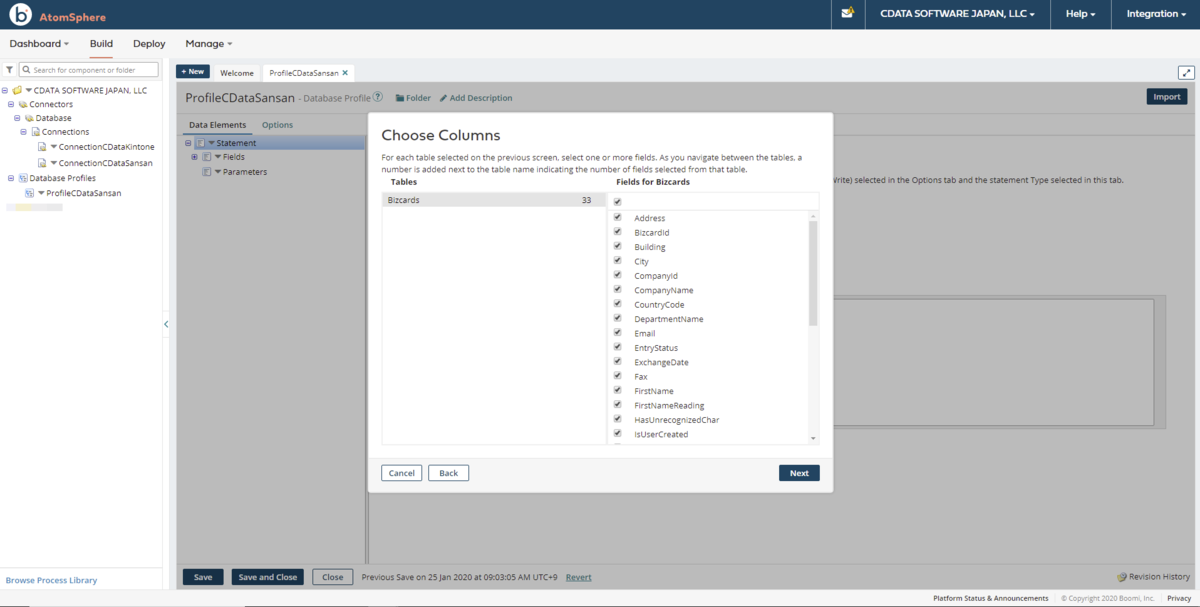
- テーブル内のカラム一覧が表示されます。使用する項目のチェックをオンにして次に進みます。
- Import ウィザードが完了します。
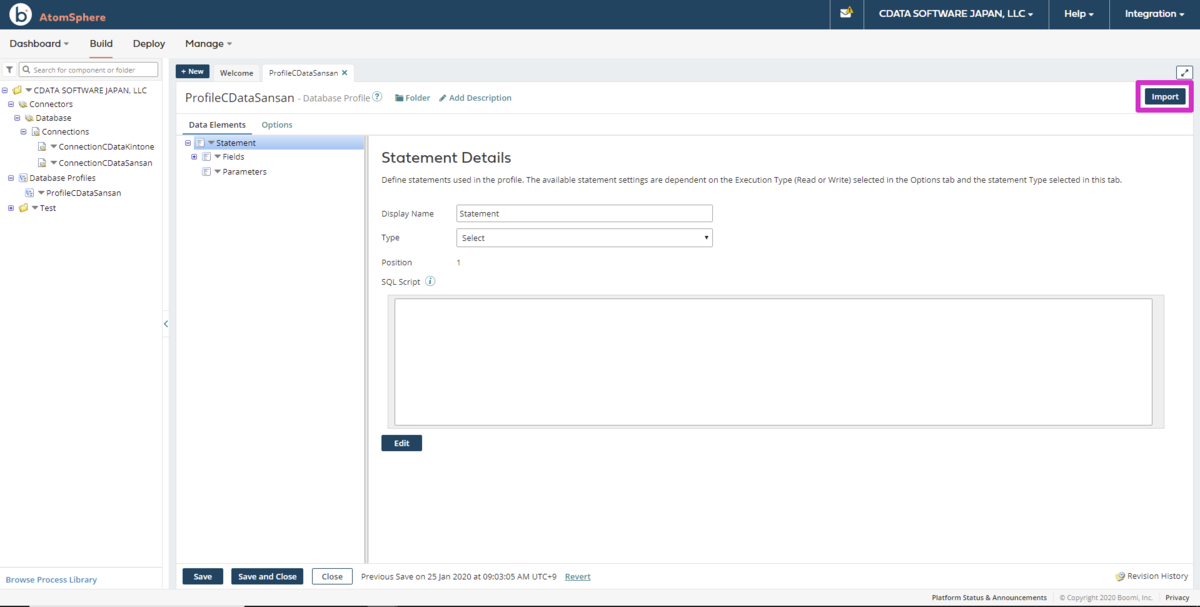
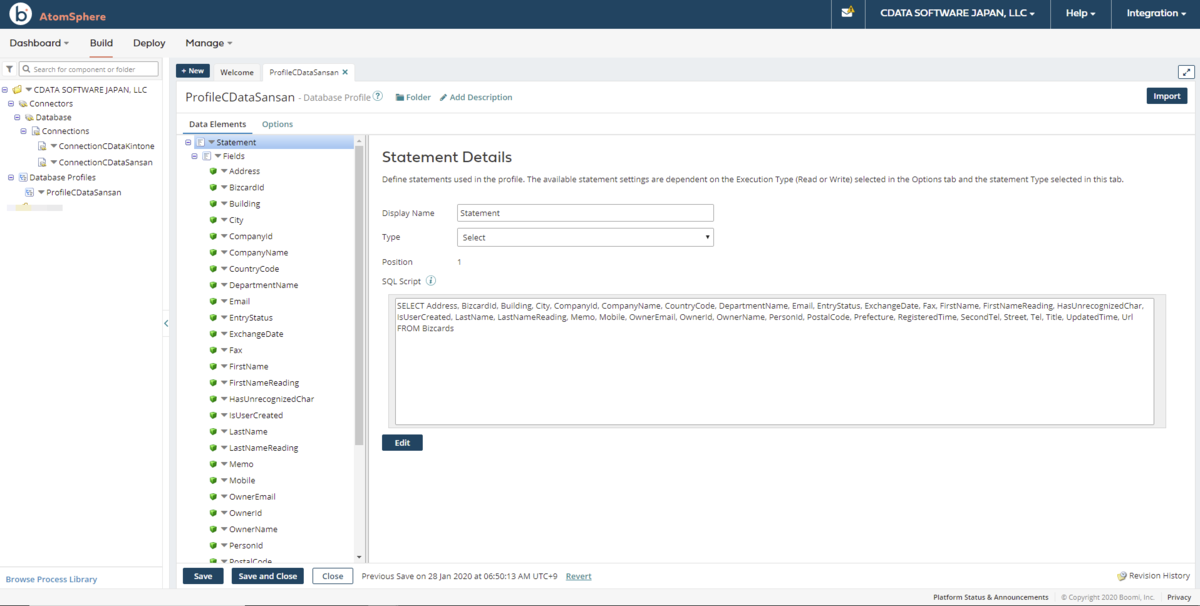
- DataElements のField アイコンをクリックすると選択テーブル内のカラムが定義されていることを確認できます。また、SQL Script には取得時のSQL(SELECT)が表示されています。作成したProfile を保存します。
- これでKafka のデータ がBoom Atom で利用できるProfile として登録されました。
Boomi AtomSphere でのKafka のデータ の利用
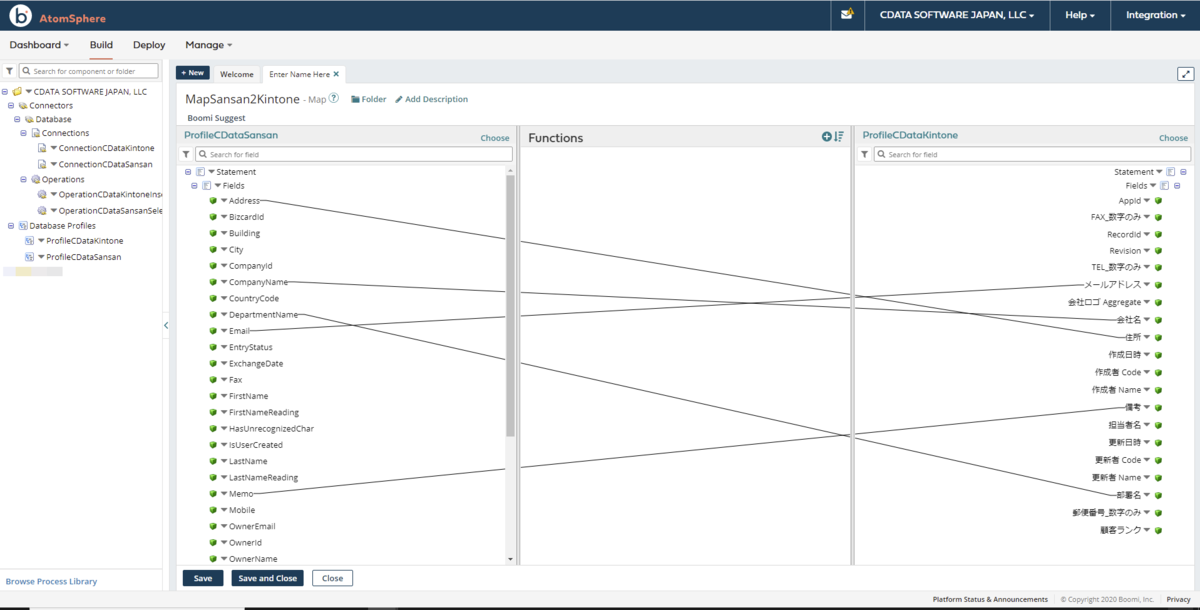
あとは、設定されたProfile はRDB と同じようにBoomi Atom 内で利用することができます。カラムにマッピングを行うこともできます。
このようにCData JDBC ドライバをアップロードすることで、簡単にBoomi AtomSphere でKafka のデータ データをノーコードで連携し、使うことが可能です。
是非、CData JDBC Driver for ApacheKafka 30日の無償評価版 をダウンロードして、お試しください。