各製品の資料を入手。
詳細はこちら →



製品をチェック
Alteryx Designer でKafka のデータを準備、ブレンディング、分析する
リアルタイムKafka のデータにアクセスしてセルフサービスデータ分析を行うワークフローを構築します。
最終更新日:2022-12-15
この記事で実現できるKafka 連携のシナリオ


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData ODBC Driver for ApacheKafka はODBC 標準のKafka からのリアルタイムデータへのアクセスを可能にし、使い慣れたSQL クエリを用いて、さまざまなBI、レポート、ETL ツールでKafka のデータを直接扱うことができます。この記事では、Alteryx Designer でODBC 接続を使ってKafka のデータに接続し、セルフサービスBI、データプレパレーション、データブレンディングから高度な分析までを実行する方法を紹介します。
CData ODBC ドライバーには最適化されたデータ処理が組み込まれており、Alteryx Designer でリアルタイムKafka のデータを扱う上で高いパフォーマンスを提供します。Alteryx Designer からKafka にSQL クエリを発行すると、CData ドライバーはフィルタや集計などのKafka 側でサポートしているSQL 操作をKafka に直接渡し、サポートされていない操作(主にSQL 関数とJOIN 操作)は組み込みSQL エンジンを利用してクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、ネイティブのAlteryx データフィールド型を使ってKafka のデータを可視化および分析できます。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持った製品です。
- Kafka をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレデータソースに対応
- 多様なアプリケーション、ツールにKafka のデータを連携
- ノーコードでの手軽な接続設定
- 標準SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてKafka の接続を設定、2.Alteryx Designer 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとKafka への接続設定
まずは、本記事右側のサイドバーからApacheKafka ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
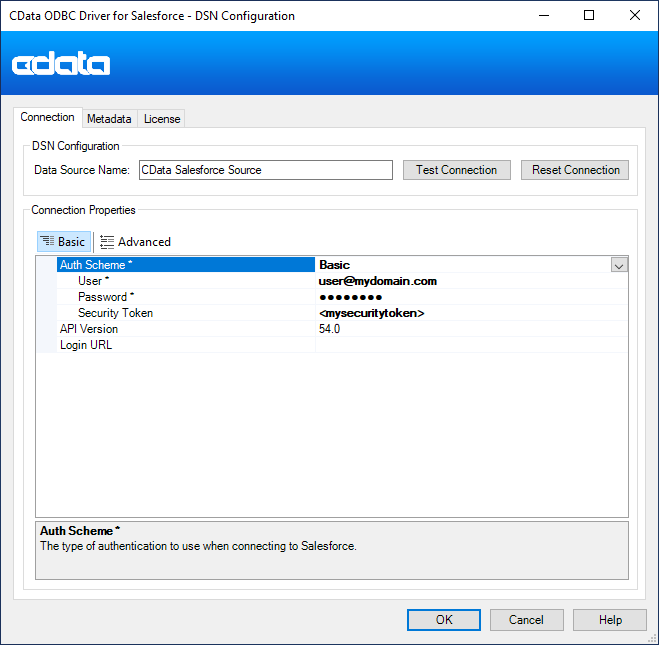
- 必要な接続プロパティの値がまだ未設定の場合は、データソース名(DSN)を設定します。組み込みのMicrosoft ODBC データソースアドミニストレーターを使ってDSN を構成できます。これは、ドライバーのインストールの最後のステップでも可能です。Microsoft ODBC データソースアドミニストレーターを使ってDSN を作成および設定する方法については、ヘルプドキュメントの「はじめに」を参照してください。
Apache Kafka 接続プロパティの取得・設定方法
.NET ベースのエディションは、Confluent.Kafka およびlibrdkafka ライブラリに依存して機能します。 これらのアセンブリはインストーラーにバンドルされ、自動的に本製品と一緒にインストールされます。 別のインストール方法を利用する場合は、NuGet から依存関係のあるConfluent.Kafka 2.6.0 をインストールしてください。
Apache Kafka サーバーのアドレスを指定するには、BootstrapServers パラメータを使用します。
デフォルトでは、本製品はデータソースとPLAINTEXT で通信し、これはすべてのデータが暗号化なしで送信されることを意味します。 通信を暗号化するには:
- UseSSL をtrue に設定し、本製品がSSL 暗号化を使用するように構成します。
- SSLServerCert およびSSLServerCertType を設定して、サーバー証明書をロードします。
Apache Kafka への認証
Apache Kafka データソースは、次の認証メソッドをサポートしています:- Anonymous
- Plain
- SCRAM ログインモジュール
- SSL クライアント証明書
- Kerberos
Anonymous
Apache Kafka の特定のオンプレミスデプロイメントでは、認証接続プロパティを設定することなくApache Kafka に接続できます。 こうした接続はanonymous(匿名)と呼ばれます。
匿名認証を行うには、このプロパティを設定します。
- AuthScheme:None。
その他の認証方法については、ヘルプドキュメントを参照してください。
DSN を構成する際、Max Rows 接続プロパティも設定することができます。これを設定すると返される行数が制限されるため、レポートやビジュアライゼーションを作成する際のパフォーマンスが向上します。
- Alteryx Designer を開いて新しいワークフローを作成します。
- 新規のデータ入力ツールをワークフローにドラッグ&ドロップします。
- 「ファイルまたはデータベースを接続」の下のドロップダウンをクリックし、続けて「データソース」タブを選択します。
- ページの最後に移動し、「Generic connection」の下の「ODBC」をクリックします。
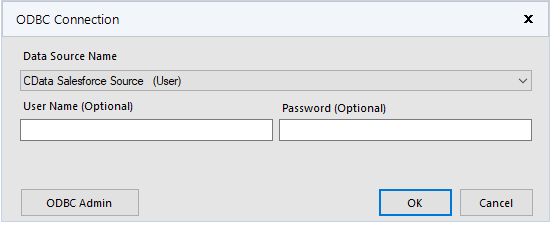
- Alteryx で使用するために設定したDSN (CData Kafka Source)を選択します。
- ウィザードが開いたら、クエリを実行するテーブルを「クエリビルダ」ボックスにドラッグ&ドロップします。クエリに含めるチェックボックスをオンにしてフィールドを選択します。可能な場合、フィルタと集計によって生成されたクエリはKafka に渡され、サポートされていない操作(SQL 関数とJOIN 操作を含む)は、コネクタに組み込まれたCData SQL エンジンによってクライアント側で管理されます。
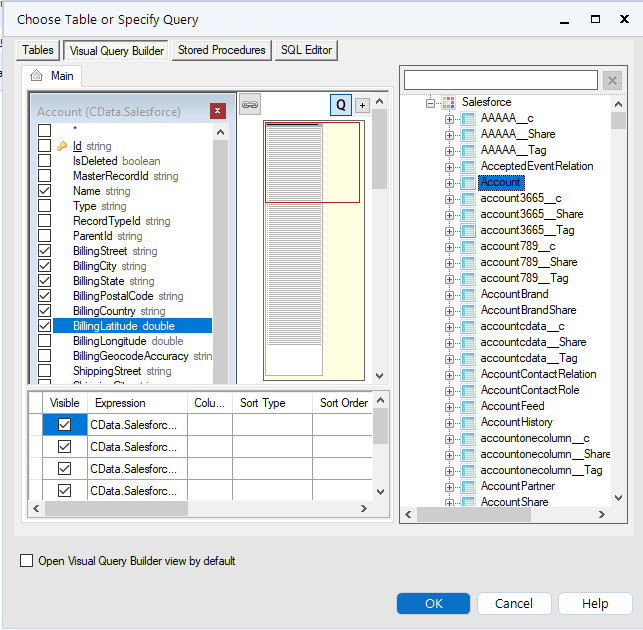
データセットをさらにカスタマイズする場合は、SQL エディタを開いてクエリを手動で変更し、句や集計などの操作を追加して、必要なKafka のデータを正確に取得できるようにします。
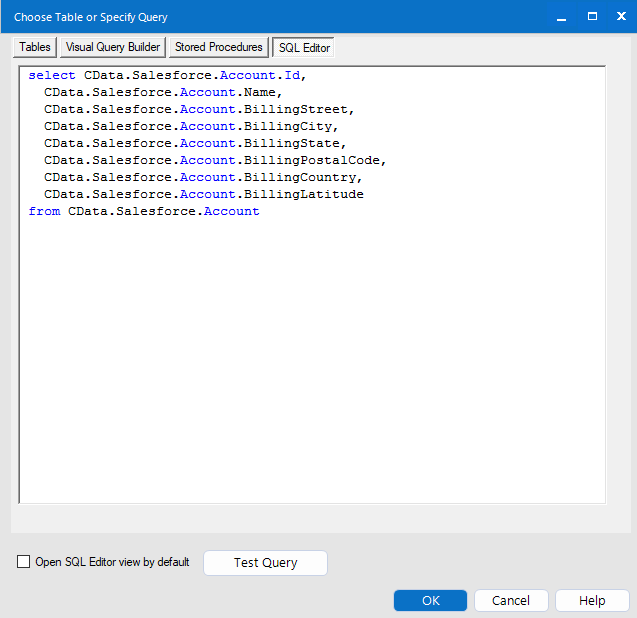
クエリを定義したら、Alteryx Designer でKafka のデータを操作できるようになります。
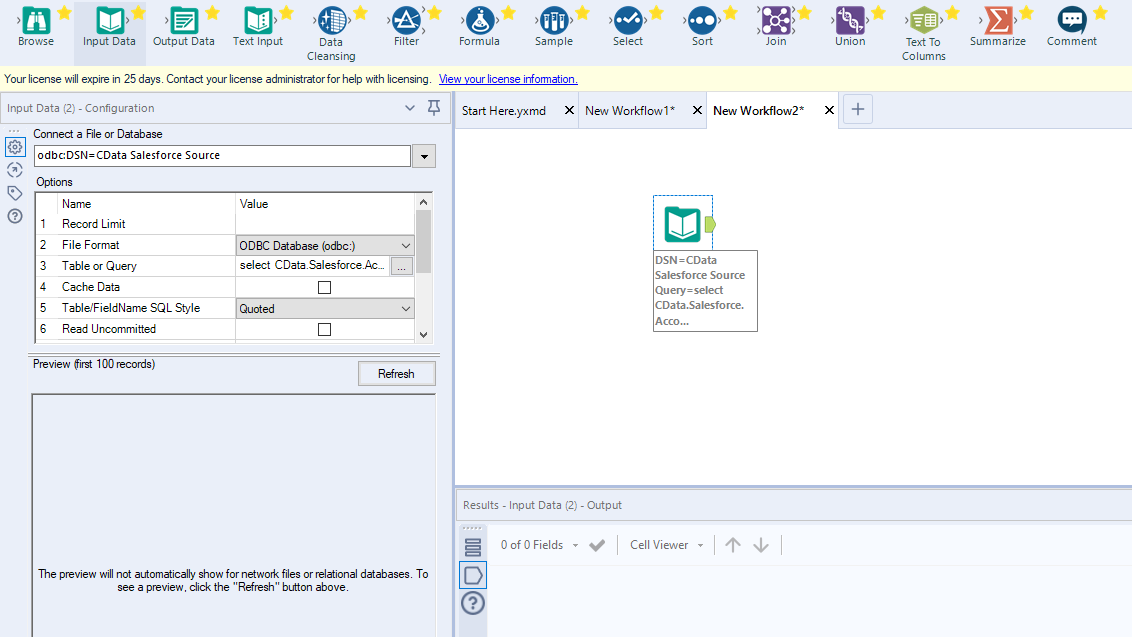
Kafka のデータに対してセルフサービス分析を実行
これで、Kafka のデータを準備、ブレンディング、分析するためのワークフローを作成する準備ができました。CData ODBC ドライバは動的なメタデータ検出を実行し、Alteryx データフィールドタイプを使用してデータを表示し、Designer ツールを活用して必要に応じてデータを操作し、意味のあるデータセットを構築できるようにします。以下の例では、データをクレンジングして参照します。
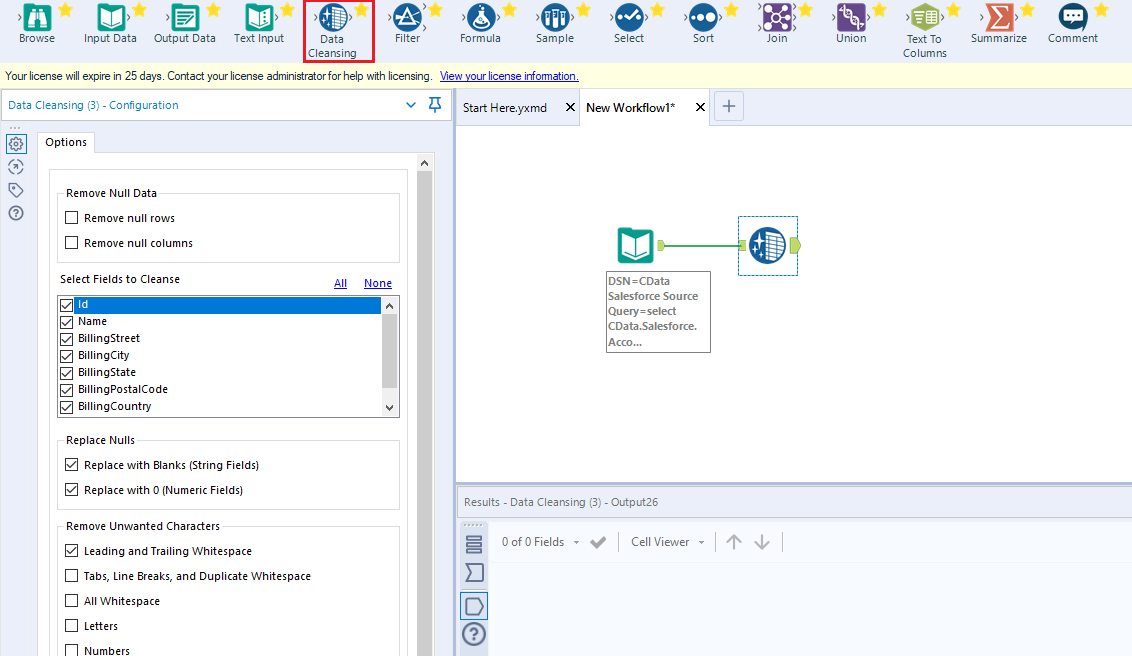
- データクレンジングツールをワークフローに追加し、「Nullの置換」の2つのチェックボックスをオンにして、null テキストフィールドを空白に、null 数値フィールドを0 に置き換えます。「不要な文字の削除」下のチェックボックスをオンにして、先頭と末尾の空白を削除することもできます。
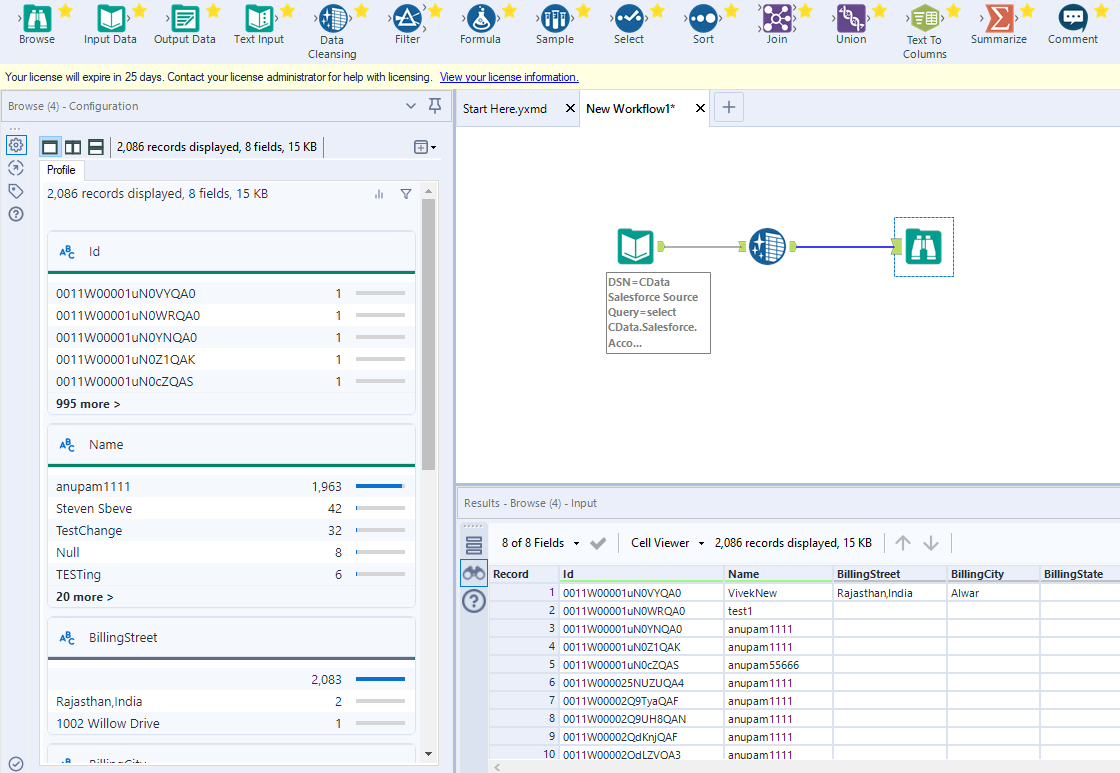
- 閲覧ツールをワークフローに追加します。
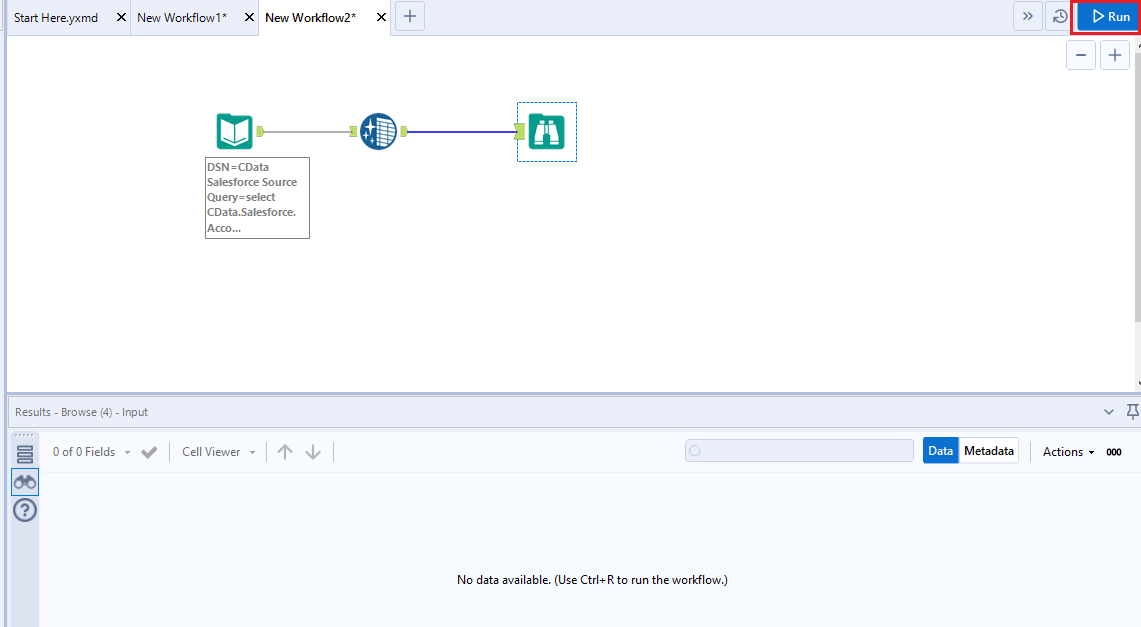
- クリックしてワークフローを実行します(Ctrl + R)。
- 結果ビューでクレンジングされたKafka のデータを確認します。

高いパフォーマンスを発揮する組み込みのデータ処理により、Alteryx でKafka のデータを迅速にクレンジング、変換、分析することができます。