各製品の資料を入手。
詳細はこちら →



製品をチェック
SpagoBI でKafka に連携
SpagoBI Studio でリアルタイムKafka にフィーチャーしたレポートを作成します。ホストのKafka はSpagoBI サーバーを報告します。
最終更新日:2022-06-13
この記事で実現できるKafka 連携のシナリオ


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData JDBC Driver for ApacheKafka はJDBC 標準をサポートするビジネスインテリジェンスおよびデータマイニングツールからリアルタイムKafka に接続することを可能にします。この記事では、Kafka をSpagoBI Studio のレポートに統合し、SpagoBI サーバーでホストする方法を説明します。
SpagoBI サーバーのJDBC ドライバーをデプロイ
以下のステップに従ってSpagoBI サーバーでJDBC data source for ApacheKafka を作成します。
- ドライバーJAR を%CATALINA_BASE%/lib にコピーします。これらのファイルは、インストールディレクトリのlib サブフォルダにあります。
Kafka ドライバーリソースをコンテクストに追加します。以下のリソース定義をserver.xml の[GlobalNamingResources]要素に追加できます。
<Resource name="jdbc/apachekafka" auth="Container" type="javax.sql.DataSource" driverclassname="cdata.jdbc.apachekafka.ApacheKafkaDriver" factory="org.apache.tomcat.jdbc.pool.DataSourceFactory" maxactive="20" maxidle="10" maxwait="-1"/>- 以下のリソースリンクを追加し、Web アプリケーションへのアクセスを許可します。この記事では、SpagoBI のMETA-INF\context.xml に次の行を追加します。
<ResourceLink global="jdbc/apachekafka" name="jdbc/apachekafka" type="javax.sql.DataSource"/> - サーバーを再起動します。
SpagoBI サーバーのリソースにドライバーを追加した後、データソースを追加します。SpagoBIで[Resources]->[Data Source]->[Add]と進み、以下の情報を入力します。
- Label:ドライバーに独特の識別子を入力します。
- Description:ドライバーにディスクリプションを入力します。
- Dialect:デフォルトの方言を選択します。
- Read Only:読み取り専用オプションを選択します。このオプションは、データソースがエンドユーザーによって作成された、データセットを保存するためのデフォルトデータベースであるかどうかを決定します。
- Type:[JDBC]を選択します。
- URL:
- 必要な接続文字列プロパティを使用してJDBC URLを入力します。
Apache Kafka 接続プロパティの取得・設定方法
.NET ベースのエディションは、Confluent.Kafka およびlibrdkafka ライブラリに依存して機能します。 これらのアセンブリはインストーラーにバンドルされ、自動的に本製品と一緒にインストールされます。 別のインストール方法を利用する場合は、NuGet から依存関係のあるConfluent.Kafka 2.6.0 をインストールしてください。
Apache Kafka サーバーのアドレスを指定するには、BootstrapServers パラメータを使用します。
デフォルトでは、本製品はデータソースとPLAINTEXT で通信し、これはすべてのデータが暗号化なしで送信されることを意味します。 通信を暗号化するには:
- UseSSL をtrue に設定し、本製品がSSL 暗号化を使用するように構成します。
- SSLServerCert およびSSLServerCertType を設定して、サーバー証明書をロードします。
Apache Kafka への認証
Apache Kafka データソースは、次の認証メソッドをサポートしています:- Anonymous
- Plain
- SCRAM ログインモジュール
- SSL クライアント証明書
- Kerberos
Anonymous
Apache Kafka の特定のオンプレミスデプロイメントでは、認証接続プロパティを設定することなくApache Kafka に接続できます。 こうした接続はanonymous(匿名)と呼ばれます。
匿名認証を行うには、このプロパティを設定します。
- AuthScheme:None。
その他の認証方法については、ヘルプドキュメントを参照してください。
ビルトイン接続文字列デザイナ
JDBC URL の構成については、Kafka JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.apachekafka.jar接続プロパティを入力し、接続文字列をクリップボードにコピーします。
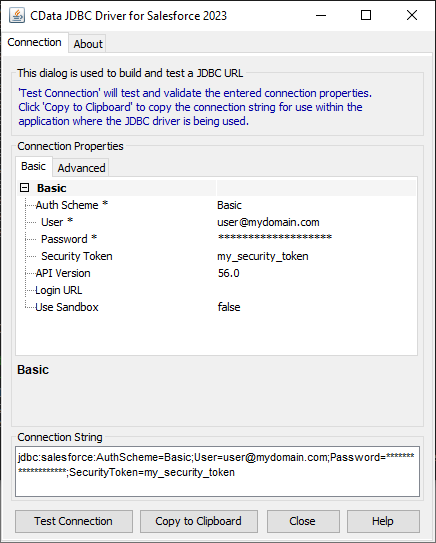
以下は一般的なJDBC URL です。
jdbc:apachekafka:User=admin;Password=pass;BootStrapServers=https://localhost:9091;Topic=MyTopic; - Driver:ドライバーのクラス名にcdata.jdbc.apachekafka.ApacheKafkaDriver を入力します。

SpagoBI Studio でレポートを作成
以下のステップに従い、SpagoBI StudioでKafka に基づいたレポートを作成します。SQL クエリの結果をチャートに挿入するデータセットを作成します。次のセクションでは、このレポートをSpagoBI サーバーでホストします。
初めに、SpagoBI Studio のレポートからKafka に接続してください。
- SpagoBI Studio で、[File]->[New]->[Project]とクリックしていき、[Business Intelligence and Reporting Tools]フォルダで[Report Project]を選択します。
- [File]->[New]->[Report]と進み、[Blank Report]を選択します。
- [Data Explorer]ビューで[Data Sources]を右クリックし、[New Data Source]をクリックします。
- [JDBC Data Source]を選択し、データソース名を入力します。
- [Manage Drivers]をクリックし、[Add]をクリックしてドライバーJAR(cdata.jdbc.apachekafka.jar) を追加します。
- ドライバーJAR は、インストールディレクトリのlib サブフォルダにあります。
- [Driver Class]メニューでドライバークラス(cdata.jdbc.apachekafka.ApacheKafkaDriver)を選択します。
- [Database URL]ボックスに、[JDBC URL]を入力します。以下は一般的な接続文字列です。
jdbc:apachekafka:User=admin;Password=pass;BootStrapServers=https://localhost:9091;Topic=MyTopic;必要な接続プロパティを取得するためのガイドについては、ドライバーヘルプの[Getting Started]チャプターを見てください。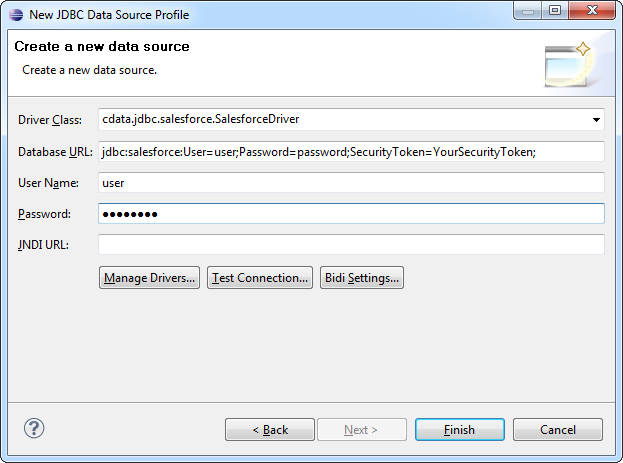
Kafka に接続した後、SQL クエリの結果を含むデータセットを作成します。
- [DataSet]フォルダを右クリックし、[New Data Set]をクリックします。JDBC data source for ApacheKafka を選択し、データセットの名称を入力します。
- SQL クエリを構築します。ここでは、このクエリを使用してダッシュボードにチャートを追加します。例:
SELECT Id, Column1 FROM SampleTable_1 WHERE Column2 = '100'
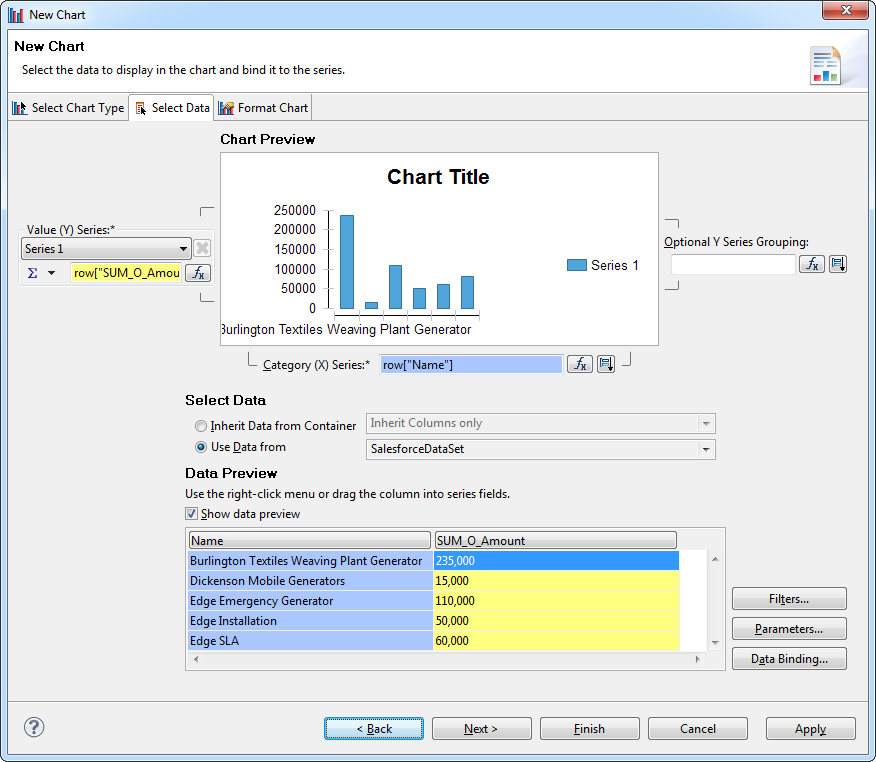
データセットを使用して、レポートオブジェクトにデータを入力できます。以下のステップに従って、チャートを作成します。
- [Palette]ビューで、チャートをキャンバスにドラッグします。
- [Select Chart Type]タブで棒グラフを選択します。
- [Select Data]タブで[Use Data From]オプションをクリックし、メニューからKafka のデータセットを選択します。
- Id をテーブルからx 軸の系列にドラッグします。
- Column1 をテーブルからy 軸の系列にドラッグします。
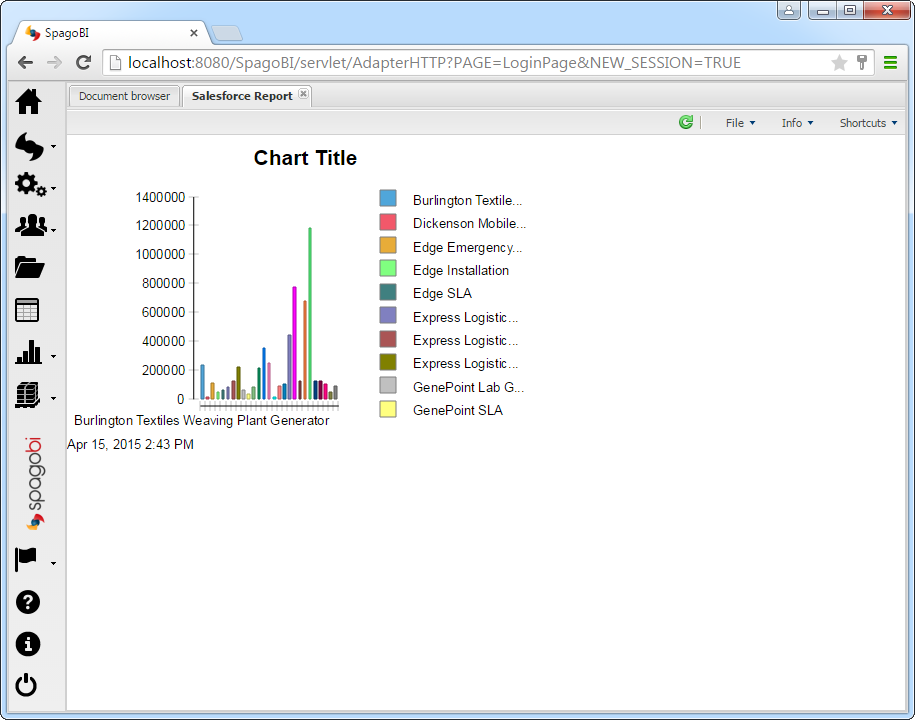
SpagoBI サーバーに関するホストKafka レポート
以下のステップに従って、SpagoBI サーバーでリアルタイムKafka に基づいてドキュメントをホストできます。前のセクションで作成したレポートをテンプレートとして使用します。レポートユーザーがリアルタイムデータにアクセスできるようにするには、サーバー上のKafka JDBC データソースに置き換えられるプレースホルダパラメータを作成します。
- 未実行の場合、SpagoBI Studio で[Report Design]パースペクティブで開きます。
- [Data Explorer]ビューで[Report Parameters]フォルダを右クリックし、[New Parameter]をクリックします。url パラメータを追加し、それに空の値を割り当てます。このパラメータはSpagoBI サーバー上のJDBC データソースのプレースホルダです。
- Kafka のデータソースを右クリックし、[Edit]をクリックします。
-
[Property Binding]ノードで、JDBC Driver のURL バインディングプロパティurl パラメータに設定します。プロパティのボックスをクリックします。[Category]セクションで[Report Parameters]を選択します。[Subcategory]セクションで[All]を選択し、パラメータをダブルクリックします。
JavaScript構文に以下のように入力することもできます。
params["url"].value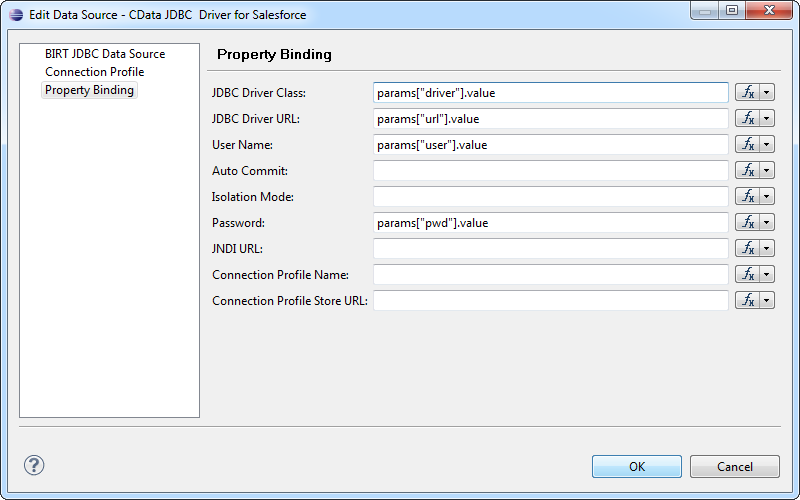
続いて、SpagoBI サーバーでレポート用の新しいドキュメントを作成します。
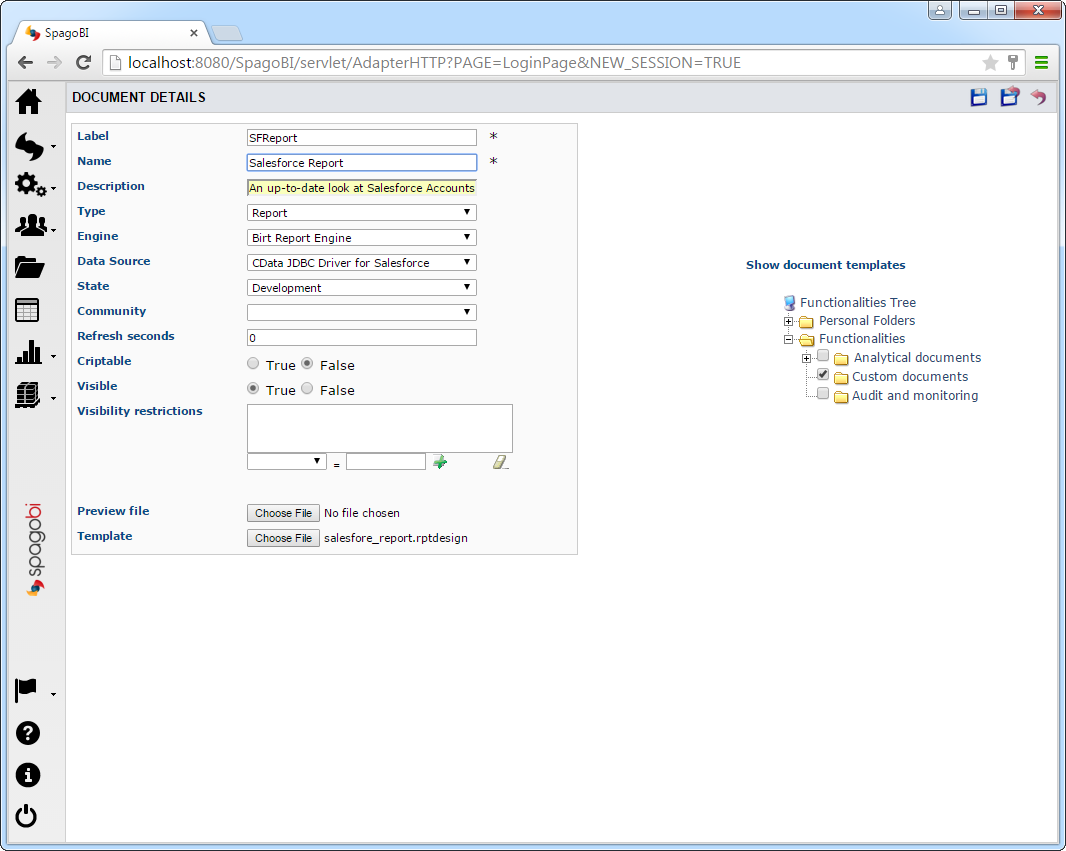
- SpagoBI サーバーで、[Documents Development]->[Create Document]->[Generic Document]と進みます。[Document Details]ページが表示されます。
- 以下の情報を入力し、ドキュメントを作成します。
- Label:ドキュメントに独自の識別子を入力します。
- Name:ドキュメントのわかりやすい名前を入力します。
- Type:メニューから[Report]を選択します。
- Engine:[BIRT Report Engine]を選択します。
- Data Source:SpagoBI サーバーのCreate a JDBC Data Source for ApacheKafka で作成したKafka Data Source を選択します。
- [Show Document Templates]セクションで、ドキュメントを格納したいフォルダを選択します。
[Template]セクションで、[Choose File]をクリックします。レポートプロジェクトを含むフォルダに移動します。.rptdesign ファイルを選択します。
Noteプロジェクトへのパスは、プロジェクトプロパティで確認できます。
- [Save]ボタンをクリックします。
サーバーでレポートを実行すると、プレースホルダurl パラメータがサーバーで定義されたJDBC URL に置き換えられます。