各製品の資料を入手。
詳細はこちら →



製品をチェック
CSA Data Uploader にてKafka のデータを、クラウドストレージにアップロード
Kafka へのライブ接続を行うデータアップロードジョブを構築
最終更新日:2022-03-15
この記事で実現できるKafka 連携のシナリオ


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData ODBC ドライバは、ODBC 標準インターフェースを利用したKafka へのリアルタイムデータアクセスを可能にし、使い慣れたSQL クエリで多種多様なBI、レポート、ETL ツールでKafka を扱うことができます 。
この記事では、Amazon S3 やGoogle Cloud Storage などのクラウドストレージへのデータプレパレーション、ファイルアップロードを得意とするCSA Data Uploader でODBC 接続を使用してKafka のデータの利用方法を示します。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
- Kafka をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレミスデータソースに対応
- 多様なアプリケーション、ツールにKafka のデータを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてKafka の接続を設定、2.CSA Data Uploader 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとKafka への接続設定
まずは、本記事右側のサイドバーからApacheKafka ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
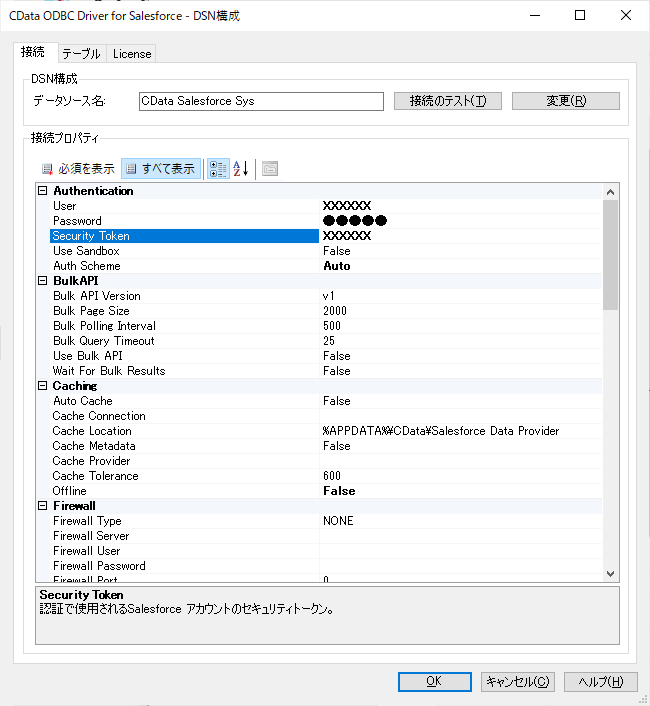
- まずODBN DSN に必要な接続プロパティの値を入力します。組み込みのMicrosoft ODBC データソースアドミニストレーターを使用してDSN を構成できます。これは、ドライバーのインストール時の最後のステップでも可能です。Microsoft ODBC データソースアドミニストレータを使用してDSN を作成および設定する方法については、ヘルプドキュメントの「はじめに」の章を参照してください。
Apache Kafka 接続プロパティの取得・設定方法
.NET ベースのエディションは、Confluent.Kafka およびlibrdkafka ライブラリに依存して機能します。 これらのアセンブリはインストーラーにバンドルされ、自動的に本製品と一緒にインストールされます。 別のインストール方法を利用する場合は、NuGet から依存関係のあるConfluent.Kafka 2.6.0 をインストールしてください。
Apache Kafka サーバーのアドレスを指定するには、BootstrapServers パラメータを使用します。
デフォルトでは、本製品はデータソースとPLAINTEXT で通信し、これはすべてのデータが暗号化なしで送信されることを意味します。 通信を暗号化するには:
- UseSSL をtrue に設定し、本製品がSSL 暗号化を使用するように構成します。
- SSLServerCert およびSSLServerCertType を設定して、サーバー証明書をロードします。
Apache Kafka への認証
Apache Kafka データソースは、次の認証メソッドをサポートしています:- Anonymous
- Plain
- SCRAM ログインモジュール
- SSL クライアント証明書
- Kerberos
Anonymous
Apache Kafka の特定のオンプレミスデプロイメントでは、認証接続プロパティを設定することなくApache Kafka に接続できます。 こうした接続はanonymous(匿名)と呼ばれます。
匿名認証を行うには、このプロパティを設定します。
- AuthScheme:None。
その他の認証方法については、ヘルプドキュメントを参照してください。
- CSA Data Uploader を開いて「設定 -> ODBC」に移動します。
- 「追加」をクリックします。
- 種別を「汎用ODBC」、「データソース名」で先ほど作成したODBC DSN を選択します。
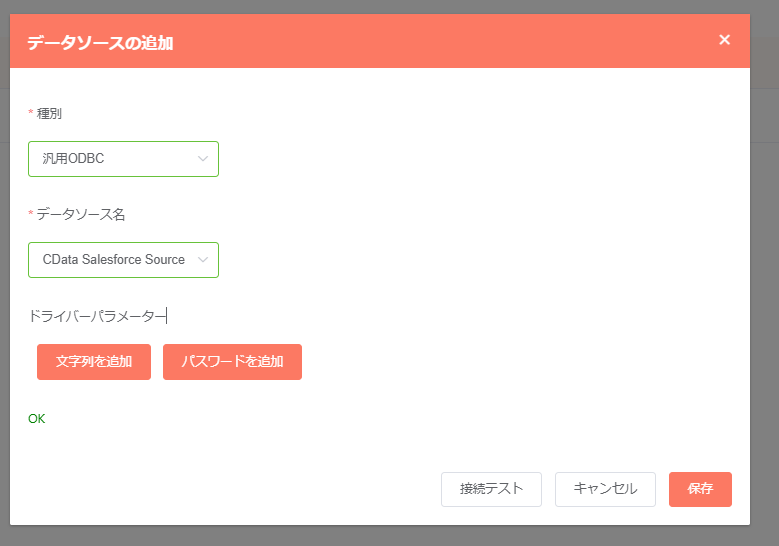
入力後、接続テストが成功すれば設定は完了です。併せて任意のデータアップロード先の接続(Amazon S3・Google Cloud Storage など)も作成しておきましょう。
Kafka ジョブの構成
続いてCSA DataUploader の対象データ参照し、クラウドストレージへデータをアップロードするジョブを構成します。
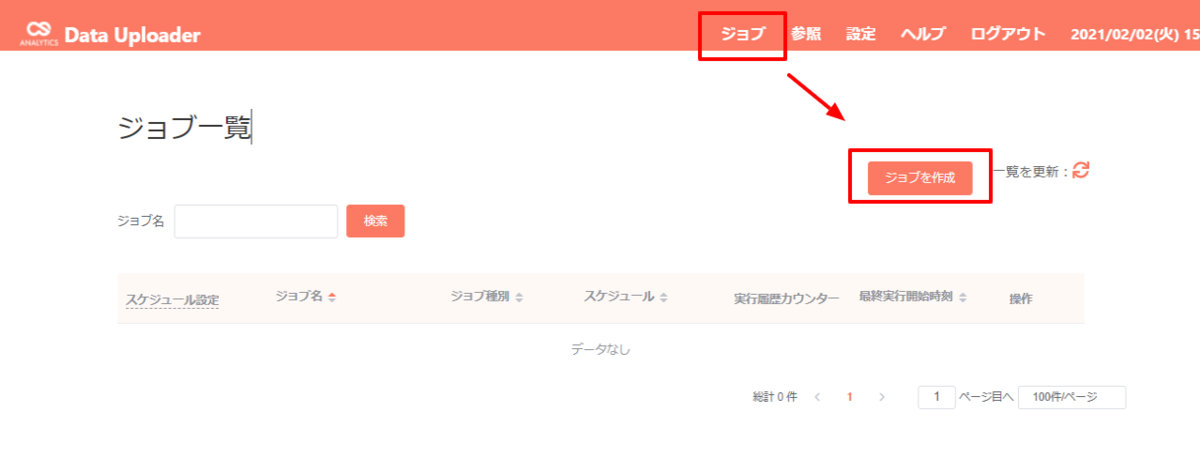
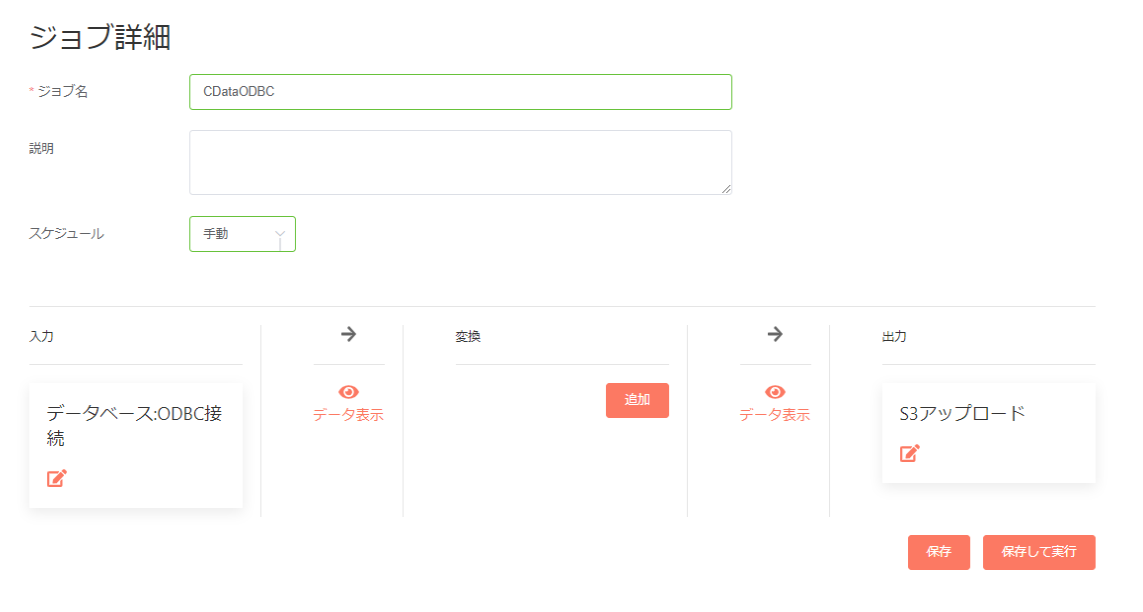
- 「ジョブ」のページに移動して「ジョブを作成」をクリックします。
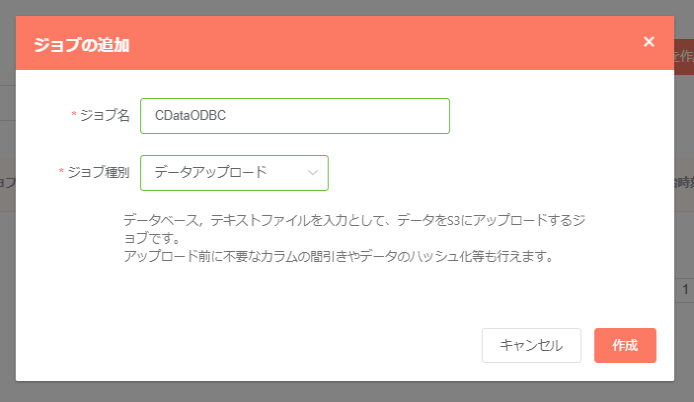
- 任意の名称でジョブを作成します。ジョブ種別は「データアップロード」を選んでください。
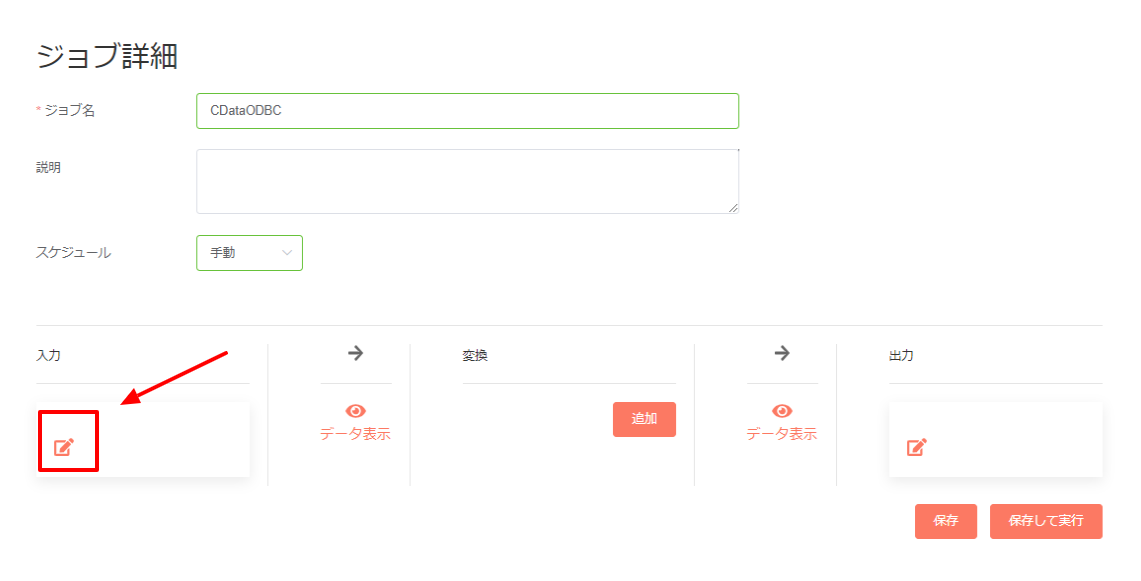
- ジョブは最初に入力対象となるデータを設定します。
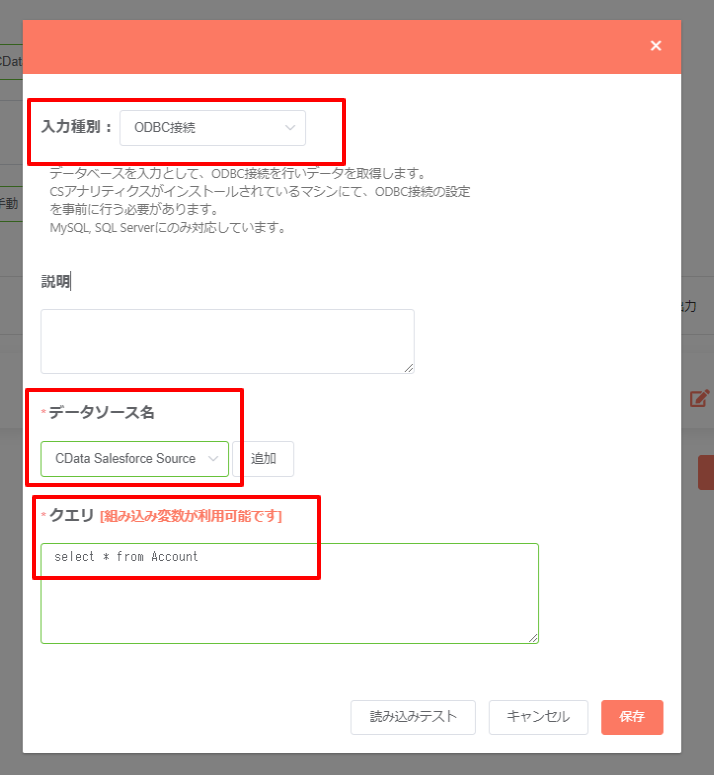
- 入力種別では、ODBC 接続を選択し、データソース名で先ほど設定したODBC DSN を選択します。併せて、Kafka からデータを取得するためのSQL ベースのクエリを記述します。
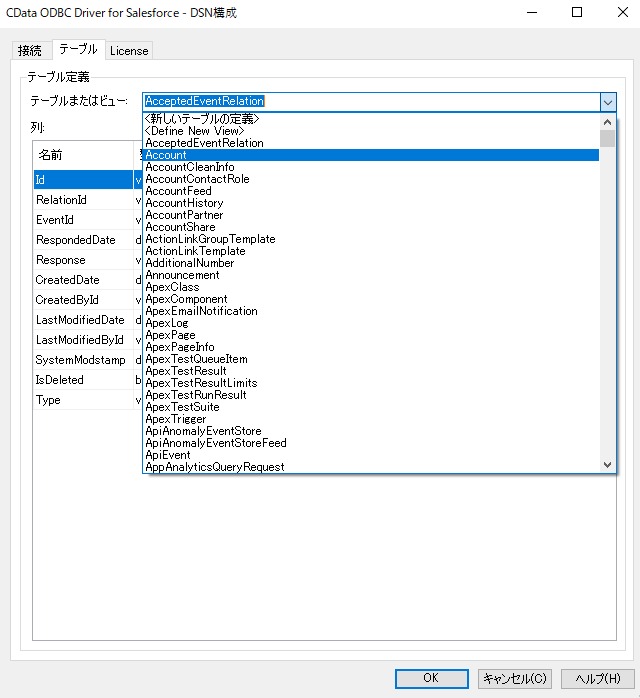
- なお、SQL でクエリ可能なテーブルはODBC DSN の「テーブル」タブで確認できます。
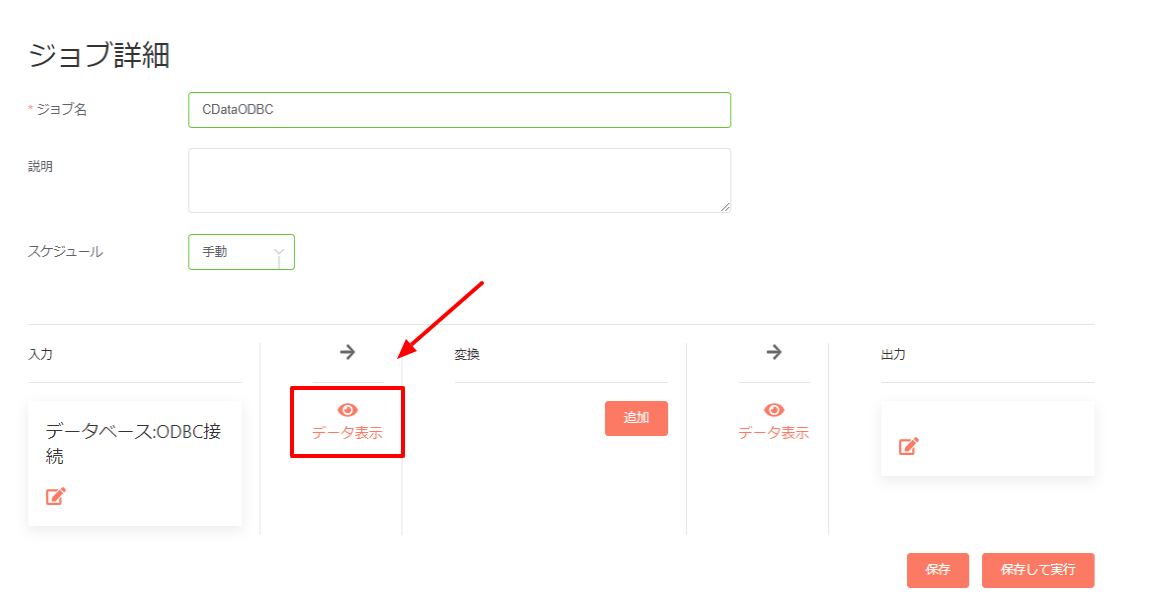
- 入力設定を保存したら、「データ表示」ボタンをクリックすることで実際にKafka から取得したデータを確認できます。
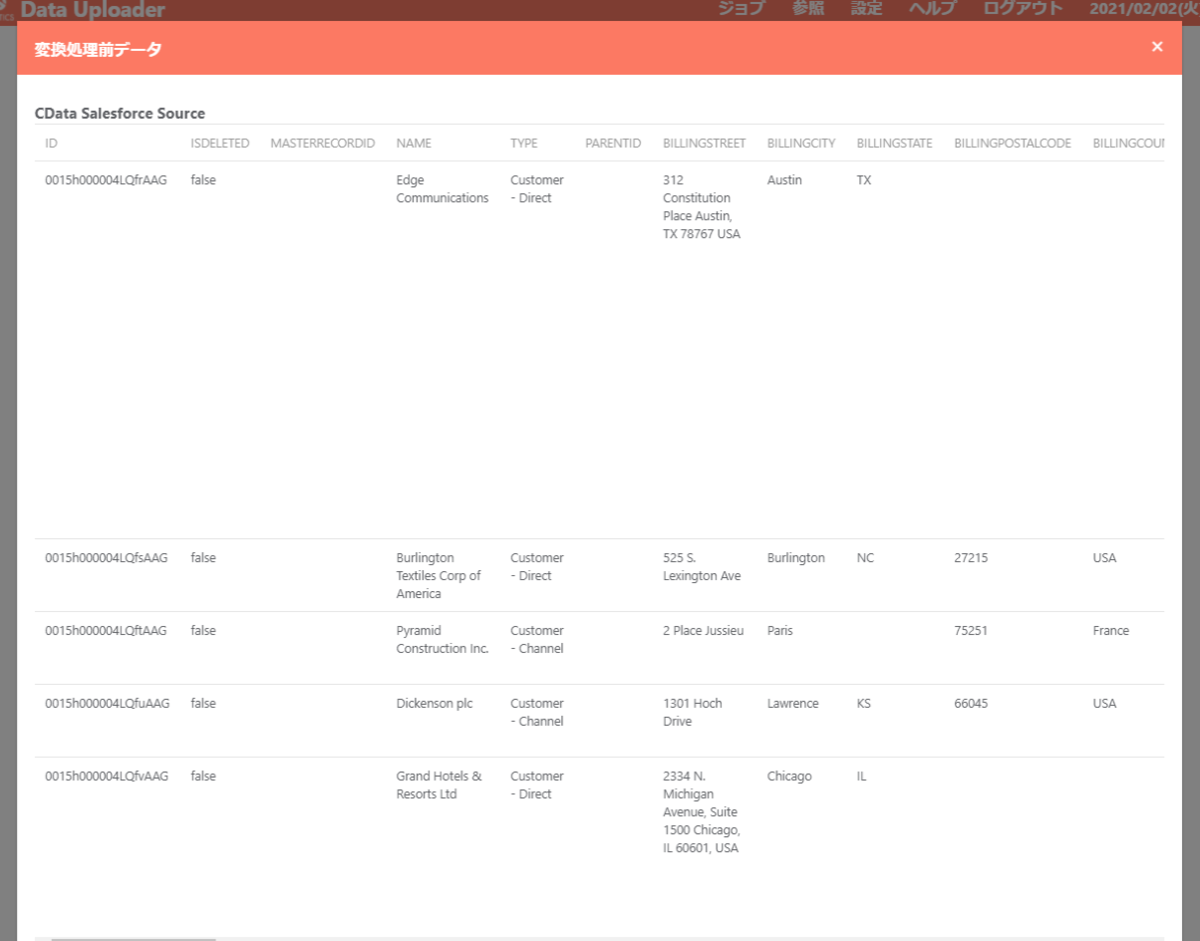
- 以下のようにプレビューが表示されれば設定はOK です。
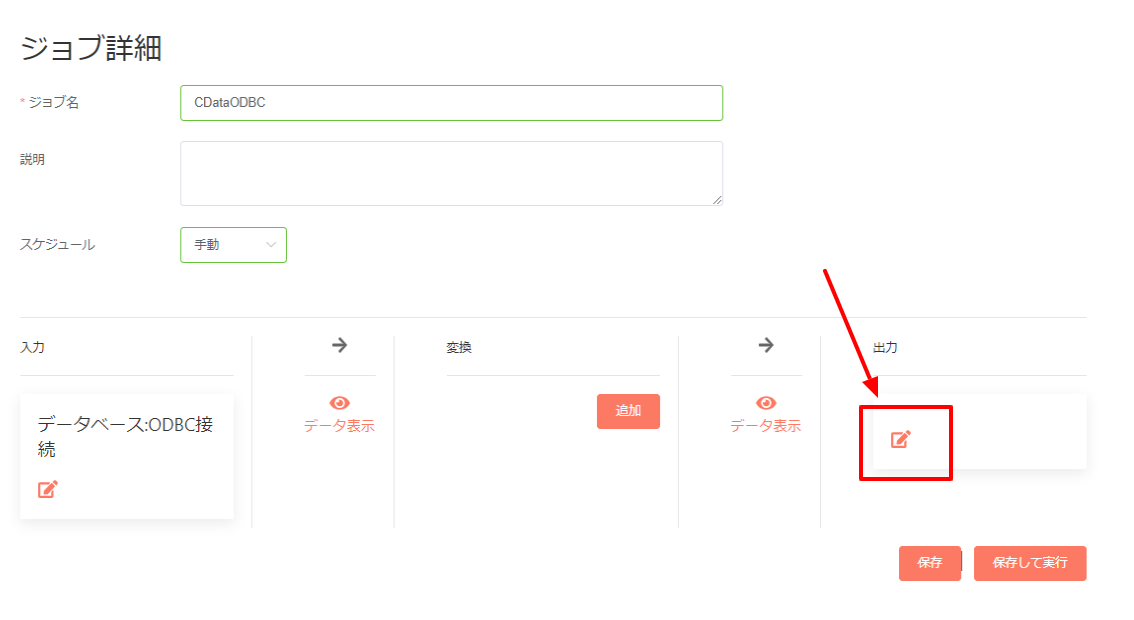
- 併せて出力設定先となるクラウドストレージの情報を追加してください。
- 事前に構成したコネクション情報で出力先を設定します。
- これでジョブの作成は完了です。実行することで Kafka のデータをクラウドストレージにアップロードすることができます。
おわりに
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。