各製品の資料を入手。
詳細はこちら →



Spark をSSIS 経由でSQL サーバーにバックアップする
Spark 用のCData ADO.NET プロバイダーを使用して簡単にSQL サーバーへデータをバックアップします。ここでは、Spark をデータベースに入力する際、SSIS ワークフローを使用します。
最終更新日:2022-04-12
こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Spark 用のCData ADO.NET プロバイダーはSpark をバックアップ、レポート、フルテキスト検索、分析などを行うアプリケーションに接続します。
ここでは、SQL サーバー SSIS ワークフロー内でSpark 用のプロバイダーを使用して、Spark をMicrosoft SQL サーバーデータベースに直接転送する方法を説明します。 以下のアウトラインと同じ手順を、CData ADO.NET データプロバイダーにて使用することで、SSIS 経由でSQL サーバーを直接リモートデータに接続できます。
- Visual Studio を開き、新しいIntegration サービスプロジェクトを追加します。
- ツールボックスからControl Flow 画面へ、新しいData Flow タスクを追加します。
Data Flow 画面で、ツールボックスから[ADO.NET Source] と[OLE DB Destination] を追加します。
- 新しい接続を追加し、Spark 2015 用の .NET プロバイダー\CData ADO.NET プロバイダーを選択します。
Connection Manager で、Spark 用に接続の詳細を入力します。下は一般的な接続文字列です。
Server=127.0.0.1;
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
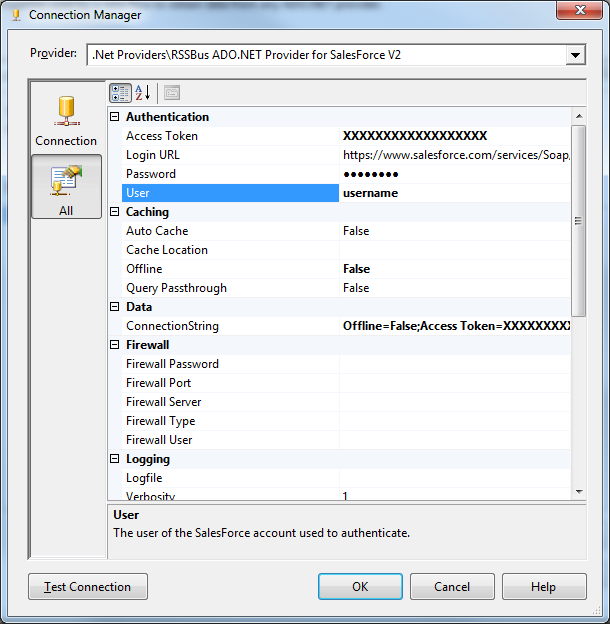
DataReader editor を開き、次のインフォメーションを設定します。
- ADO.NET 接続マネージャー:Connection Manager のメニューで、先ほど作成した[Data Connection] を選択します。
- データアクセスモード:[SQL command] を選択します。
- SQL command テキスト:DataReader Source editor で、Component Properties タブを開き、下にあるようなSELECT command を入力します。
SELECT City, Balance FROM Customers
- DataReader editor を閉じ、DataReader Source の下の矢印をドラッグして、OLE DB Destination に接続します。
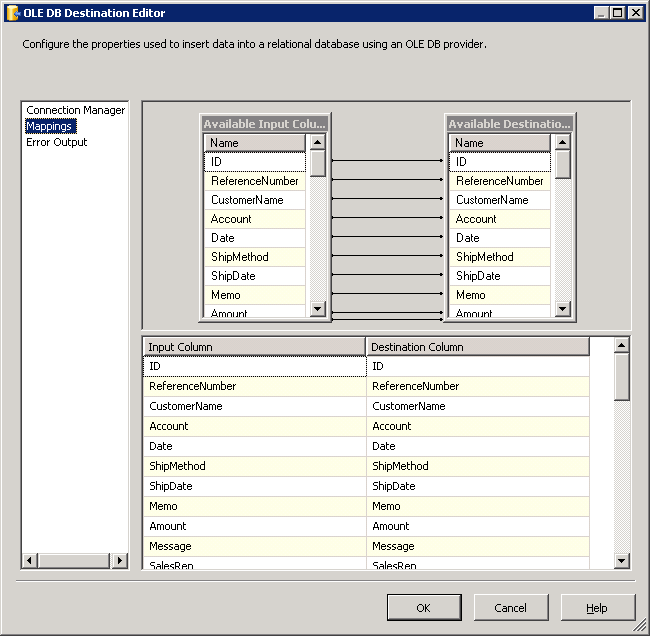
OLE DB Destination を開き、Destination Component Editor で次のインフォメーションを入力します。
- コネクションマネージャー:新しい接続を追加します。接続するサーバーおよびデータベースの情報を入力します。ここでは、SQLExpress は他のマシンで運用中です。
- データアクセスモード:データアクセスモードを[table or view] に設定し、データベースに入力するテーブルまたはビューを選択します。
Mappings 画面で必要なプロパティを設定します。
- OLE DB Destination Editor を閉じ、プロジェクトを始動します。SSIS タスクの実行が完了すれば、 Spark から取得したデータが、データベースに入力されます。