各製品の資料を入手。
詳細はこちら →



Salesforce Connect で外部Spark オブジェクトを編集および検索
CData Connect Server を使用すれば、Spark のデータのOData フィードをスマートデバイスにセキュアに送信できます。CData Connect とSalesforce Connect を使用して、アプリやダッシュボードからアクセスできるSpark オブジェクトを作成します。
最終更新日:2021-02-10
こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData Connect Server を使用すると、Salesforce コンソールのようなアプリケーションや、Salesforce1 Mobile App のようなモバイルアプリケーションからSpark のデータにアクセスできます。この記事ではCData Connect Server とSalesforce Connect を使用して、標準のSalesforce オブジェクトと外部のSpark オブジェクトにアクセスします。
Connect Server を構成する
Salesforce Connect でリアルタイムSpark のデータを操作するには、Connect Server からSpark に接続し、新しい仮想データベースへのユーザーアクセスを提供してSpark のデータのOData エンドポイントを作成する必要があります。
Connect Server ユーザーを追加する
Reveal からConnect Server を介してSpark に接続するユーザーを作成します。
- [Users]->[ Add]とクリックします。
- ユーザーを構成します。
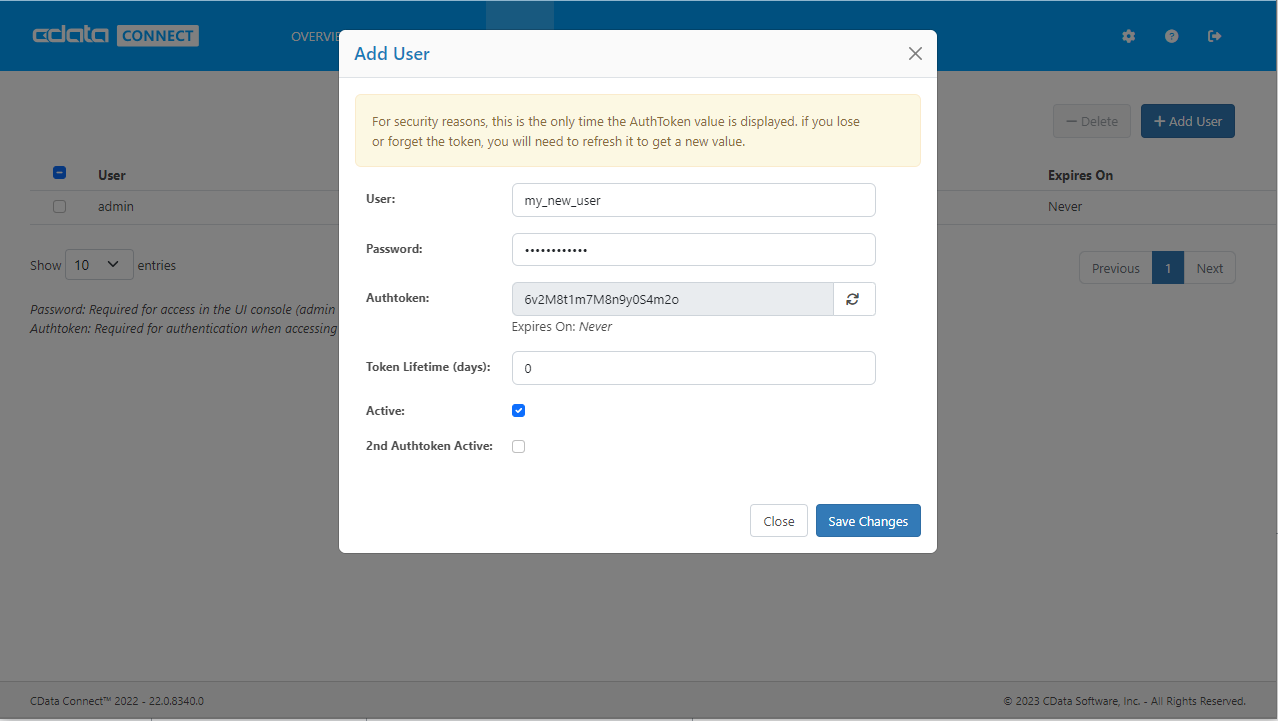
- [Save Changes]をクリックして新しいユーザーの認証トークンをメモします。
Connect Server からSpark に接続
CData Connect Server は、簡単なポイントアンドクリックインターフェースを使用してAPI を生成します。
- Connect Server を開き、「Databases」をクリックします。
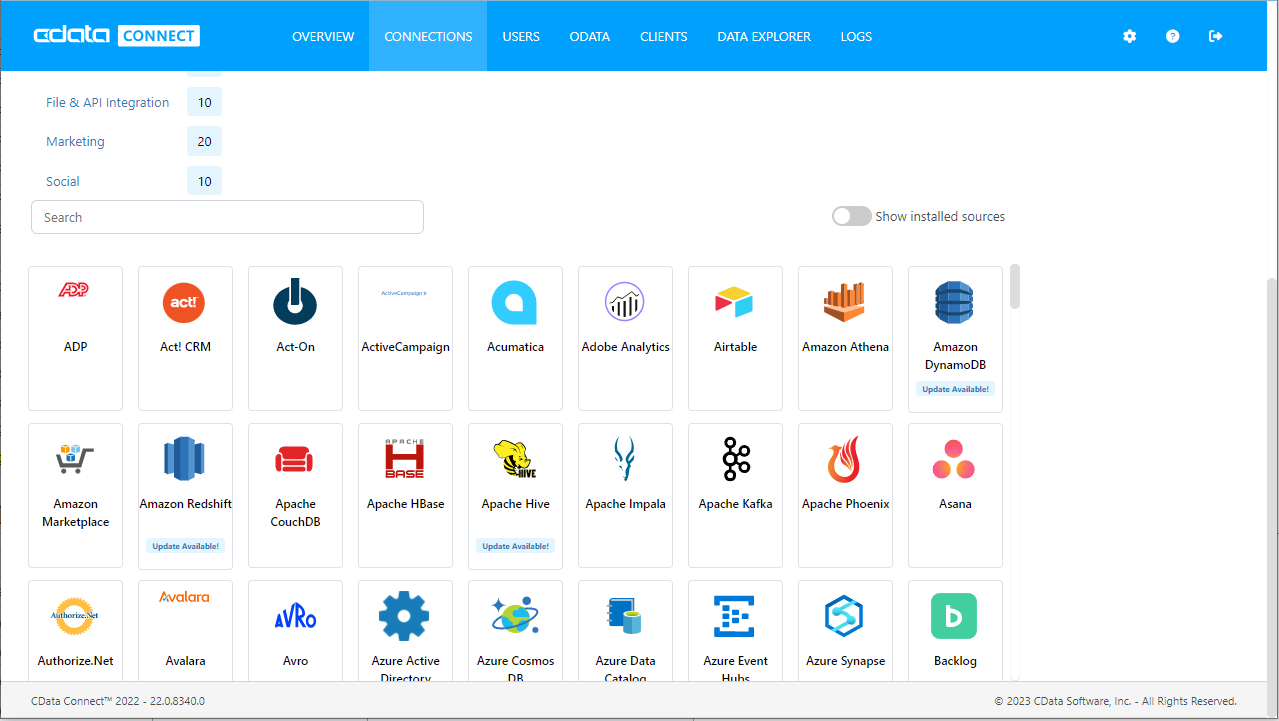
- 「Available Data Sources」から「Spark」を選択します。
- 必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
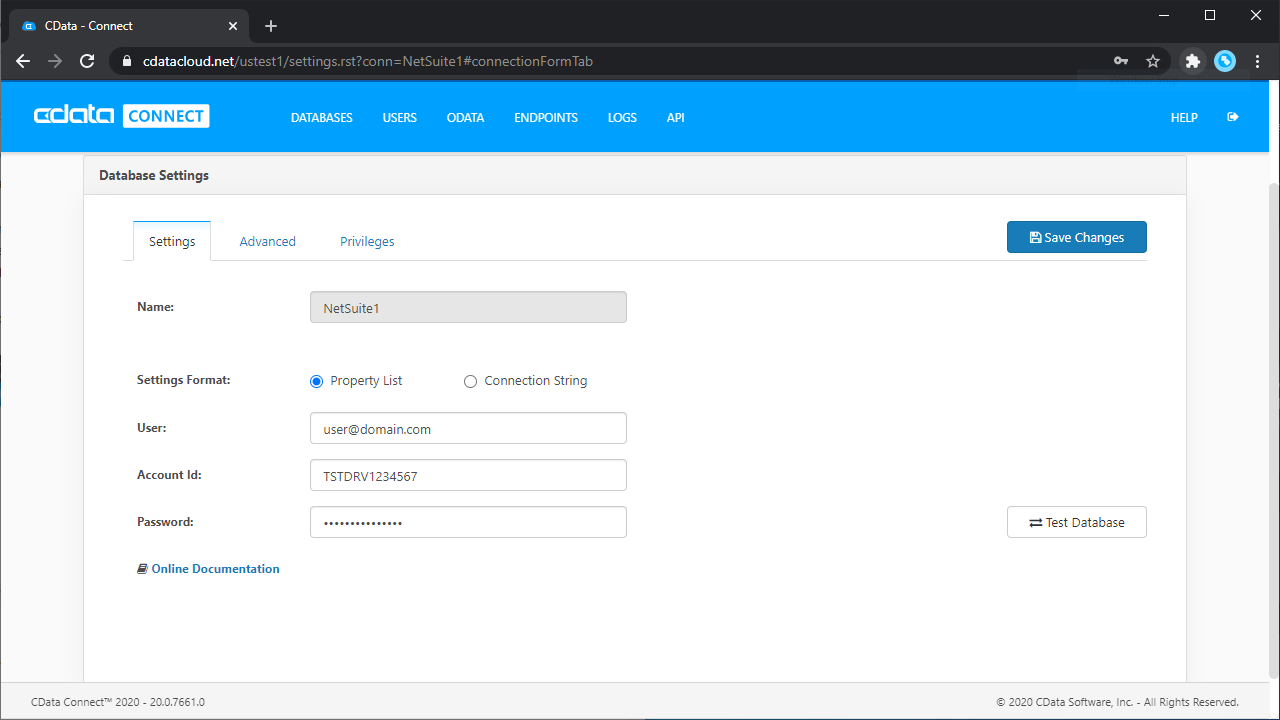
- 「 Test Database」をクリックします。
- 「Permission」->「 Add」とクリックし、適切な権限を持つ新しいユーザー(または既存のユーザー)を追加します。(Reveal に必要なのは、SELECT のみです。)
Connect Server にSpark OData エンドポイントを追加する
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
- 「OData」->「Tables」->「Add Tables」とクリックします。
- Spark のデータベースを選択します。
- 使用するテーブルを選択し、「Next」をクリックします。
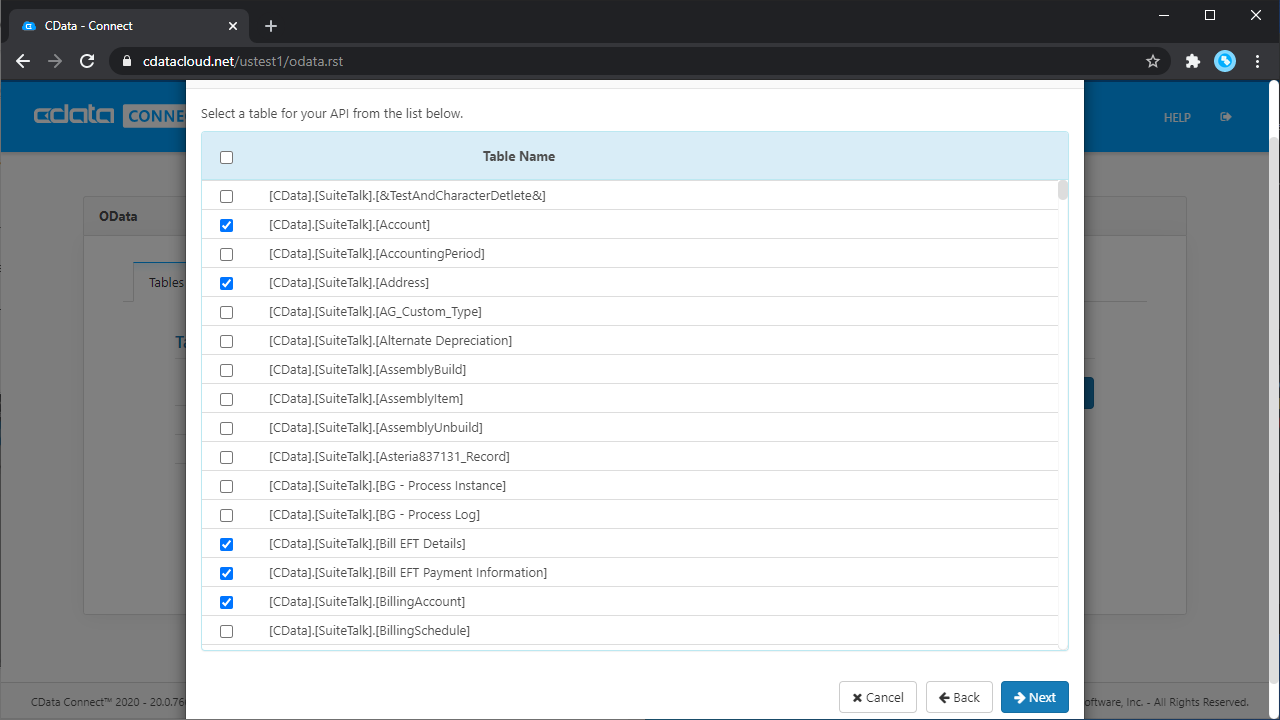
- (オプション)テーブルの定義を編集して特定のフィールドなどを選択します。
- 設定を保存します。
(オプション)Cross-Origin Resource Sharing (CORS) を構成する
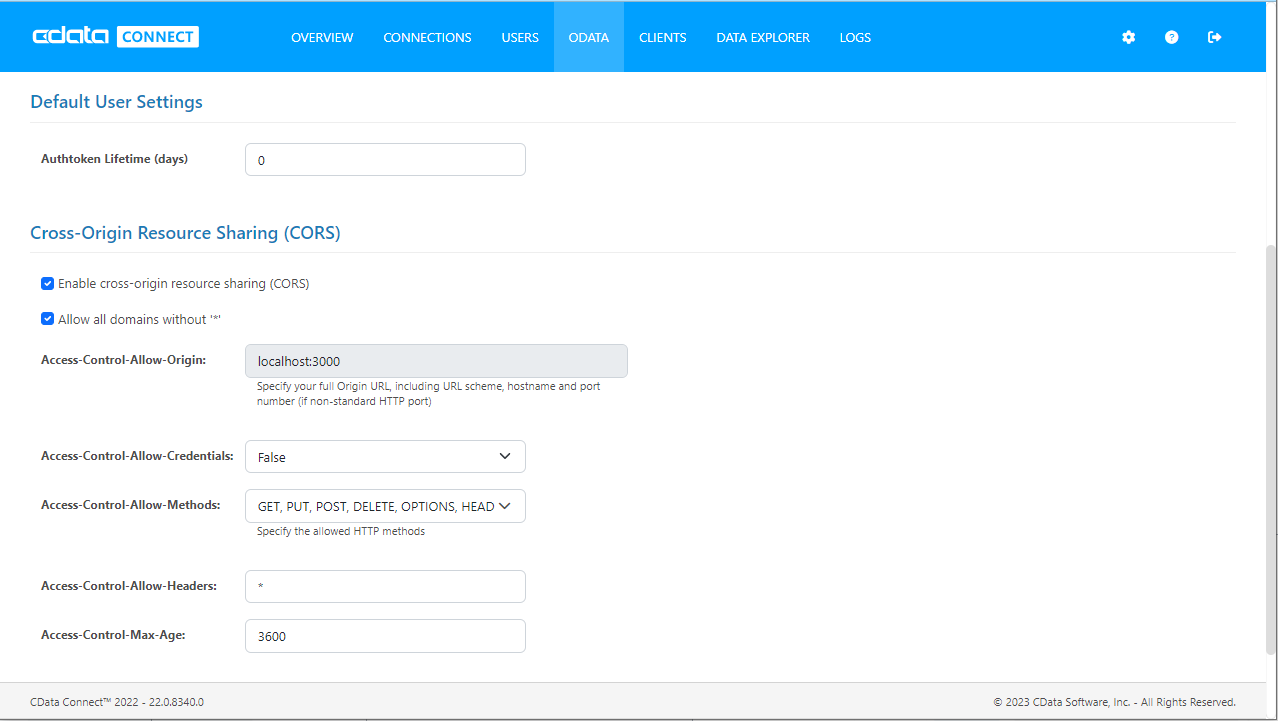
複数の異なるドメインにアクセスして接続すると、クロスサイトスクリプティングの制限に違反する恐れがあります。その場合には、「OData」->「Settings」でCORS 設定を構成します。
- Enable cross-origin resource sharing (CORS):ON
- Allow all domains without '*':ON
- Access-Control-Allow-Methods:GET、PUT、POST、OPTIONS
- Access-Control-Allow-Headers:Authorization
設定への変更を保存します。
外部データソースとしてSpark のデータに接続する
以下のステップに従って、CData Connect に生成されたフィードに接続します。
- Salesforce にログインし、「Setup」->「Integrations」->「External Data Sources」とクリックします。
- 「New External Data Source」をクリックします。
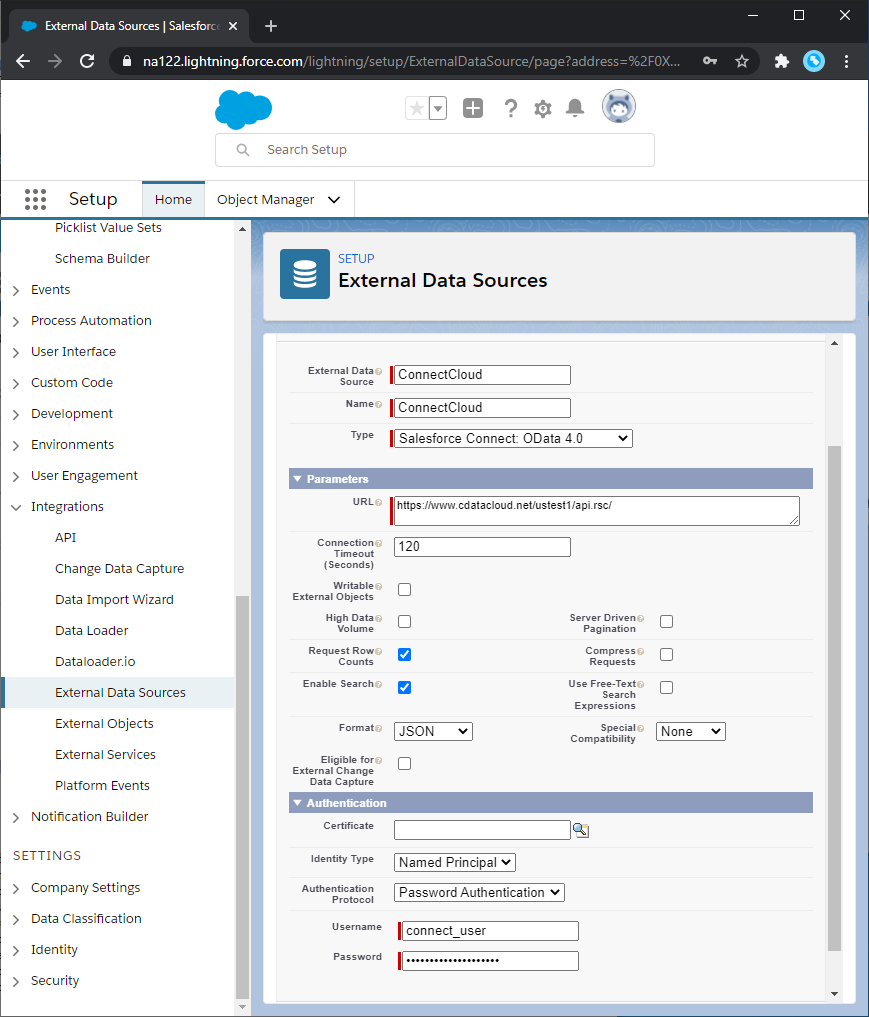
- 以下のプロパティに値を入力します。
- External Data Source:リストビューおよびレポートで使用するラベルを入力します。
- Name:固有の識別子を入力します。
- Type:「Salesforce Connect: OData 4.0」オプションを選択します。
URL:CData Connect OData エンドポイントのURL を入力します。OData URL のフォーマットはCONNECT_SERVER_URL/api.rsc/ です。
- 「Writable External Objects」オプションを選択します。
「Format」メニューから「JSON」を選択します。
- 「Authentication」セクションでは、以下のプロパティを設定します。
- Identity Type:組織のすべてのメンバーが同じ認証情報を使用してCData Connect にアクセスする場合は、「Named Principal」を選択します。各自の認証情報で接続する場合は、「Per User」を選択します。
- Authentication Protocol:Basic 認証を使用するには、「Password Authentication」を選択します。
- Certificate:Salesforce からサーバーへの通信を暗号化及び認証するために使用する証明書を入力、または参照します。
- Username:CData Connect Server に追加したユーザーのユーザー名を入力します。
- Password:ユーザーの認証トークンを入力します。
Spark オブジェクトを同期する
外部データソースを作成したら、以下のステップに従って、データソースへの変更を反映するSpark 外部オブジェクトを作成します。Spark 外部オブジェクトの定義をSpark テーブルの定義と同期します。
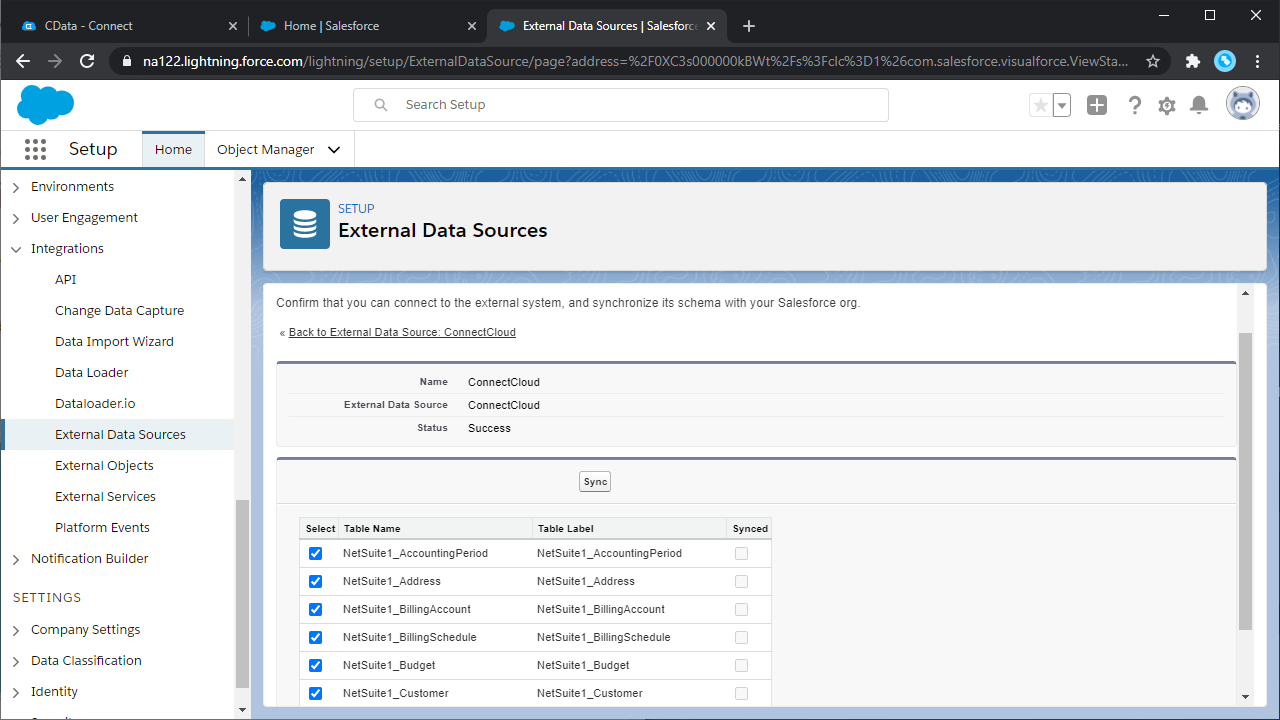
- 作成した外部データソースのリンクをクリックします。
- 「Validate and Sync」をクリックします。
- 外部オブジェクトとして使用するSpark テーブルを選択します。
Salesforce オブジェクトとしてSpark のデータにアクセスする
Spark のデータを外部データソースとして追加し、Spark テーブルを外部オブジェクトとして同期すると、標準のSalesforce オブジェクトと同じように外部Spark オブジェクトを使用できるようになります。
-
フィルタリストビューを使用して新しいタブを作成します。
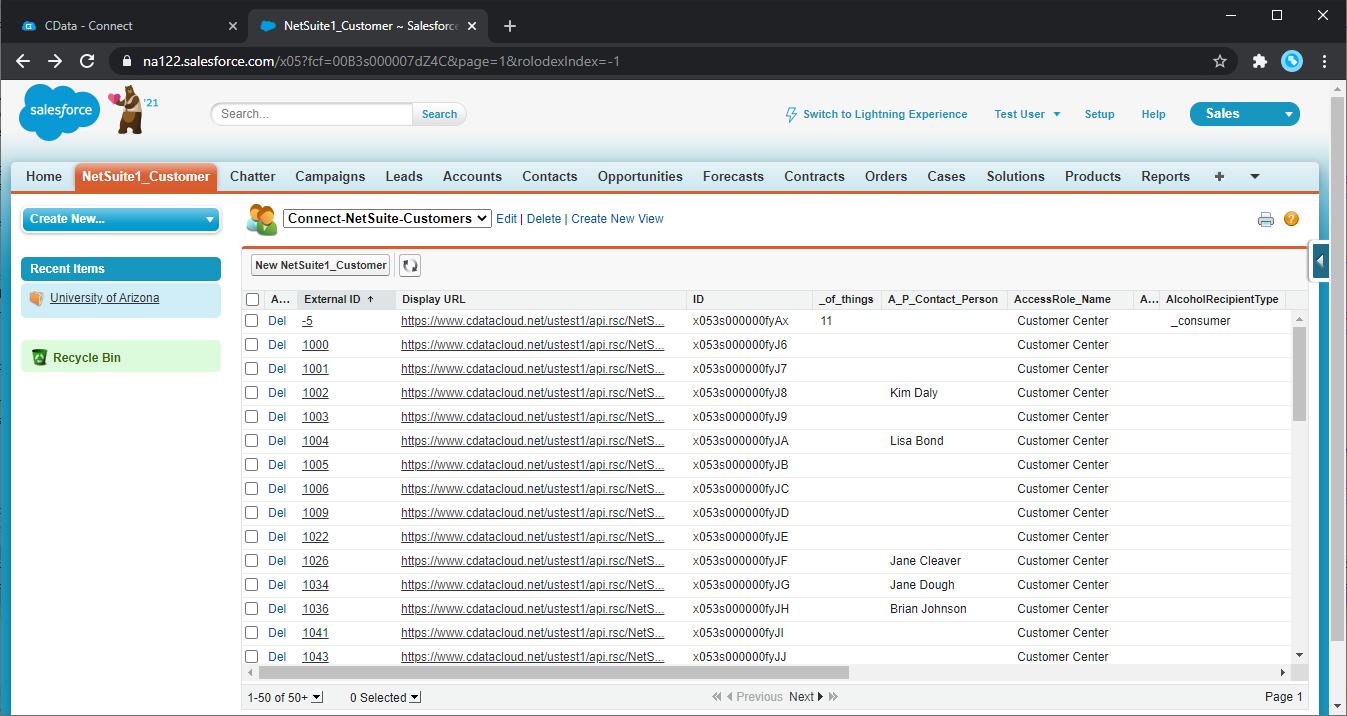
-
外部オブジェクトのレポートを作成します。
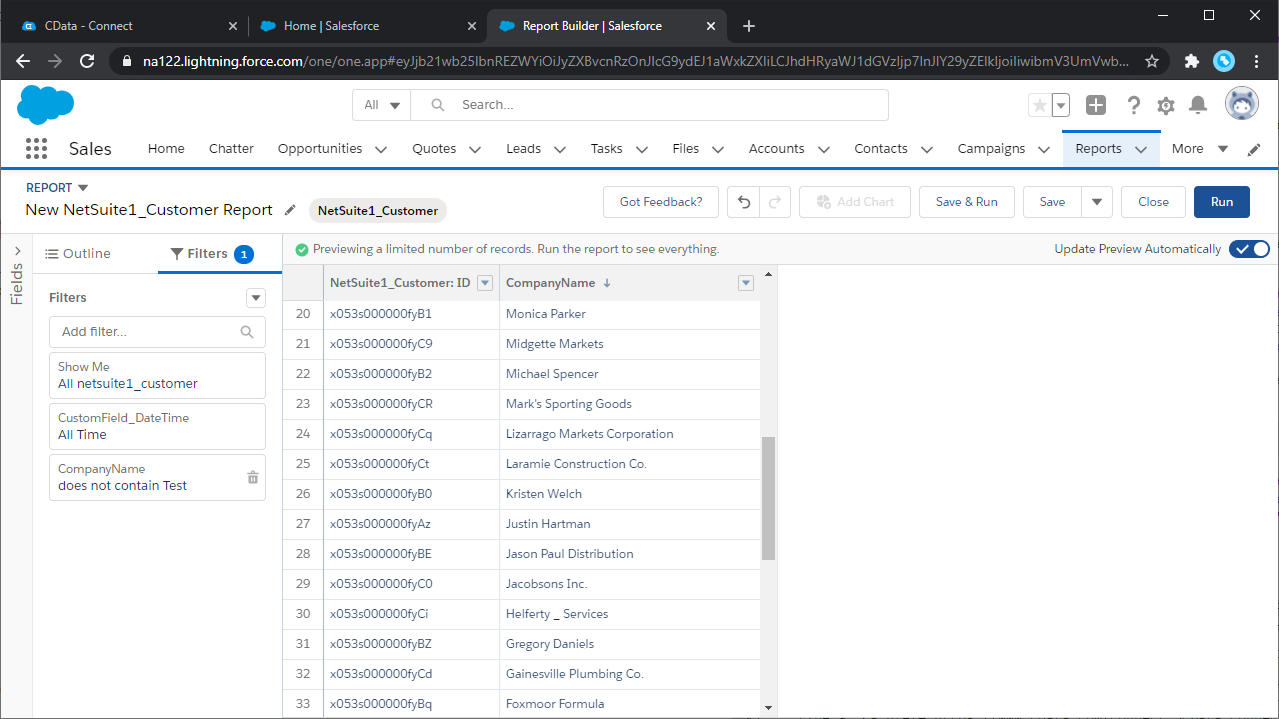
-
Salesforce ダッシュボードから、Spark オブジェクトを作成、更新、および削除します。
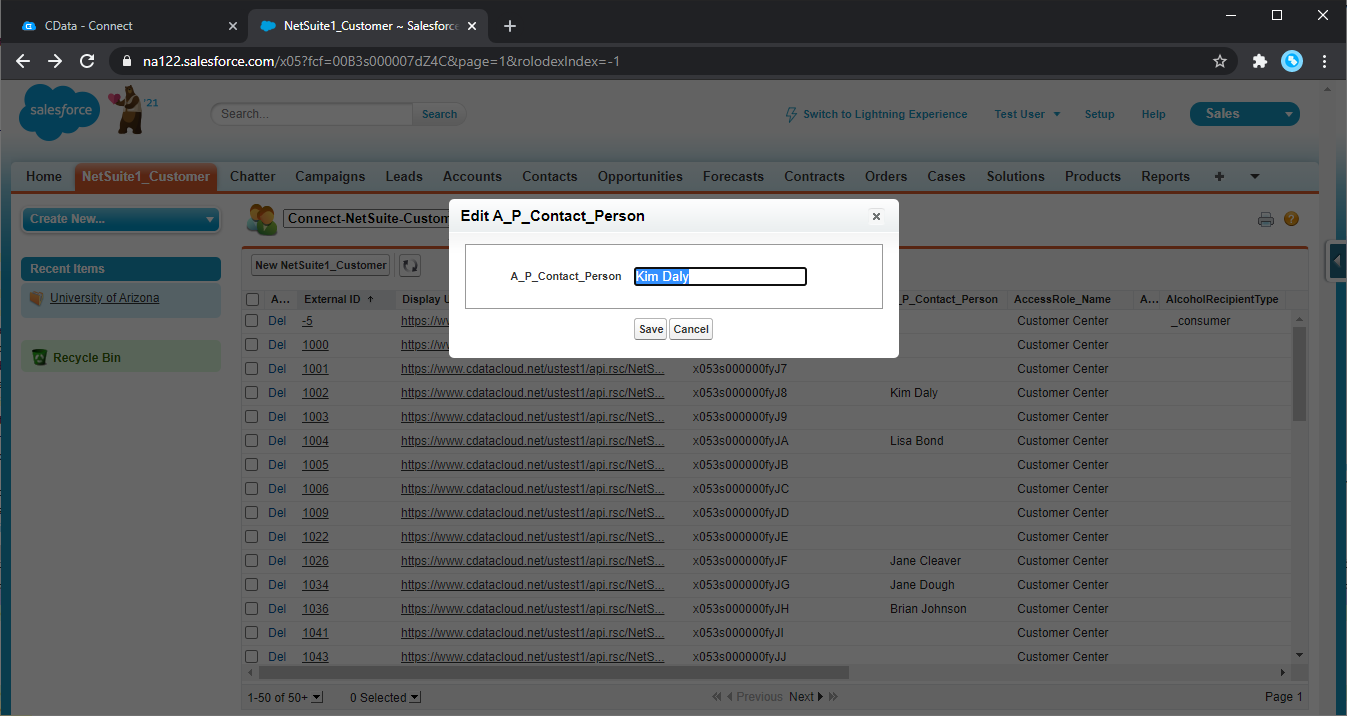
アプリケーションから簡単にSpark のデータにアクセスする
この時点で、Salesforce からリアルタイムSpark のデータに直接接続ができます。Salesforce のようなアプリケーションから簡単に100を超えるSaaS、Big Data、NoSQL ソースのデータにアクセスする方法の詳細は、Connect Server ページを参照してください。