各製品の資料を入手。
詳細はこちら →



製品をチェック

複数のKafka アカウントのレプリケーション
Kafka の複数のアカウントを一つ、もしくは複数のデータベースに同期。
最終更新日:2022-11-28
こんにちは!プロダクトスペシャリストの宮本です。
CData Sync は、いろいろなシナリオのデータレプリケーション(同期)を行うことができるスタンドアロンのアプリケーションです。例えば、sandbox および本番インスタンスのデータをデータベースに同期することができます。CData Sync のウェブインターフェースは複数のKafka コネクションを簡単に管理できます。本記事では、複数のKafka アカウントを一つのデータベースに同期する方法を説明します。
レプリケーションの同期先を設定
CData Sync では、Kafka のデータ を何台のデータベースにでも複製できます。データベースはクラウドおよびオンプレミスの双方に対応しています。レプリケーションの同期先の設定には、[接続]タブから行います。
- [同期先]タブを選択します。
- 同期先のアイコンをクリックします。本記事では、SQLite を使います。
- 必要な接続プロパティを入力します。Kafka をSQLite に複製するには、データソースボックスにファイルパスを指定します。
- [接続のテスト]をクリックして、正しく接続できているかをテストします。
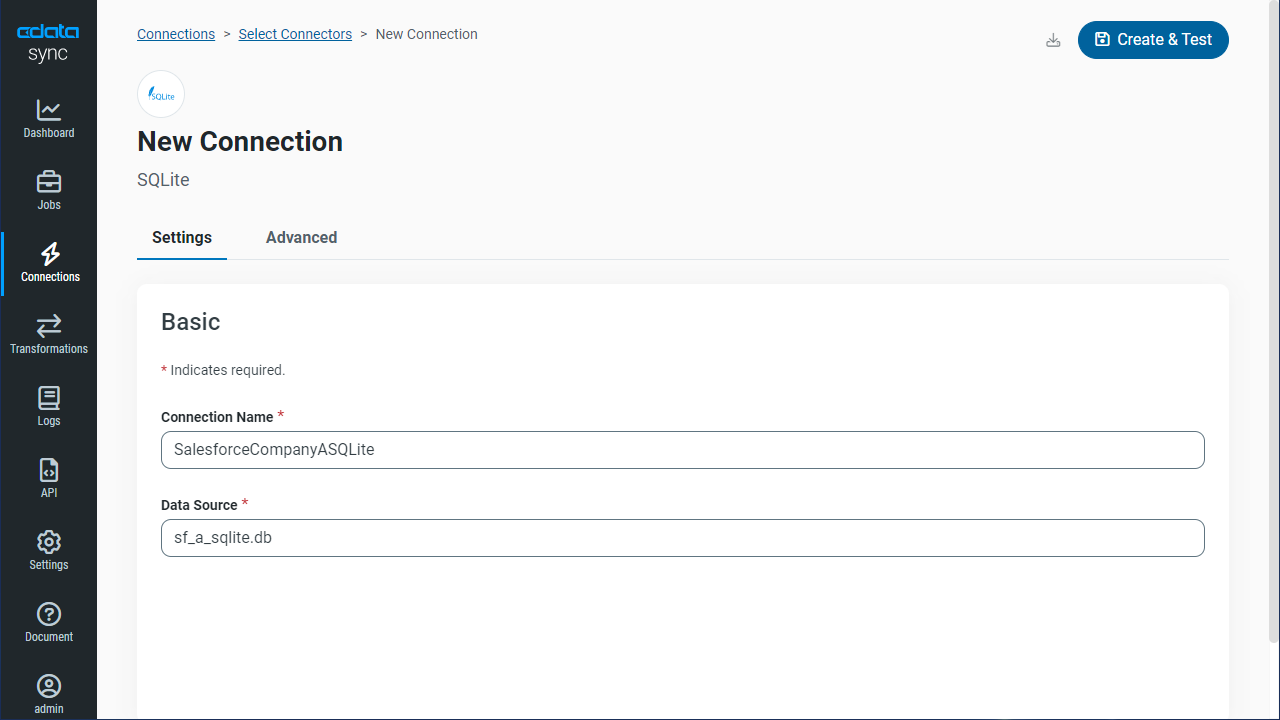
- [変更を保存]をクリックします。
Kafka 接続の設定
データソース側にKafka を設定します。[接続]タブをクリックします。
- [接続の追加]セクションで[データソース]タブを選択します。
- Kafka アイコンをデータソースとして選択します。プリインストールされたソースにKafka がない場合には、追加データソースとしてダウンロードします。
- 接続プロパティに入力をします。
Apache Kafka 接続プロパティの取得・設定方法
.NET ベースのエディションは、Confluent.Kafka およびlibrdkafka ライブラリに依存して機能します。 これらのアセンブリはインストーラーにバンドルされ、自動的に本製品と一緒にインストールされます。 別のインストール方法を利用する場合は、NuGet から依存関係のあるConfluent.Kafka 2.6.0 をインストールしてください。
Apache Kafka サーバーのアドレスを指定するには、BootstrapServers パラメータを使用します。
デフォルトでは、本製品はデータソースとPLAINTEXT で通信し、これはすべてのデータが暗号化なしで送信されることを意味します。 通信を暗号化するには:
- UseSSL をtrue に設定し、本製品がSSL 暗号化を使用するように構成します。
- SSLServerCert およびSSLServerCertType を設定して、サーバー証明書をロードします。
Apache Kafka への認証
Apache Kafka データソースは、次の認証メソッドをサポートしています:- Anonymous
- Plain
- SCRAM ログインモジュール
- SSL クライアント証明書
- Kerberos
Anonymous
Apache Kafka の特定のオンプレミスデプロイメントでは、認証接続プロパティを設定することなくApache Kafka に接続できます。 こうした接続はanonymous(匿名)と呼ばれます。
匿名認証を行うには、このプロパティを設定します。
- AuthScheme:None。
その他の認証方法については、ヘルプドキュメントを参照してください。
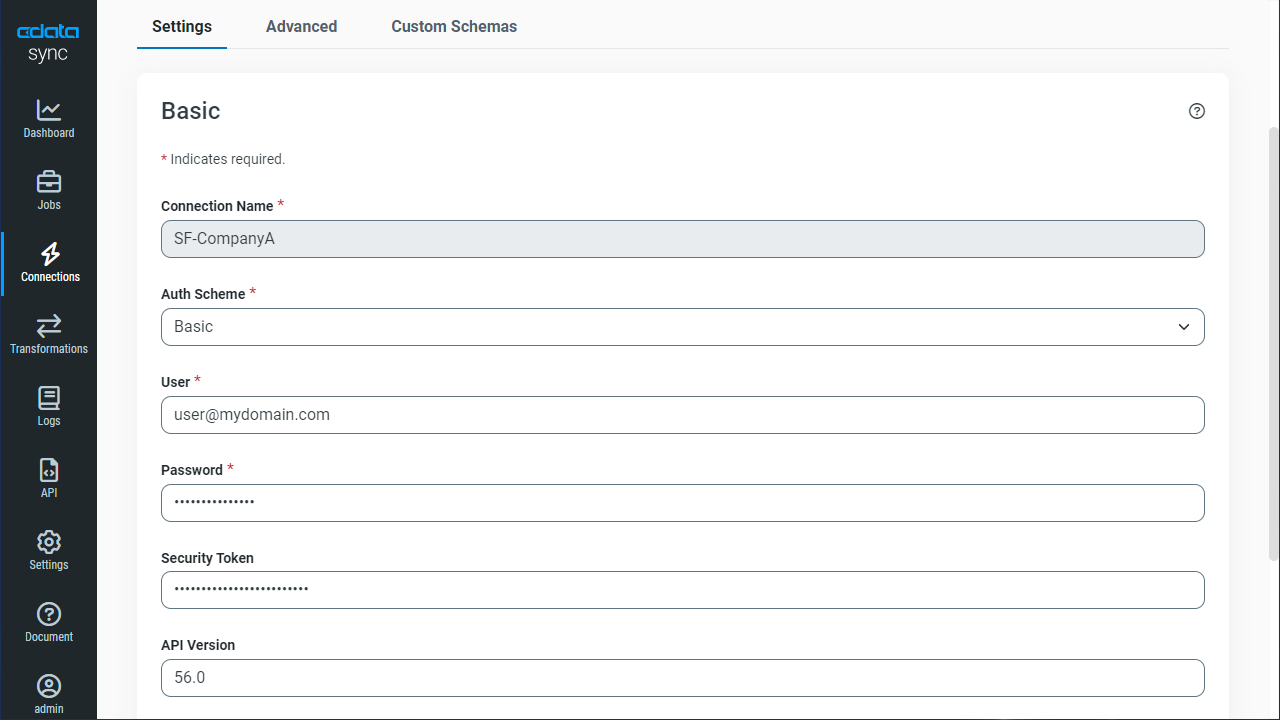
- [接続のテスト]をクリックして、正しく接続できているかをテストします。
- [変更を保存]をクリックします。
それぞれのKafka インスタンスのレプリケーションクエリの設定
Data Sync はレプリケーションをコントロールするSQL クエリを簡単なGUI 操作で設定できます。
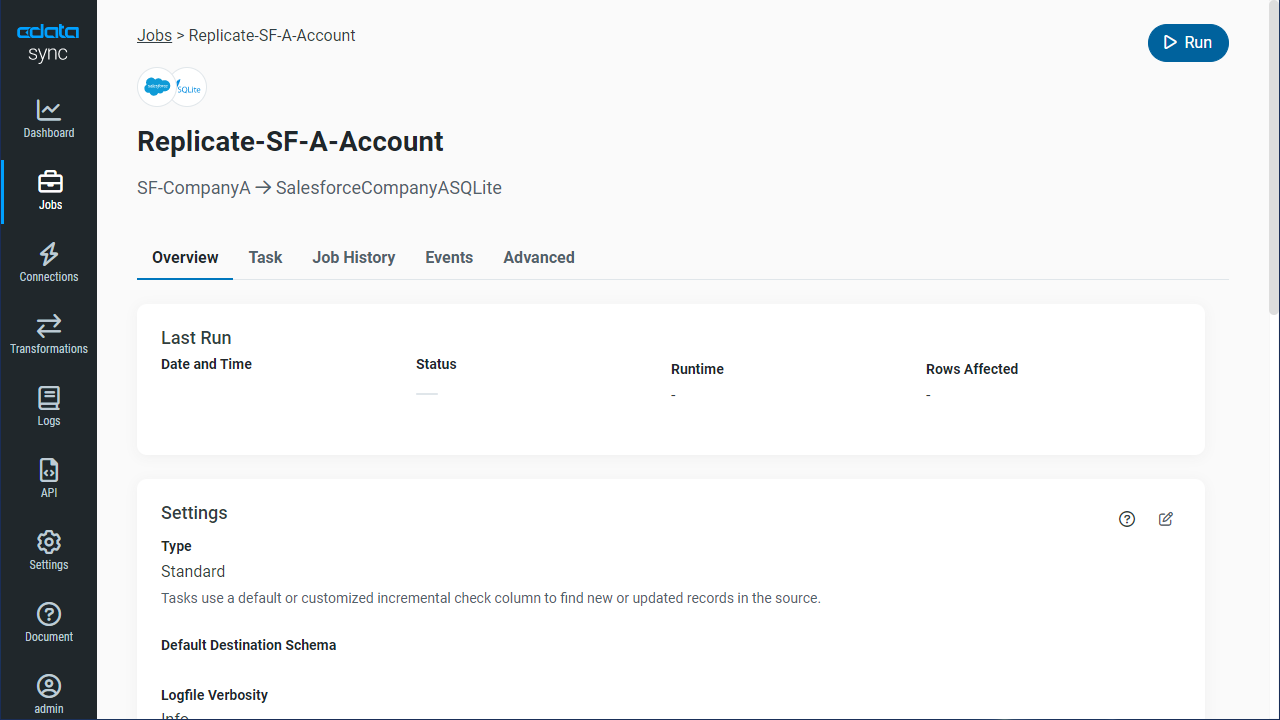
レプリケーションジョブ設定には、[ジョブ]タブに進み、[ジョブを追加]ボタンをクリックします。
次にデータソースおよび同期先をそれぞれドロップダウンから選択します。
テーブル全体をレプリケーションする
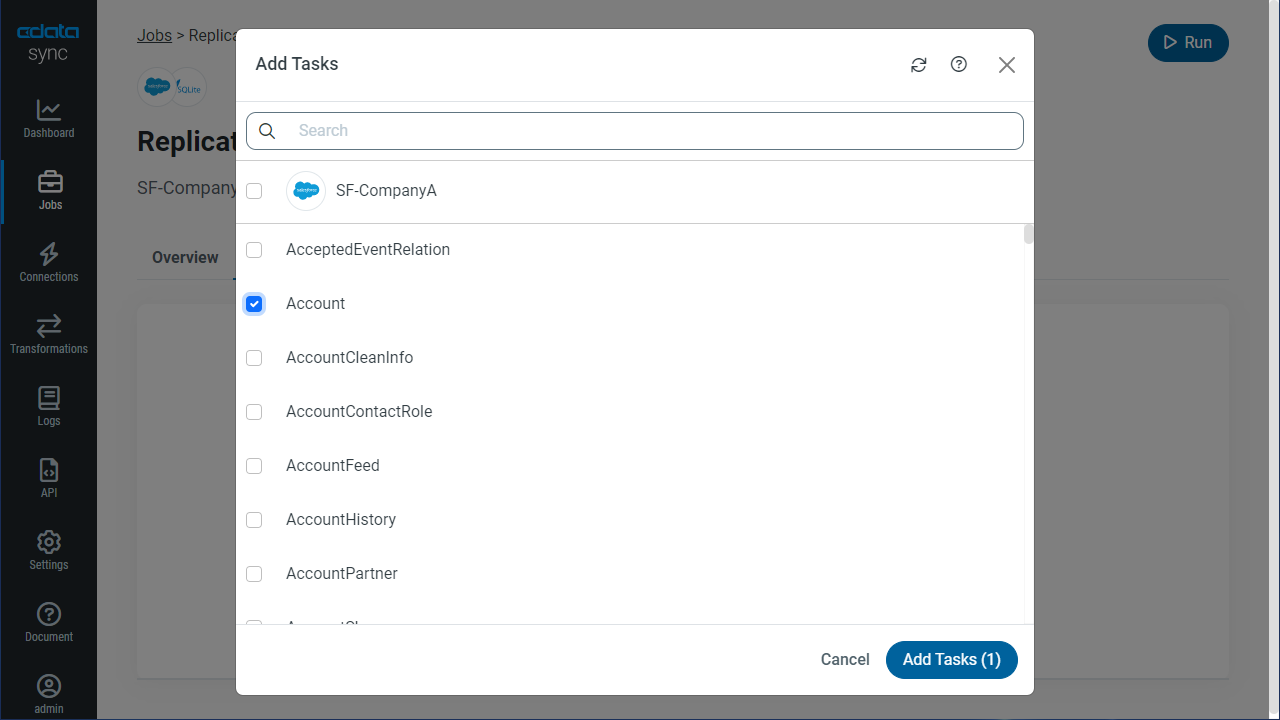
テーブル全体をレプリケーションするには、[テーブル]セクションで[テーブルを追加]をクリックします。表示されたテーブルリストからレプリケーションするテーブルをチェックします。.
テーブルをカスタマイズしてレプリケーションする
SQL クエリを使って、レプリケーションをカスタマイズできます。REPLICATE 構文はデータベースのテーブルにデータをキャッシュし、保存するハイレベルコマンドです。Kafka API がサポートするSELECT クエリを定義することができます。レプリケーションのカスタマイズにはテーブルセクションで[カスタムクエリの追加]をクリックして、クエリステートメントを記述します。
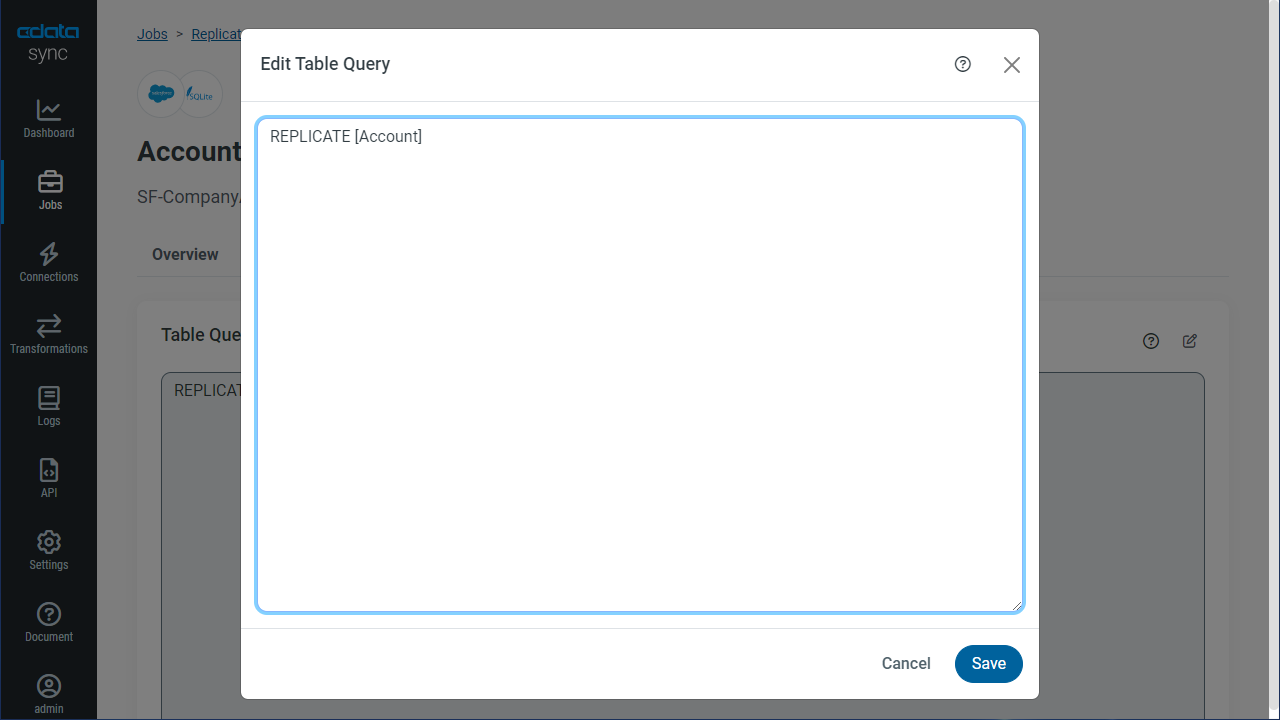
Kafka のデータ のテーブルを差分更新でキャッシュするステートメントは次のとおり:
REPLICATE SampleTable_1;
使用するレプリケーションクエリを含むファイルを指定することで特定のデータベースを更新することが可能です。レプリケーションステートメントをセミコロンで区切ります。次のオプションは一つのデータベースに複数のKafka アカウントのデータを同期する例です:
-
REPLICATE SELECT ステートメントで異なるtable prefix を使用する:
REPLICATE PROD_SampleTable_1 SELECT * FROM SampleTable_1; -
別の方法として、異なるスキーマを使うことも可能です:
REPLICATE PROD.SampleTable_1 SELECT * FROM SampleTable_1;
レプリケーションのスケジュール起動
[スケジュール]セクションでは、レプリケーションジョブの自動起動スケジュール設定が可能です。反復同期間隔は、15分おきから毎月1回までの間で設定が可能です。
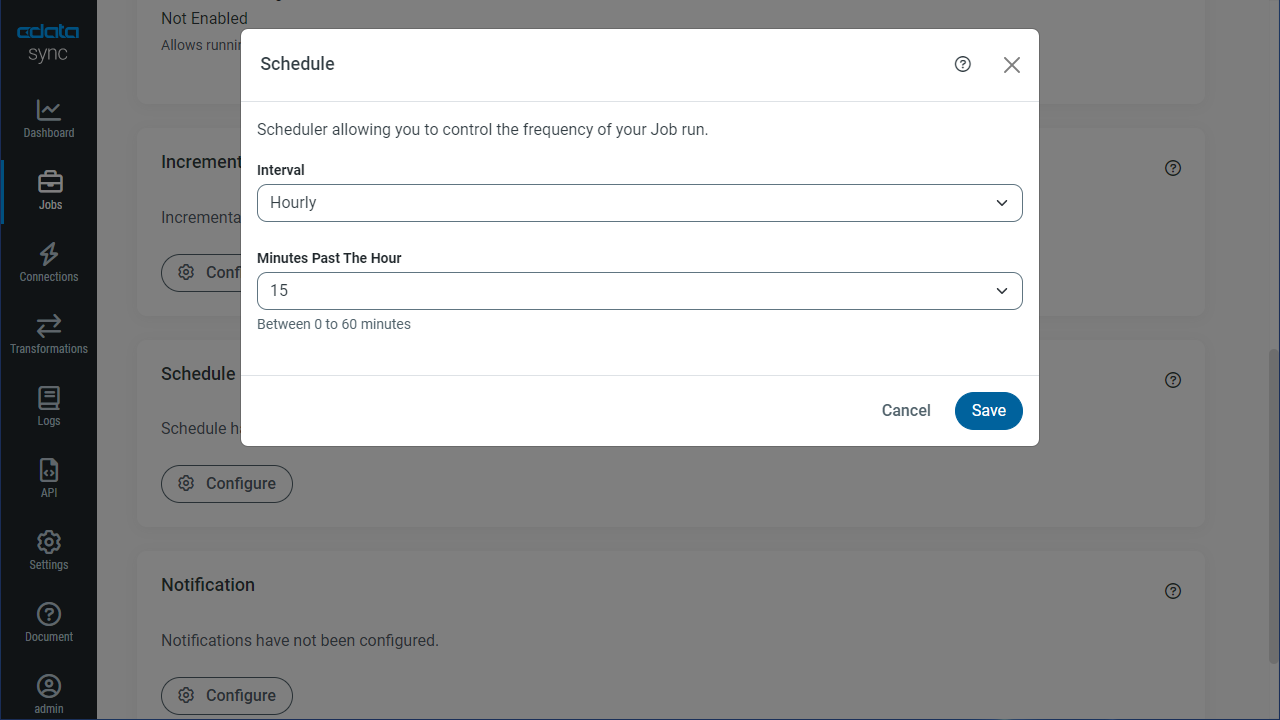
レプリケーションジョブを設定したら、[変更を保存]します。このように複数のKafka アカウントのデータを複製するジョブを作成することができました。